change means opportunity IV: solutions
solutions
i dont know what the solutions are. they will emerge over time. nothing is certain from the onset. Bell, Lee and Zuck couldn’t have fathomed what their innovations would become. I wont pretend to.
But, I want to.
So I’m decided to try by looking at what the history of ads is converging into, what the progress of emerging trends is unlocking, and hopefully adress and find emerging problems that (will) need solutions. to most, especially the incumbents, these solutions will probably look like toys, but don’t be so quick to discard them.
search
with the background pretty established at this point, we can say with confidence that search is being seriously challenged by AI Overviews, and AI (API?) interfaces like chatgpt. from that learning, we calculated earlier that the ~316B in paid search spend (and the ~100B of publisher trickle down economics) is up in the air.
well your first thought may be to try to game the SEO of AI Overviews. Its a good start, and a few others have thought about it.
However, its short sighted and built on shifting sands. Nonetheless, in the rapidly evolving landscape of search, integrating Generative Engine Optimization (GEO) with traditional SEO strategies is crucial for maintaining visibility and brand recognition. so lets break it down and understand exactly what there is to be done in the short term until the dust settles.
Traditional search relies on crawlability, indexability, and rankability. However, AI search introduces retrievability, which determines how effectively AI can access and prioritize your brand’s information. This shift requires SEOs to evolve their strategies to include retrievability, ensuring that core brand information is accessible and prioritized for AI models. Authority, and thus GEO ranking, is built through contextual relevance and consistent brand mentions in other authoritative sources kind of like a modern backlinks system.
| Category | Strategy/Metric | Description |
|---|---|---|
| Retrievability Optimization | Presence | Ensure consistent brand mentions in contexts that shape AI’s training data. |
| Retrievability Optimization | Recognition | Build credibility through relevant mentions and associations with trusted entities. |
| Retrievability Optimization | Accessibility | Structure information for easy retrieval by AI, both on your website and across the web. |
| On-page SEO | Build Topical Authority | Create entity-rich content and structure it into topic clusters. |
| On-page SEO | Reinforce Entity Relationships | Use strategic internal and external linking. |
| On-page SEO | Create Contextually Relevant Content | Align content with evolving user intent and AI-generated responses. |
| On-page SEO | Establish Thought Leadership | Publish unique insights and research to inspire citations. |
| On-page SEO | Structure Content for AI Processing | Use clear formats like FAQs and bullet points. |
| Off-page SEO | Target AI-Trusted Sources | Earn mentions in key industry publications and forums. |
| Off-page SEO | Use Digital PR | Influence conversations that shape AI’s understanding. |
| Off-page SEO | Maintain Consistent Brand Representation | Ensure consistent messaging across all channels. |
| Off-page SEO | Strengthen Knowledge Graph Presence | Optimize Wikipedia and Wikidata entries. |
| Technical SEO | Keep Data Simple | Use straightforward HTML and clear metadata. |
| Technical SEO | Use Structured Data | Implement schema markup to enhance entity recognition. |
| Technical SEO | Prioritize Site Speed | Optimize performance for quick loading. |
| Technical SEO | Help AI Crawl Content | Allow AI crawlers and fix crawl issues. |
| AI-Driven Search Success | Impressions and Visibility | Track presence in AI Overviews and featured snippets. |
| AI-Driven Search Success | Branded Engagement | Monitor branded search volume and direct traffic. |
| AI-Driven Search Success | Real Business Outcomes | Measure leads, conversions, and revenue. |
| AI-Driven Search Success | AI Citations and Mentions | Regularly check brand appearances in AI-generated content. |
Above are a few ways to improve your ranking aggregated from many of the aforementioned startups and SEO guru websites touting the best way to be the winner source reference in AI Overviews.
It may seem like i’m downplaying this, but recall that gaming the algorithm to be in the AIO nets a jump from 18.7% to 27.4% CTR - which is massive. if you’re ok with being a slave to the algorithm, there is a fantastic opportunity to provide these services – at least until meta and google decide to too.
this is the first of many possible solutions. but this relies on the belief that websites are going to continue creating content, and that users will continue to interface via the internet / google search. Yes, you could make a quick buck in the next 2 years as search is restructured, but you can’t build a (longterm/massivve) business on shifting sands, privy to the whims of Google. need i remind you what happened to yelp?
correctness
ok well if the play for GEO isn’t a winner, how about a solution for the liability problem of LLM’s previously detailed propensity to spread fake news and even convince a man into suicide!
The LLM revolution is based on non-deterministic outputs, meaning you can’t predict exactly what the LLM is gonna spit out. old machines like calculators and air conditioning is deterministic: the input configuration will always yield the same output no matter how many times you rerun it. this unpredictability can cause a lot of enterprise harm if the outputs are not aligned to what you would expect. brands are sensitive to their reputation, they’ll drop a celebrity influencer in a heartbeat if it causes them bad PR (cough kanye). as such, many companies are building ‘guardrails’ to avoid having the model ‘hallucinate’.
And when i say many, i mean many:





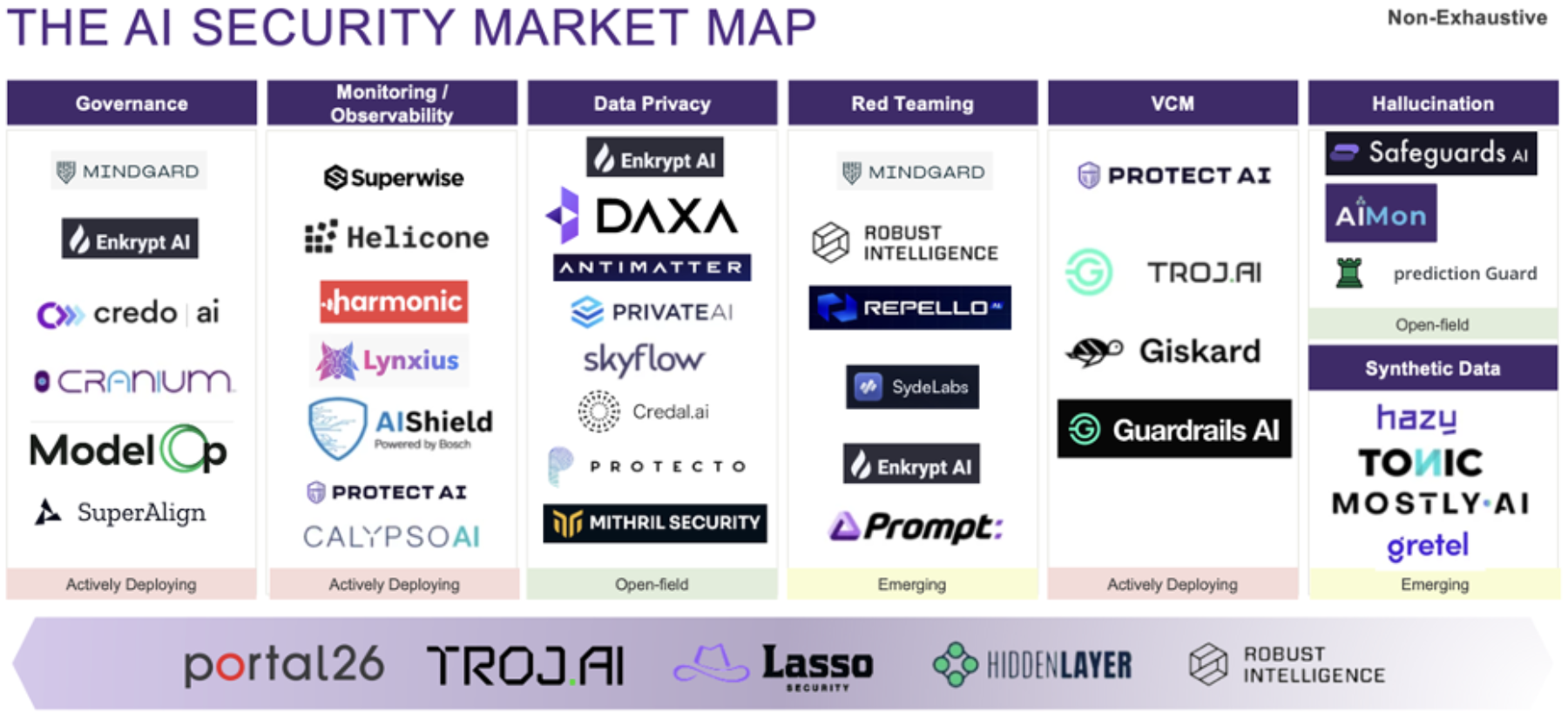
As each of the above companies will tell you, they’ve built a unique and 100x better solution for dealing with enterprise AI security. This can range from RAGs on internal data, to firewall protocols, to a big red button and everything inbetween. some of the brightest stanford dropouts are pursuing this opportunity.
Unfortunately, they too are short sighted and built on the shifting sands of the foundation model companies. Its short sighted because the solution isn’t going to be from band-aiding the outputs of the models in post-editing, but rather, the alignment of the model to its given task during its training - something (at this point) only massive AI research labs can do (and are incentivized to do) due to the size of training jobs. The trends of model correctness are all pointing that way. I tell each of them to read the bitter lesson, but im not sure they’ve read something without sparknotes since middle school. if you want a 2 page detour to reframe your mind to the longterm, its worth the read.
agentic search
The current form of the web is built to support a user experience with the intent that humans are directly consuming the experiences. Agents working on behalf of humans breaks this expectation and have different needs and requirements for a successful Agent Experience (AX)
Source: Netlify’s Sean Roberts
The web was built for humans, by humans, but these days, we’re not the only ones online. Bots account for 49% of internet traffic. CAPTCHA exists because in the early 2000s Yahoo was getting hammered by bots (not the LLM kind) signing up for millions of free email accounts, which were then used to send spam. They enlisted Carnegie Mellon University (yay) computer scientists Luis von Ahn and Manuel Blum to identify and separate humans from bots. Blum was one of those aweseome hippie profs and Luis went on to create duolingo ($DUOL) and made the owl green because his cofounder asked for anything but green.
Of course, bots didn’t stop there – they moved on to scalping tickets, DDOS attacks and juicing engagement on social media posts, which is why captcha and robots.txt became so prevalent. now, with LLMs and proper tooling, the line between human and machine on the web is blurrier than ever.
Recall happens when someone asks their AI Agent to “buy them a red sweater”. 🅱️rowserbase’s headless browser opens up 400 websites and sifts through the clammor (what we would call delightful UX) to get to the PDPs of dozens of retailers and then leverage an agentic MCP payment auth system to purchase the sweater. Theres two aspects to this i want to cover.
AX
Source: king karpathy on x the everything app
While a human might take several minutes to sift through a webpage, an LLM can parse the same information in milliseconds, extracting relevant data points with remarkable accuracy. But the way each processes information is fundamentally different. For us humans, images, layout design, and visual cues are everything. The UX is about what you see, how you feel, what draws your eye, what makes you click. A beautiful image or clever design can make you linger, scroll, or buy. The web, for us, is a visual playground, which is why display ads are (were?) so popular for so long.
For LLMs, all that is basically noise. They don’t care about your hero image, your liquid glass color palette, or your fancy hover states. What theyre looking for structure: JSON, XML, clean HTML, lists — anything that makes the relationships between things explicit. LLMs eat structure for breakfast. The more organized and explicit your data, the easier it is for an LLM to extract, summarize, and act on it.
If your website is unreadable by an LLM, it is just gonna be skipped over. It doesn’t haaave to be neat. Look at Twitter. It’s a firehose of unstructured text, memes, screenshots, and inside jokes—no schema, no markup, just pure chaos. And yet, LLMs and agents are getting freakishly good at parsing even that, pulling out trends, summarizing, and making sense of the mess. The web is becoming machine-readable not because we cleaned it up, but because AI got good at reading our mess.
Still, if you want to be LLM-friendly, structure is your friend. If you want to be human-friendly, make it pretty. If you want to win, do both. In the SEO race, this is how Webflow’s site performance tools, Wix’s speed optimization features, and Shopify’s online store speed reporting gamed the algorithm. the businesses that adapt their agentic web offerings to accommodate these preferences are likely to see improved performance metrics, beyond GEO. Microsoft’s recent NLWeb announcement hits the nail on the head. there is a great opportunity in ‘onlining’ these online services for the agents.
OS
The primary audience of your thing (product, service, library, …) is now an LLM, not a human.
Dwarkesh
Along with 🅱️rowserbase, the leading agents with empowered independence include Anthropic’s computer use, Google’s Project Mariner, openai’s operator and codex, which currerntly just take a screen shot of the page, feed it into the LLM and execute clicks and keyboard presses through Chrome(/ium) and linux’s accessibility mode permissions. This is very skeuomorphic, and toy-like, but as we’ve learned from history: just because it can barely beat pokemon, doesn’t mean we should discount it.
it shouldnt be a surprise that there are many startups creating a standardized AgentOS to go beyond controlling windows os hardware and just reinvent the web/computer process altogether. 5500+ MCP Servers are trying to abstract software for agents to connect to witout any UI. why open a headless browser on a windows machine to ‘manually’ type a query into a google form when i could just request a service from an agent representing the database of the entire indexed internet or all existing humans?
this is where things are getting interesting. this is where we finally attain native ai web products. the way that youtube, instagram and cryptocurrencies were fully native to the internet.
Agent Native UX
The earliest examples of these are browsers being rewritten from the group up with AI ‘searching alongside you’. Dia from The Browser Company, Comet by Perplexity, and Go Live with Gemini in Chrome all hit at this collaborative UX, where you and the LLM often do work simultaneously, “feeding” off of each others work.
For collaborative UX, you’d display granular pieces of work being done by the LLM, like its chain of thought. This falls somewhere on the spectrum between individual tokens and larger, application-specific pieces of work like paragraphs in a text editor or sidebar.
This gets a little complicated for real-time collaboration, like google docs. You’d need an automated way to merge concurrent changes, so when an agent is already running it can handle new user input. some of the best performing computer use algorithms on benchmarks suggest strategies for managing concurrent inputs (sometimes called “double texting”):
- Reject: This is the simplest option. It rejects any follow-up inputs while the current run is active and does not allow “double texting”.
- Enqueue: This relatively simple option continues the first run until it completes. Once the first run is finished, the new input is processed as a separate, subsequent run.
- Interrupt: This option interrupts the current execution but saves all the work done up until that point. It then inserts the user input and continues from there. If you enable this option, your graph should be able to handle weird edge cases that may arise. For example, you could have called a tool but not yet gotten back a result from running that tool. You may need to remove that tool call in order to not have a dangling tool call.
- Rollback: This option interrupts the current execution AND rolls back all work done up until that point, including the original run input. It then sends the new user input in, basically as if it was the original input, discarding the interrupted work.
This is very different than, ambient UX which works in the background. Claude Code, Devin and Cursor agents are being dispatched asynchronously. They’re writing the PRs to the git repo, making a dinner reservation, etc. In an ambient UX, the LLM is continuously doing work in the background while you, the user, focus on something else entirely.
In this scenerio you’d need to have the work done by the LLM summarized or highlight any changes. For example, select the top of the 3 suggested restaurants, or comb through the code changes. Its likely that these ambient agents’ UX will be triggered from an event that happened in some other system, e.g. via a webhook, MCP or monitor alert. With wearables, the AI companion can ‘see what you see’ and proactively suggest tasks to be given (e.g. ‘you’re far from the oven, i can turn it off’).
In any scenerio, one important paradigm available exclusively to software first products is the ability to deploy updates virtually. We’ll get into why this is so valuable in exactly 1 paragraph, but my point here is to think about how agentic UX can be augmented with the versioning nature of software. Great people are thinking about this .
data loop
For the past decade of scaling, we’ve been spoiled by the enormous amount of internet data that was freely available for us to use. This was enough for cracking natural language processing, but not for getting models to become reliable, competent agents. Imagine trying to train GPT-4 on all the text data available in 1980—the data would be nowhere near enough, even if we had the necessary compute.
Mechanize’s post on automating software engineering
We don’t have a large pretraining corpus of multimodal computer use data. Maybe text only training already gives you a great prior on how different UIs work, and what the relationship between different components is. Maybe RL fine tuning is so sample efficient that you don’t need that much data. But I haven’t seen any public evidence which makes me think that these models have suddenly gotten less data hungry, especially in this domain where they’re substantially less practiced.
it’s true that there’s still a massive amount of data to be processed—most notably YouTube’s 20B videos collected over 20 years.
Tokens per video: -
multiplied by YouTube corpus (20B videos)
Total tokens: -
Estimated Storage per video: -
Total Storage: -
You can adjust the numbers above to see how quickly the data adds up. In the last official stat released in May 2019 they claimed 500h of content are uploaded to YT every minute, so that would come out to 27.7̅7̅ minutes per video but extrapolating from the 400h in Feb 2017, assuming a 25% YoY growth, that’d come to ~1000h uploaded per minute, which gives 14.2̅2̅. even then I think it’s a bit high, especially given the recent prevalence of YT Shorts, but even with conservative settings, the scale is staggering. For reference, you can compare this to raw Common Crawl (CC) which has ~100T tokens pre-filter, meaning YT is 2-3 OOM bigger than the internet’s text.
I’m getting beside the point though. We need sufficient data for practical things, not cat videos and gems like these. It is unclear how many indian 4 hour SAP tutorials are enough to teach an agent’s LLM how to navigate their (likely now updated) software. We may need to go beyond the data.
In the case of toy games like chess and go, the breakthroughs didnt come from studying all existing database games, but rather having the AI spend decades playing against itself. This is the likely breakthrough that will unlock the next stage of capabilities.
There are two major types of learning, both in children and in deep learning: (1) imitation learning (watch and repeat, i.e. pretraining, supervised finetuning), and (2) trial-and-error learning (reinforcement learning).Lets go back to the progression of AlphaGo in its fantastic film, it can either (1) learn by imitating expert players, (2) or use reinforcement learning to win the game. Almost every shocking result in deep learning—the real magic—comes from the second type. 2 is significantly significantly more powerful. 2 is what surprises you. 2 is when the paddle in Breakout learns to hit the ball behind the blocks, when AlphaGo beats Lee Sedol on move 37, or when models like DeepSeek (or o1, etc.) discover that it helps to re-evaluate assumptions, backtrack, or try something else. 2 is the “aha moment”.
These thoughts are emergent (!!) this is actually seriously incredible, impressive and new (as in publicly available and documented etc.). The model could never learn this with 1 (by imitation), because the cognition of the model and the cognition of the human labeler is different. The human would never know to correctly annotate these kinds of solving strategies and what they should even look like. They have to be discovered during reinforcement learning as empirically and statistically useful towards a final outcome. The same way we did in our childhood.
Unfortunately, we cant just drop an ai in a corn field and have it become cognizant. there are some ground rules, much like physics and the aux on a road trip. You’ll need to tell it the limits of whats permissable (move bishop diagonally), and give a win condition (checkmate). As Gwern elegantly explains, “any internal planning system needs to be grounded in some kind of outer loss function - a ground truth measure of success”. In a market economy, this comes from profits and losses”. In code generation, the function produces the expected output or it doesnt. You can extrapolate for excel, SCADA or Ironclad.
If you can create a feedback loop where a model can autonomously learn a model of the world (jargon ‘world model’) that its allowed to play in, the ai may discover a completely new breakthrough. this is the bet of protein folding research en route to cure cancer. the catch is how do you set up that sandbox? it’s pretty obvious in toy games and outcome driven workflows. alignment researchers spend all day thinking about this w.r.t AGI, where its much less obvious. but i dont want to think about AGI (heh), i want to solve real problems in the real world.
The best companies of the 21st century have been those which tightened the feedback loop as taut as possible. SpaceX, Linear and Vercel have outpaced their incumbents by ‘shipping’ incessantly. The best way to improve is to study feedback on your best attempt, those that do this more, improve faster – even if just 1% a day. AI’s self-play takes this to the next level. it crunches feedback at the speed of data.
the problem is that the sandboxes for many workflows dont yet exist. there is a massive opportunity in creating environments where we can drop the AI off at daycare and come back to a PhD. for example, by abstracting into software autonomously controllable wet lab equipment, an AI could pick up a pipette from point A, move it to point B, and squeeze, all while monitoring the progress with sensors, cameras and reward schedules. same applies to laundry folding robots. I’m particularly interested in legacy softwares, Marc Benioff too. Computer use agents seem capable now, unfortuantely RPA may have rode this wave 10 years too early. Modern CUA companies are all looking in the wrong direction.
ads
ah, ads. the economic covenant of the internet. the lifeblood of meta and google. our history goes back so far. will it continue in the age of ai?
there’s only a few places to insert ads with the agentic web:
1. in the display interface that the user will interact with (e.g. NexAD banners, Bing, Perplexity, etc)
2. in the query understanding (e.g. request with branded keyword)
3. in the searched posts (e.g. GEO)
4. in the pre-training data (e.g. poisoning)
5. in the output (e.g. exclusively DC superhero bedtime story)
I’m going to make a pretty uncontroversial claim that the big AI research labs will own the decision for option 1, 4, and 5. there may be a play to create the DoubleClick, TradeDesk, Criteo ‘auction house’ for agentic ad bidding, but i’d assume meta, google and friends will learn the lesson from early internet economics and build out their own platform . its too important to their business model not to build inhouse. Option 3 is a cat and mouse game with the algorithm and alignment teams, and not exactly the most ethical pursuit. So what other independent players are there?
WPP, Omnicom and Publicis are massive companies built on the history of ads. Their business model comes from taking a fee % of the ad spend, meaning if Proctor & Gamble allocates $10M to an instagram campaign with the typical 20/80 breakdown, a team at WPP will allocate ~20% to the production of creatives (e.g. video editing, celebrity NIL, copywriting) and ~80% on boosting the campaign via Facebook’s Advantage+ or Google’s Performance Max (PMax) platforms. Thus with their 3% digital ad commission fee they would pocket 10M x 0.8 x 0.03 = 240k.
This wont continue. At least no where close to the present levels. The direction is doomed, and Ben Thompson saw this back in Jan 2023, only a month after chatgpt’s launch.
For now it will be interesting to see how Meta’s advertising tools develop: the entire process of both generating and A/B testing copy and images can be done by AI, and no company is better than Meta at making these sort of capabilities available at scale. Keep in mind that Meta’s advertising is primarily about the top of the funnel: the goal is to catch consumers’ eyes for a product or service or app they did not know previously existed; this means that there will be a lot of misses — the vast majority of ads do not convert — but that also means there is a lot of latitude for experimentation and iteration. This seems very well suited to AI: yes, generation may have marginal costs, but those marginal costs are drastically lower than a human.
form
fast forward 2 years and its may 2025, where Zuck explains his planned ad tool developments.
We’ll use AI to make it so that the ads business goes a lot better. Improve recommendations, make it so that any business that basically wants to achieve some business outcome can just come to us, not have to produce any content, not have to know anything about their customers. Can just say, “Here’s the business outcome that I want, here’s what I’m willing to pay, I’m going to connect you to my bank account, I will pay you for as many business outcomes as you can achieve”.
It is basically like the ultimate business agent, and if you think about the pieces of advertising, there’s content creation, the creative, there’s the targeting, and there’s the measurement and probably the first pieces that we started building were the measurement to basically make it so that we can effectively have a business that’s organized around when we’re delivering results for people instead of just showing them impressions. And then, we start off with basic targeting. Over the last 5 to 10 years, we’ve basically gotten to the point where we effectively discourage businesses from trying to limit the targeting. It used to be that a business would come to us and say like, “Okay, I really want to reach women aged 18 to 24 in this place”, and we’re like, “Okay. Look, you can suggest to us…” sure, But I promise you, we’ll find more people at a cheaper rate. If they really want to limit it, we have that as an option. But basically, we believe at this point that we are just better at finding the people who are going to resonate with your product than you are. And so, there’s that piece.
But there’s still the creative piece, which is basically businesses come to us and they have a sense of what their message is or what their video is or their image, and that’s pretty hard to produce and I think we’re pretty close. And the more they produce, the better. Because then, you can test it, see what works. Well, what if you could just produce an infinite number? Yeah, or we just make it for them. I mean, obviously, it’ll always be the case that they can come with a suggestion or here’s the creative that they want, especially if they really want to dial it in. But in general, we’re going to get to a point where you’re a business, you come to us, you tell us what your objective is, you connect to your bank account, you don’t need any creative, you don’t need any targeting demographic, you don’t need any measurement, except to be able to read the results that we spit out. I think that’s going to be huge, I think it is a redefinition of the category of advertising.
So if you think about what percent of GDP is advertising today, I would expect that that percent will grow. Because today, advertising is sort of constrained to like, “All right, I’m buying a billboard or a commercial…” Right. I think it was always either 1% or 2%, but digital advertising has already increased that. It has grown, but I wouldn’t be surprised if it grew by a very meaningful amount. [aggregated into meta’s pocket]
for whatever reason i feel like you skipped the above quotes. go back and reread it. he basically outlines the plan better than i can restate it.
this is the $416B opportunity.
At stripe sessions, Zuckerberg posited that creative ad agencies could continue to exist once Meta deploys this AI, but small businesses wouldn’t shell out thousands. This is deeply disruptive to the WPPs of the world, and complementary to the D2C robustness (vs shelf space monopolization) aforementioned, since now Meta can simply handle all of their advertising operations. Meta’s tools can find interested users better than human marketers can. The next logical step, he says, is trying to apply this data-driven optimization to the creative side. “We’re gonna be able to come up with, like, 4,000 different versions of your creative and just test them and figure out which one works best,” said Zuckerberg. Itll be so much easier to embrace the black box, punch the monkey, offload the brand to the sloptimization algorithms. This is disastrous news for WPP and friends, where the whole industry is built on creating ads and evaluating their effectiveness. Some startups ((creatify, icon)) are trying to wedge in before Meta’s product drops, but its futile to think they could do it better with a much smaller distribution (aka feedback loop) and capital resources. Much like high quality art, the best photo / ad / post is the one you stop at to pay attention. ai ads should also train on hotjar data.
WPP isnt going down without a fight tho. Daniel Hulme, the holdco’s chief AI officer, claims they’ve rolled out more than 28,000 AI agents to handle media planning, content generation, analytics and optimization. For now, their capabilities are limited to helping human employees without agency to full autonomy to access systems and data sources for ‘safety reasons’. They’re deciding to take on exactly what Meta plans to do (see above quotes) as well as the infrastructure to keep tens of thousands of AI agents from drifting out of line - reinventing the wheel just like companies like Sierra and the earlier carousel of companies setting up the same guardrails.
Later, its stated that WPP’s bet is that “the real competitive edge won’t come from using AI so much as it will come from responsibly managing, integrating and scaling it before rivals catch up. The promise of agentic AI involves coordinating numerous AI systems, orchestrating multiple intelligent systems to connect agents across teams, clients and platforms. Without it, the risk of conflicting behavior, redundancy, or outright failure goes up fast.” This echoes the organizational level agent coordination we talked about earlier. But this isn’t their fight to fight. its a bad bet.
I also got the ick that he’s also using the same platform to engineer an app called “Moral Me,” which crowdsources moral dilemmas from users to help train AI agents on a wider range of human moral values. ‘As people hand more decision-making to personal AI, marketers and technologists will need to learn how to influence the agents themselves’. This is cool research, but im not sure what the tie is back to WPP.? Is it that if you influence the agent, not the audience, they will be more likely to purchase or promote the product? Its a bit far from the kind of stuff a public company should be pursuing when the house is on fire. But maybe drastic times call for drastic measures.
I would applaud them if they go all in on this – influencing AI agents, not the crowdsourced trolley problems – though it is privy to the whims of the algorithm. Unfortunately, I’d argue even this attempt would be in vain, too. the foundation model companies will get better at understanding the user’s shopping intent, and to try to persuade these robots into a diversion will get stamped out quickly. Agents don’t care for christmas themed repackaging. There is an opportunity, though, in adjusting the ad copy to match the agent expectations (price, color, delivery time, etc), the way that meta plans to do with human A/B testing. Representing a big enough of catalogue, a company like amazon or WPP could make deals with perplexity shopping that still siphon consumer surpluses in the aggregate.
Keeping one foot in the future, with always-on wearables, you can go beyond personalization. there are opportunites to build systems that can anticipate intent. That’s the next frontier: agents that know what someone is about to want and marketers who can respond in real-time with a custom enticing offer. Flip the script: the users propose and the brand accepts, as opposed to the current brand product blasts that users evaluate. A good ad in the future can pull from:
- user data / history
- context from search page / product
- personalization of tone / format
- intent understanding
- ???
this is an even bigger $XXX(X?)B opportunity.
Attribution
The other cornerstone of the internet ad industry is the the success of attribution, predominantly through the use of tracking tech like pixels. These 1x1 transparent pixels track users as they go through the journey of ad impression to conversion. Recall the AIDA funnel we discussed earlier, by trackin the attribution of an ad successfully funneling the user to the next layer, companies can refine their campaign specific approaches based on specific actions like abandoned shopping carts or previously viewed products, significantly boosting conversion rates and overall marketing effectiveness. The shift to data-driven attribution models has enabled brands with the tightest feedback loops to offer highly targeted advertising solutions, which in turn drives significant revenue growth and market dominance.
But when the agents are shopping for us, how will we attribute information and actions correctly? Beyond just ads, attribution is crucial for accountability, transparency, and trust. There are a few startups doing agentic auth, another one on the human context associations, and Cloudfare has a FANTASTIC initiative to force scraping bots to pay a toll per visit (remember the bot crawling from earlier chart ), but lets primarly focus on ad attribution and not the broader protocols for the future agentic commerce.
Nowadays, the pixel is less common. Conversion APIs (CAPIs) are all the rage, every major platform has one: linkedin, x, reddit, amazon, pinterest, snapchat, tiktok and of course google and meta. These are not only more accurate, but ‘privacy preserving’ since instead of using 3rd party cookies (which can be sold/shared), CAPIs are event driven server side api calls. They mask it behind GDPR and CCPA (California Consumer Privacy Act) compliant greenwashing but its really just a ploy to harvest and upcharge for 1st party data.
This is all very human-centric, as we are the ones navigating from one website to the other. You can try to have AI skeumorphically replicate the human workflow by creating an agentic browser or computer use virtual machine that navigates the web, but this bound to die to the bitter lesson. In the world of agentic commerce with an ‘onlined’ catalogue, there will be no browser with a trail of cookie crumbs. It’s (maybe?) a world of MCP tools, API calls and retrieval indexices. In this world, tracing the bot’s steps is much easier – its just metadata in the GET requests. Some (independent) institutions will build this and agree on a universal nomaclature, but technical complexity wise, trivial. The harder part will be attributing actions initiated by a user or agent’s chain-of-thought.
segmentation
But in the ad industry, the pixel isn’t just for tracking behavior, its for understanding behavior. Categorizing the actions of the user who keeps coming back to the electrolyte supplement website every month into a group with other ‘pixels’ who demonstrate the same behavior, for example.
Given a device ID, cookies, context, and 3rd-party DMP enrichment, Demand-Side Platforms (DSPs) like The Trade Desk, Google DV360, and Amazon DSP can identify who you are with astonishing accuracy. This capability persists even when data is ostensibly anonymized, as research consistently demonstrates the ease of re-identifying individuals. For instance, studies have shown that as few as four spatio-temporal points can uniquely identify 95% of individuals in a mobile dataset. Furthermore, combining just a 5-digit ZIP code, birth date, and gender can uniquely identify 87% of the U.S. population, highlighting the fragility of anonymization in practice, as famously demonstrated with the re-identification of users in the Netflix Prize dataset. This is all table stakes for most credit card and sign-up forms.
From there, they’ll label you with into segmented groups, often fabricated from partnerships with social listening companies so that they can match it to the DSP ad catalogue taxonomy.
An example from The Trade Desk representing a user:
POST /v3/audience
{
"user": {
"id": "user-abc123",
"segment_id": "demo-f25-34",
"criteria": { "gender": "female", "age_range": "25-34" }
"segments": [
{ "id": "INT:Female_25_34", "type": "Demographic" },
{ "id": "INT:Fitness_Junkie", "type": "Interest" },
{ "id": "INT:Budget_Shopper", "type": "Interest" },
{ "id": "PUR:Recent_Tech_Buyer", "type": "Behavioral" },
{ "id": "LAL:HighSpender_Lookalike", "type": "Behavioral" },
{ "id": "PUR:Recent_Supplement_Buyer", "type": "Behavioral" },
{ "id": "INT:Likely_Buyer_Hydration_Brands", "type": "Intent-based" }
]
},
"IncludedDataGroupIds": [
"aud1234", // women
"aud2345" // 25-34
],
"ExcludedDataGroupIds": ["aud3456" // low value],
"device": { "type": "mobile", "os": "iOS" },
"site": { "domain": "healthline.com" },
"page": { "keywords": ["hydration", "electrolyte"] }
}
and representing an ad Campaign:
{
"AdvertiserId": "adv123",
"AudienceName": "24-35 Electrolytes Minus Low Value",
"Description": "Users in the age range 24-35 who are interested in electrolytes and are not low-value users.",
"CampaignId":"electrolyte_summer_2025",
"AdGroupName":"Strategy 1",
"AdGroupCategory":{"CategoryId":8311},
"PredictiveClearingEnabled":true,
"FunnelLocation": "Awareness",
"RTBAttributes":{
"ROIGoal":{
"CPAInAdvertiserCurrency":{
"Amount":0.2,
"CurrencyCode":"USD"
}
},
"BaseBidCPM": { "Amount": 1.0, "CurrencyCode": "USD" },
"MaxBidCPM": { "Amount": 5.0, "CurrencyCode": "USD" },
"CreativeIds": ["CREATIVE_ID_URL_1", "CREATIVE_ID_URL_2"]
},
"AssociatedBidLists": []
"AudienceTargeting": {
"IncludedDataGroupIds": ["aud1234","aud5678"],
"ExcludedDataGroupIds": ["aud9012"],
"CrossDeviceVendorListForAudience": [
{
"CrossDeviceVendorId": 11,
"CrossDeviceVendorName": "Identity Alliance"
}
]
}
}
source: API docs for a user, and ad campaign
what will change in the age of ai? well, due to the forgoing of browsers, a lot will have to be rebuilt. there is no scaffolding needed around cookies - they wont exist. the repository of banner images with their height x width specifications is irrelevant to the agent’s experience of evaluating worthiness.
however, rather than doing a lookup by keywords, there is a fabulous opportunity to match ads and user requests in the space of embeddings. given the richness of agentic knowledge, you can go beyond the limited keywords and into ‘intentions’.
intentions
this is probably the hardest part of the the new agentic commerce stack. understanding the intentions of the users. with google and amazon, users would input a couple keywords and then (to the best that they can), the platform would display information relevant to the user’s request. from then on, a human would slog through the links and products, refining and updating the search bar requests based on their perusing. often, in the process of navigating the web, we discover information to better inform our decision making that we couldn’t’ve known a priori.
agents will need to do all this on the user’s behalf. they’ll need to make assumptions about the information users don’t yet know. its very hard to do this well. it depends on the request: for basic, cheap, diverse products where the downside of a bad decision isnt disastarous (e.g. a toothbrush, light bulb, toilet paper) not much information is needed beyond price and urgency. but for more important purchases (e.g. a car, banking software, orthodontist) much more information is needed.
luckily, agents are uniquely capable of injesting, discovering and clarifying information. the LLM interface companies have a rare opportunity to do things right, and with a potent new methodology as well. agents can not only draw on the immediate conversation history as context, but can go a mile beyond traditional passive monitoring tools and actively ask clarifying questions about search parameters, a la deep research. the very same parameters that could be used to index through the DSP catalogue, or web product/service catalogue.
from the user’s feedback on the agent’s suggestions, saved preferences and behavior can be commited to memory. memory is probably one of the most important paradigm shifts in (ad) personalization. memory is stored (increasingly) near-perfect information retrieval, at a breadth and depth humans gawk at.
memory allows for learned purchasing habits, tailored to the individual. this is a revolution in the ad industry because you can now explicitly understand purchase criterium. until agents, this knowledge was implicit, exclusive to the impenetrable mind of the human intuition. we would adjust web UX and ad copies according to hotjar session data, abandoned cart rates and CTR KPIs. the quality of the user journey is so now so much richer: “Monday: gmail says they bought a bulk marathon ticket and later asked about electrolyte drinks → Tuesday: inquired about aluminum-free brands → Thursday: requested a specific product link.”
now an agent can go to a brand/aggregaator/SKU store agentic representation and say the quiet stuff out loud:
{
"user_request": "Agent, we need bulk, high-quality electrolyte drinks for our household. Last time, 'HydraLite' was too salty, and 'PowerFuel' was too sweet and artificial. I need something balanced: not overly sweet or salty, with clean, natural ingredients, low sugar, no artificial dyes, and no unnecessary additives. Prioritize plant-based or sustainably sourced options, allergen-free, non-GMO, gluten-free, and with clear electrolyte content. Look for NSF/Sports-certified or B Corp brands. I want good value in the mid-to-premium range, available quickly, or in stock at Target/Costco. Consider our family's sensitive stomachs and moderate storage space. No sampler packs, just reliable bulk or multipacks with a flexible return policy. Fast-mix powders or shelf-stable bottles are both fine, but must be easy to reseal and store. What's your best recommendation?",
"parsed_parameters": {
"item_type": "electrolyte drink",
"immediate_need": true,
"quantity_preference": "bulk",
"duration_target_months": {
"min": 1,
"max": 2
},
"flavor_profile": {
"avoid": ["overly sweet", "overly salty", "artificial"],
"preferred": ["balanced", "mild", "natural"]
},
"sweetener_preference": {
"avoid": ["high sugar", "artificial sweeteners"],
"preferred": ["natural", "low sugar", "no added sugar"]
},
"ingredient_preference": [
"plant-based",
"sustainably sourced",
"non-GMO"
],
"sodium_content_range_mg": {
"min": 100,
"max": 300
},
"potassium_content_min_mg": 150,
"other_electrolytes": ["magnesium", "calcium"],
"eco_friendly_priority": "high",
"value_for_money": "high",
"brand_history": {
"liked_quality_reference": ["Liquid I.V.", "LMNT"],
"disliked_specific_brands": ["HydraLite", "PowerFuel"],
"disliked_attributes": ["too sweet", "artificial flavor", "too salty", "gut upset", "chalky texture"]
},
"previous_purchase_feedback": [
{
"brand": "HydraLite",
"feedback": "too salty and caused mild stomach upset, didn’t dissolve well",
"sentiment": "negative",
"attributes_failed": ["flavor", "digestibility", "texture"]
},
{
"brand": "PowerFuel",
"feedback": "flavor was artificial and too sweet, didn’t feel hydrating",
"sentiment": "negative",
"attributes_failed": ["flavor", "naturalness"]
}
],
"chat_history_context": "User prefers bulk wellness/household supplies and chooses products that suit sensitive digestion and avoid synthetic chemicals. They’ve previously chosen fragrance-free, dye-free options for detergents and snacks.",
"memory_recall": "Agent recalls user's frustration with single-serve trial sizes and aversion to chemical additives. User values easy mixing, clean taste, and packaging that reduces plastic waste.",
"packaging_type": ["plastic-free", "recyclable", "resealable"],
"serving_format_preference": ["powder", "ready-to-drink bottle"],
"flavoring": ["natural flavors only"],
"dye_free": true,
"artificial_additives_free": true,
"certifications_desired": ["NSF Certified", "B Corp", "USDA Organic"],
"brand_ethical_sourcing": "preferred",
"price_range": "mid-to-premium",
"delivery_speed_preference": "quick",
"subscription_option_desired": true,
"mixability": "fast/easy",
"gut_friendly": true,
"biodegradability_priority": "high",
"color_preference": "clear or pale",
"core_size_preference": "standard bottle/container",
"availability_preference": "widely available",
"user_group_focus": "family",
"storage_space_constraint": "moderate",
"trial_pack_interest": false,
"return_policy_importance": "flexible",
"user_location": {
"city": "New York",
"state": "NY",
"zip_code": "10001",
"country": "USA"
},
"delivery_options_preferred": ["standard_shipping", "express_shipping", "in_store_pickup"],
"preferred_retailers": ["Target", "Costco", "Amazon", "Walmart"],
"payment_methods_preferred": ["credit_card", "paypal", "apple_pay"],
"budget_max_per_serving_usd": 1.00,
"household_size": 4,
"urgency_level": "high",
"packaging_material_preference": ["cardboard_box", "paper_tube", "recyclable pouch"],
"brand_loyalty_level": "open_to_new",
"customer_review_rating_min": 4.0,
"shipping_cost_tolerance_usd": 5.0,
"discount_preference": ["coupons", "bulk_discounts", "loyalty_programs"],
"return_window_min_days": 30,
"product_dimensions_tolerance": {
"container_width": "standard",
"max_height_cm": 30
},
"allergen_concerns": ["soy", "dairy", "gluten", "tree nuts"],
"customer_service_preference": ["responsive_support", "easy_returns"],
"purchase_frequency_target": "monthly",
"user_demographics": {
"gender": "female",
"age_group": "35-44",
"income_bracket": "middle_to_high"
},
"environmental_certifications_strictness": "strict",
"product_weight_tolerance_kg": 5,
"packaging_design_preference": "minimalist",
"customer_support_channels": ["chat", "email", "phone"],
"cot_further_action_needed": [
"recommend specific brands/products meeting all criteria",
"check online availability with quick delivery options",
"check local store availability (Target, Costco)"
]
}
}
google, amazon and meta dream of having this level of purchase intent clarity.
memory and conversation context are the key unlocks here. they offer unprecedented granularity. in spitballing this with jeff, he told me how it reminded him of his executive assistant. the first few times, she got the coffee orders slightly off. jeff corrected her, and over time, she intuited his intuition. this process also applied to what hotels to book, window or aisle seats, days to schedule lunch blocks, emails to bring to his attention and everything in between. she used her representation of his preferences + extrapolation of his thinking for new scenaries + memory of previous similar scenerios to make purchases on his behalf.
a friend has tried to gain traction with a memory MCP server, but ultimately it will be the LLM interface (chat.com, character.ai, siri etc) that has the memory moat. they’ll need a way to translate the query to params, an opportunity that could be done both in house or externally. but if you can translate a LLM query + its CoT + memory into the parameters of a DSP, you’ve got AI native ads. do this accross several LLM interfaces and you’re an AI native SSP.
social listening
the best way to understand someone’s intentions is to listen. there is an entire industry within advertising and product R&D built on this premise.
Major companies Brandwatch, Sprinklr and Talkwalker will crawl all of twitter, reddit,
youtube, instagram etc to identify any mention of your brand, your competitor’s brands, their products, keywords associated with the products, user metadata, call center transcripts and sooo much more. These companies typically provide reports that include:
- Sentiment analysis: Understanding the emotional tone of discussions.
- Emerging themes: Identifying new consumer concerns, questions, and preferences.
- Topic clustering: Grouping related discussions (e.g., “sustainability,” “price complaints”).
- Influencer identification: Pinpointing key voices in the conversation.
Beyond these initial reports, partnering with aggregator and verifier companies like Nielsen can add a deeper layer of value. For instance, instead of merely stating “100k tweets about Gatorade,” Nielsen might provide a more nuanced analysis: “4.8% of these mentions were from health-conscious females 25–34 in urban areas, and 17% expressed direct purchase intent tied to a workout”. Their enhancements typically include:
- Audience panels + device graph: Linking social behavior to known demographic panels.
- Psychographic/behavioral insights: Incorporating survey-based or behavioral inferences (e.g., identifying an “eco-conscious millennial female”).
- Cross-platform stitching: Understanding the same individual’s behavior across various platforms like TikTok, CTV, retailers and credit card data.
- Taxonomy enrichment: Labeling the intent and context of mentions (e.g., purchase intent, complaint, brand advocacy).
LLM interface companies have yet to build out this crucial portion of the advertising (/R&D) stack. I respect and appreciate that they haven’t sold us out for a quick buck. There may be a way to do this well. lets just look back at how it was done in the past real quick.
for a while, the major social media platforms all had apis. the social listening companies would draw directly from those to gather information about followers, friend graphs, hashtags and early 2010s stuff. these all got walled off, and now the walled gardens can either offer PII compliant clean rooms, or play the cat and mouse game to get the listener bots off their platforms.
Pre-2018, many platforms allowed pixel-based tracking, broad user-level data sharing, and “lookalike”/”custom audience” exports with relatively little restriction. Post-GDPR/CCPA (2018+), stricter privacy laws, cookie deprecation, and public pressure led platforms to clamp down on data sharing. 2018-2022 saw clean rooms emerge as a compromise, letting brands measure and optimize inside the platform without ever getting raw user data. 2023+ brought robust clean room products where data never leaves walled gardens, PII is never exposed, and all access is logged and rate-limited.
The clean rooms are a way for brands to upload their set of pixel/first-party ID hashes and recieve cryptographic annonymized hueristics. Disney, NBCUniversal and Google Ads Data Hub etc all follow similar patterns: advertisers can query aggregated results and campaign metrics, but cannot access individual user data, export row-level information, or remove data from the platform’s infrastructure. Common features include minimum audience thresholds (typically 50-1000 users), differential privacy techniques, SQL-like query interfaces with heavy restrictions, partnership requirements with data clean room networks (LiveRamp, InfoSum), and use cases spanning attribution modeling, incrementality testing, audience overlap analysis, and cross-platform measurement. All require enterprise grade privacy agreements, compliance training, and are primarily accessible only to major brands, agency holding companies (WPP, Publicis, Omnicom, Dentsu, IPG), and subcontracted analytics partners. Unfortunately not available to small businesses, the general public, or most third parties.
its a big schlep to set them up, but if done right, clean rooms are gold mines all while preserving privacy for the end user. its the true ‘win-win-win’ promise of the ad industry. no harvesting, exploitation or irrelevant content.
nonetheless, a social listening tool should at the very least set up a public intent registry displays user demands in real-time (“Need last-minute flights under $250”). Brands get transparent, anonymized signals on current demand and respond rapidly with highly targeted, competitive offerings. also, its unclear how much qualitative improvement this will impact the insights, but voice mode adds a new dimension of behavioral analysis that companies could do to understand ‘sentiment’.
onlining
we started talking about this as an opportunity in AX but lets flesh it out a bit more, especially w.r.t ads. Recall that in world of agentic (web) product/service browsing, we want to optimize for the Agent Experience (AX), much like we did for User Experiences (UX). In this world, a display ad is noise. In this world, fancy CSS and gradient shaders are noise. an agent doesnt care the ‘feel’ of the website. in fact it would prefer if there was no website. just facts. and faCtS dOnT cARE aBouT yOuR fEelInGs.
rethinking from first principles, how can you represent the catalogue of products/services in AX?
this is an open question, and tbh arm-chair thinking about how this would look is dumb. it will be a byproduct of usage, success rate and many minds. but my first jab would be to represent the catalogue in as much JSON/XML detail as possible.
currently, PDPs follow a pretty standard format on amazon, zara, etc. its a title, image carousel, price, quick description and then ingredient/specifics. with LLMs, the more context the better, and if you can expound on every aspect of the PDP, you give more surface area for a matching algorithm to pair a user query to the SKU. beyond the ‘basics’, add color by hexcode, add every review(er’s profile data), chemical compounds, awards’ criterium, similar products etc. this is a NLP parsing problem, but definitely solvable.
I would partner with aggregators like Home Depot, Best Buy, Steam, etc and use their distribution to gain traction before moving to the individual brands. the best positioned is shopify, id be very surprised if they’re not already working on this.
negotiation
taking an alternative swing at this industry, id want to see if you could set up a class action bulk orders system. this is where things get really interesting from a market dynamics perspective.
The concept is simple and powerful. users group together based on shared intents (“200 people looking for ergonomic chairs under $300 with lumbar support”). Brands then bid aggressively to win these large, clearly defined intent pools, unlocking competitive deep discounts and tailored products that wouldn’t be economically viable for individual purchases. win for the customer (cheaper + personalized), win for the brand (bulk + intent), win for the platform ()
Why don’t platforms like Google or Facebook aggregate crowd intentions, or Amazon, and do almost like a class-action RFP to brands or providers for a set of products that fulfill this demand at a discount? Mostly because their customers (you) are just trying to buy the one thing, and now. with agents, the shopping experience is asynchronous. agents will be purchasing things in the background, over the span of minutes, hours or maybe even overnight. this means the googlebot or shoppingbot can aggregate orders accross several users during the async process. the same can apply to media & entertainment, or service industries.
This flips the traditional [advertising] script entirely. instead of brands pushing products to consumers through targeted ads, consumers are pulling brands into competitive bidding scenarios. the platform becomes a reverse auction house where demand aggregation creates unprecedented negotiating power for consumers while giving brands crystal-clear purchase intent signals.
the mechanics would work something like this: users express specific purchase intentions through natural language queries to their AI assistants (“i need noise-canceling headphones but im broke”). the platform identifies patterns and clusters similar intents (“oh look, 150 broke people want noise-canceling headphones for under $200 with 20+ hour battery life”). once a critical mass is reached, the platform issues an RFP to relevant brands with the exact specifications and guaranteed purchase volume. brands submit competitive bids, and the winning proposal gets distributed to all participants. its like wholesale purchasing but for mass market goods.
the revenue model is straightforward - commission fees and margin collection from the winning brands. but the real value proposition goes beyond just discounts. brands get access to validated demand pools with zero customer acquisition costs, while consumers get products tailored to their exact collective specifications at wholesale-like pricing. everyone wins except maybe the middlemen but who cares about them anyway lol.
this model could work particularly well for categories where customization or bulk manufacturing creates economies of scale - furniture, electronics, travel packages, even services like group fitness classes or educational courses. imagine 200 people collectively negotiating for a custom mechanical keyboard with cherry mx blues and rgb lighting that doesnt look like a gaming rig from 2015. the platform essentially becomes a demand aggregator that can negotiate on behalf of consumer collectives, creating a new form of purchasing power that individual consumers could never achieve alone. its beautiful really.
Conclusion
The ad industry is composed of producing, tracking and [displaying] advertisements at a monitored user touchpoint. We’ve looked at how this will change when its no longer a human user, but rather an AI user. change begets opportunity.
In the old days, the cost to produce an ad was extraordinary. Not only was a audio & video crew required, but make-up, actors, legal, broadcasting and corporate discretion too. Only the megacorp 500s were privy to its benefits, both online and irl. they would hoard shelf space and billboard to the vague audience segments. Now, in the age of AI, this entire process is automatable into fractions of a dollar, personalized to the individual, and down to less than a minute. it is easier than ever to conjure an image, video, or voice. Kalshi aired an AI brainrot ad during the NBA finals, and zuckerberg is [soon] offerring the full suite of services that WPP digital marketing agencies would previously (currently?) toil over for weeks. There are swarms of brand designers sending async emails to their management for validating the minor airbrush touchups, or approval to use a non pantone color pallette. We’ll need fewer executors and keep just the ones with taste. algorithmic targeting has already replaced the only other important aspect of paid media, segment research. recall zuck’s:
“Over the last 5 to 10 years, we’ve basically gotten to the point where we effectively discourage businesses from trying to limit the targeting. It used to be that a business would come to us and say like, “Okay, I really want to reach women aged 18 to 24 in this place”, and we’re like, “Okay. Look, you can suggest to us…” sure, But I promise you, we’ll find more people at a cheaper rate. If they really want to limit it, we have that as an option. But basically, we believe at this point that we are just better at finding the people who are going to resonate with your product than you are”
Some startups are going after this opportunity (creatify, icon), but its a doomed pursuit. Same applies to the attribution game. The platforms have all the power. Creating 4,000+ ad alternatives, A/B tested accross thousands of brands in the largest social network in the world… no startup will come close.
This industry leveraged the [meta] pixel, which would help attribute an ‘anonymous’ individual user’s brand website/app interactions with their FB demographic information. from there the brand got incredibly valuably and previously unavailable information about the people interested in their goods/services. but this was a faustian deal with the devil. i wont toil over how the user PII is being harvested bc u probably already know that. whats more interesting is how the brands got sold. facebook, google and friends collected web traffic behavior, search intent and sales conversions from not just one brand’s interactions, but most brands. they knew why users would click on one ad instead of another. so they took this data, did a 180 and turned to the brands and said look i can tell you why ppl are leaving for your competitors!. which is awesome! … until you (the brand) realizes that your competitor will also now get that data about your ads’ performance. brands are now forced onto the treadmill of better and better ad copy optimization, segmentation, and lower prices. buy this information or ill sell it to your competitors. they have to or they’d fall behind. companies gave away the farm to facebook: they gave away their own customers to their competitors.
Recall the math from earlier, the revenue for these internet trillionaires come from the optimization of their DSP platform. Google DV360 and Amazon DSP are well oiled machines built on billions of daily searches and SKUs. these platforms - especially meta - has gotten so good at segmentation that they can now suggest to a brand "we are just better at finding the people who are going to resonate with your product than you are" (Zuck).
What about getting the best search keywords you ask? we went into this detail earlier, but the integrations of Conversion APIs (CAPIs) with Meta’s Advantage+ or Google’s Performance Max (PMax) are so dominant that to try to game the algorithm or to improve SEO/GEO is similarly futile. Its mosquito subservience, living below the api, the permanent underclass.
the people who are above the api are those who decide the economic incentive models for these platforms. Fidji Simo, who built ebay and Facebook’s advertising business and monetization strategy over a decade before becoming Instacart’s CEO and leading their IPO, recently joined OpenAI as CEO of Applications overseeing ‘product and special business operations’. its ads. she’s doing ads. Dennis Buchheim co-founded early content sharing (pinterest-esque) platform iHarvest (1997-2001), led Yahoo’s search monetization during the search wars (2002-2006), built Microsoft’s display advertising empire including Atlas (2007-2013), returned to Yahoo for programmatic platforms (2013-2016), served as first CEO of IAB Tech Lab developing GDPR frameworks and ads.txt (2017-2021), led Meta’s advertising ecosystem through iOS 14.5 privacy changes (2021-2023), and now heads Adtech/Martech at Snowflake positioning data clean rooms as the privacy-compliant future. theres a few more folks like these but they are the architects of platform economics.
my goal with this (now 125+ page!) schpeel was to say that the economic covenant of the internet is breaking. we’re witnessing the end of a 30-year handshake deal that built the modern web. there’s a $316B search advertising bubble that’s about to pop. When AI agents browse the web on our behalf, never clicking through to websites, the entire economic model that funds the internet no longer works. Google’s AI Overviews are already causing 15-35% traffic drops for publishers. Stack Overflow, Chegg, and Yelp are hemorrhaging users as AI answers their questions directly.
But change means opportunity. The collapse of the old model creates space for new ones. AI-native commerce, agentic interfaces, memory-driven personalization, and collaborative human-AI workflows represent enormous opportunities for those who build the infrastructure of what comes next. The window is narrow. The platforms that will define the next era of the internet are being built right now, by teams that understand both the depth of what’s breaking and the audacity required to build its replacement.
- Attribution and Discovery will be rebuilt from scratch when agents browse headlessly
- Segmentation becomes memory when AI remembers every preference
- Content becomes queryable when everything is structured for machine consumption
i’ll leave you with a quote from the harbinger. if you’re building in this space, i’d love to chat. vincent [at] vincent . net
Chris Dixon:
Over the last 20 years, an economic covenant has emerged between platforms—specifically social networks and search engines—and the people creating websites that those platforms link to.
If you're a travel website, a recipe site, or an artist with illustrations, there's an implicit covenant with Google.
You allow Google to crawl your content, index it, and show snippets in search results in exchange for traffic.
That's how the internet evolved.
David George:
And it's mutually beneficial.
Chris Dixon:
Mutually beneficial.
Occasionally, that covenant has been breached.
Google has done something called one-boxing, where they take content and display it directly.
I was on the board of Stack Overflow, and they did this—showing answers directly in search results instead of driving traffic to the site.
They've done it with Wikipedia, lyrics sites, Yelp, and travel sites.
David George:
Yeah, they did it with Yelp.
Chris Dixon:
And people get upset.
With Yelp, they promoted their own content over others.
These issues existed, but the system still worked.
Now, in an AI-driven world, if chatbots can generate an illustration or a recipe directly, that may be a better user experience.
I'm not against it—it's probably better for users.
But it breaks the covenant.
These systems were trained on data that was put on the internet under the prior covenant.
David George:
Under the premise that creators would get traffic.
Chris Dixon:
That's right.
David George:
And they could monetize it.
Chris Dixon:
Exactly.
That was the premise and the promise.
Now, we have a new system that likely won't send traffic.
If these AI models provide answers directly, why would users click through? We're headed toward a world with three to five major AI systems where users go to their websites for answers, bypassing the billion other websites that previously received traffic.
The question is, what happens to those sites?
This is something I've been thinking about, and I'm surprised more people aren't discussing it.
I feel like I'm screaming into the abyss.
https://a16z.com/ai-crypto-internet-chris-dixon
You’re not alone in the abyss, chris. the abyss stares back.