change means opportunity II: why now
why now
It was a symbiotic relationship. Google benefited from being on THE place to find information. Users benefited by quickly finding what they needed. Websites and content creators benefited with larger audiences, focused and happy users, and a clear-cut path toward success. We all got what we needed out of the relationship.
Source: brob
As long as Google was providing ten blue links, it could serve everyone, no matter their values; after all, the user decided which link to click.
By providing ads alongside those ten blue links, Google deputized the end user to choose the winner of the auction it conducted amongst advertisers; those advertisers would pay a premium to win that auction because their potential customer was affirmatively choosing to go to their site, which meant (1) a higher chance of conversion and (2) the possibility of building a long-term relationship to increase lifetime value.
AI threatens this:
If a user doesn’t have to choose from search results, said user also doesn’t have the opportunity to click an ad, thus choosing the winner of the competition Google created between its advertisers for user attention. Because AI gives an answer instead of links, there is no organic place to put the advertisements, bid in its 4 SERP auctions. It is not that Google is artificially constraining its horizontal business model; it is that its business model is being constrained by the reality of a world where, as Pichai noted, artificial intelligence comes first.
In the world of AI Agents you must own the interaction point, and unfortunately there is no room for ads, rendering both Google’s distribution and business model moot. For Google, both must change for the company’s technological advantage to come to the fore.

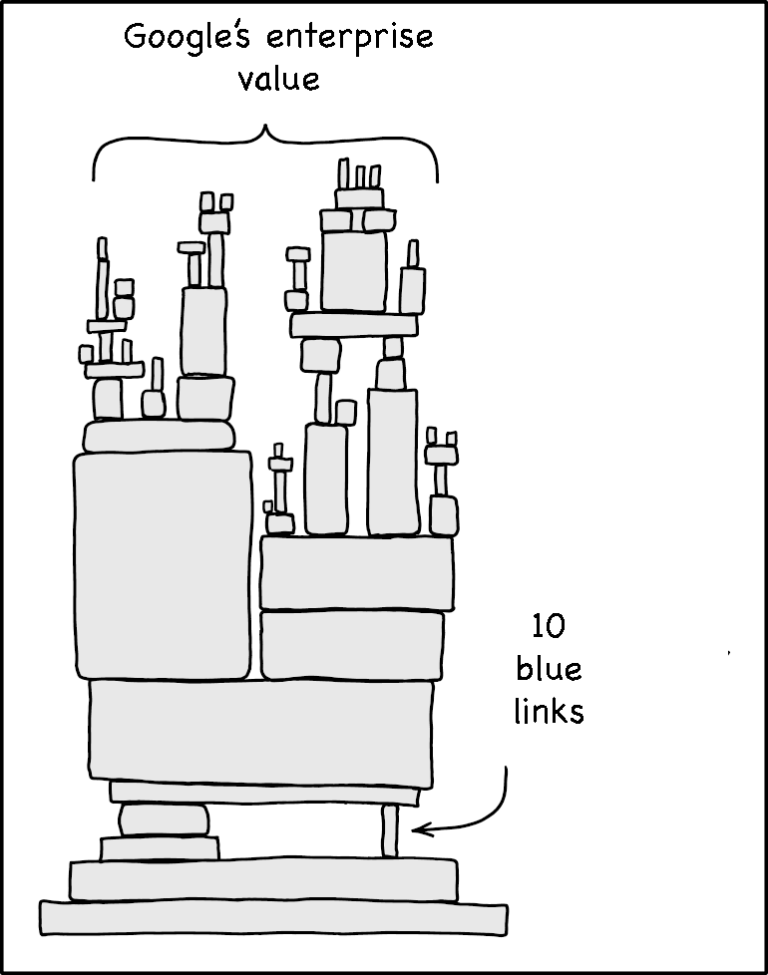
Ben Thompson, India and Gemini: Ten Blue Links & The Complicity Framework (2024)
Additionally, when AI reduces the 10 blue links to one answer, if the subject rests on subjective values, the search result can never satisfy everyone, Google risks upsetting a significant portion of demand, weakening its Aggregator position and potentially decreasing its leverage on costs. For example, a WIRED analysis demonstrated that:
despite claims that Perplexity’s tools provide “instant, reliable answers to any question with complete sources and citations included,” doing away with the need to “click on different links,” its chatbot, which is capable of accurately summarizing journalistic work with appropriate credit, is also prone to bullshitting, in the technical sense of the word.
This undermines the trustworthiness of the AI Overview, and thus also information the end user consumes (and could therafter recite).
There are three major open threads here (opportunities?), which we’ll go into more in depth in the sections on AI Web, Human Interfacing and Economic Incentives.
what now?
What exactly is happening rn in search?
Sundar Pichai when asked about search volume in their 2024 Q4 Earnings Call:
On Search usage overall, our metrics are healthy. We are continuing to see growth in Search on a year-on-year basis in terms of overall usage. Of course, within that, AI overviews has seen stronger growth, particularly across all segments of users, including in younger users. So it’s being well received. But overall, I think through this AI moment, I think Search is continuing to perform well. And as I said earlier, we have a lot more innovations to come this year. I think the product will evolve even more. And I think as you make Search, as you give, as you make it more easy for people to interact and ask follow-up questions, et cetera, I think we have an opportunity to drive further growth. Our Products and Platforms put AI into the hands of billions of people around the world. We have seven Products and Platforms with over 2 billion users and all are using Gemini. That includes Search, where Gemini is powering our AI overviews. People use Search more with AI overviews and usage growth increases over time as people learn that they can ask new types of questions. This behavior is even more pronounced with younger users who really appreciate the speed and efficiency of this new format.
This echoes the “we built Google for users, not websites” Eric Schmidt ethos that Google generally adheres to. In Q1 2025 Pichai writes that they have 1.5B monthly active users using AI Overviews.
Ok so if there are no places to put Search Enging Result Page (SERP) ads anymore, but does that mean there’s no place to put ads at all? Of course not.
In the Perplexity pitch deck, Perplexity explains how their ads would show up as a side banner or a sponsored ‘follow up link’. In October, Google rolled out displaying ads alongside the AI answer (also see last week’s launch of NexAD for smaller AI search engines), much like what Perplexity pioneered a few months earlier. CBO Philipp Schindler reports positive results for AI search overview advertising:
First of all, AI overviews, which is really nice to see, continue to drive higher satisfaction and search usage. So, that’s really good. And as you know, we recently launched the ads within AI overviews on mobile in the U.S., which builds on our previous rollout of ads above and below. And as I talked about before, for the AI overviews overall, we actually see monetization at approximately the same rate, which I think really gives us a strong base on which we can innovate even more.
“We do have very good ideas for native ad concepts but you’ll see us lead with user experience…just like you’ve seen with YouTube, we’ll give people options over time, but for this year I think you’ll see us be focused on the subscription.” - pichai
Figure: Source: Alphabet Filings, MBI.*
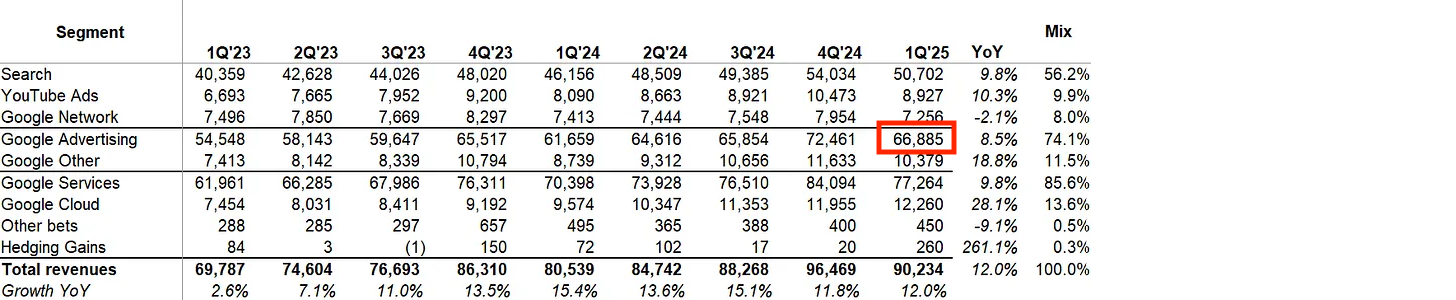
Although this is true, there is is some obfuscation to this truth. We can see that after the gradual rollout of AIO in Q4, Q1 reigned in $66,886M “approximately the same” as last year’s 61,659M. This is notably much less, though. An 8.47% YoY Growth is similar, sure, but also strictly worse than the previous year’s (61659÷54548) 13.03%.
Not only is it worse, but they’re hiding something very important - Cost Per Click has been increasing quite a bit. They cant do this forever.
Unfortunately, these are temporary fixes to a much larger problem.
Problem 1: human interfacing

Figure: Source: Alphabet Filings, MBI.*
Its one thing to replace human agencnies. Its another to replace human agency.
Yes, many of these ad agencies are built on helping brands like Proctor & Gamble find and market to their customers. Since the inception of the advertisement the goal has been to nudge customers to grow an affinity to and purchase their goods and services. Ads encourage the Attention, Interest, Desire and/or Action of purchasing behavior.
Search ads have always been a great place for advertisement because they catch users at a high intent moment. Meaning, a user is actively looking for something, and if you can provide the solution (according to their taste), theyll pick you!
One of the benefits of having 10 blue links was the choice. Users could be the arbiter of taste. Ads and SEO optimized links were entered into the arena of usefulness and the user could declare the victor. This was particularly relevant for Google, who could use a human’s click as a ranking parameter. Now, when an AI Overview is spitting out the answer, the search engine is the arbiter of taste.
This is problematic for two major reasons: Trustworthiness and Usefulness.
Trustworthiness
Google wants to “make information universally accessible and useful”. So, over the years, they’ve tried a bunch of stuff:

Each feature launch was an incremental improvement for Google’s search users. Search for a local restaurant, get a widget in the sidebar (nice and out of the way) with important information like the phone number, address, and even a link to the website. Nice!
All these changes make sense from the Google Side - Google ads became more important (and thus user engagement became more important), so Google wanted fewer users leaving the search page.
Seeing a 2 on the screen when a consumer enters 1+1 is handy, but it’s not without cost. If someone runs a calculator website, showing the 2 could lead to the calculator website’s traffic decline. Google must, therefore, make tradeoffs. These tradeoffs typically are good for users, but not always. As Eric Schmidt once said, “we built Google for users, not websites.” That’s reasonable, especially when it comes to immutable facts. Giving billions of users a quick answer to 1+1 seems like it outweighs the cost of lost traffic to the calculator website operator. But who decides that?
And what if its not true?!
Yes that seems silly to say when the quick snippet answer to 1+1= spits out 2, everyone can indeed agree it is truthful (fun fact it took Bertrand Russell and Alfred North Whitehead 300+ pages to prove this). But what if the “answer” being served up is best pediatrician mountain view ca?
Google will give you an answer: 10 blue links that point capture 99.37% of clicks. meaning, if you’re not in the top 10 ranked pediatricians, you wont get any business. And so SEO optimization games begin for attention capture and algorithmic blessing. These aren’t actually the best pediatricians in mountain view - theyre the best SEO optimized pediatricians in mountainview. This is untrustworthy in itself sure, but AI Overviews take this to another level because it draws from the gamified blue links and its own intuited world model.
When Google’s AIO came out, there was a HUGE problem with the trustworthiness of its answers. It would suggest putting glue on pizza to stop the cheese from sliding, smoking 2-3 cigarretes/day while pregnant and that it indeed violates antitrust law (wait that one actually might be true). See a funny compilation here. Even within their own official pitch deck, Perplexity’s AI answer includes a hallucination – the Studio Ghibli Museum isnt in Shinjuku, in fact, it isn’t even in Tokyo!
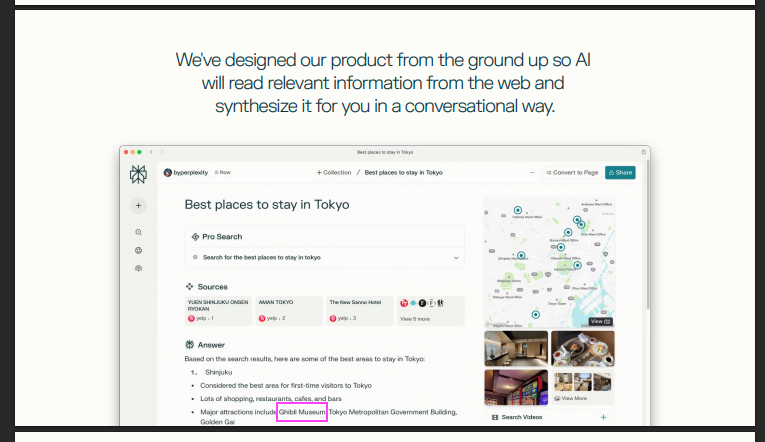
Figure: perplexity is a series Z company.
The web has a rich, competitive offering of services to help answer such a question, yet these search engines give themselves exclusive access to the prime real estate of the page, proclaiming ‘the best answer’ in its answer snippet. By doing this, user’s choices are being made for them. Your choice.
Are you worse off?
Its one thing to replace human agencnies. Its another to replace human agency.
Usefulness
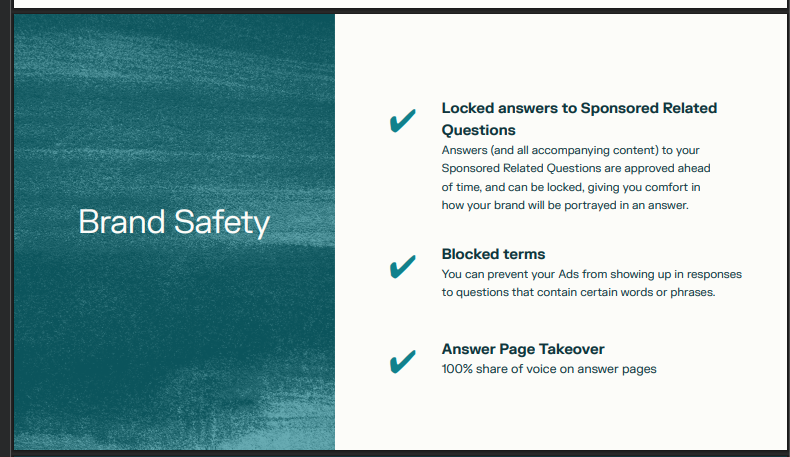
One could argue that a 100% brand takeover is fine if its useful. Lets say you search for a hotel in shinjuku, and the hilton takes over. What percentage of people would just ‘go with it’, without further research? Taking it a step further, what if the there is a One Click 🪄✨ Button?
If your answer (/intuition) is any greater than the % that wouldve selected the same hotel after self discovery, we’ve lost agency, obviously. But usefulness? Harder to measure, but we can look at the counterfactual. If people search through the ten blue links until they find something they are content with, navigating all the levers (price, distance, availability, (subjective) quality, etc), and the distribution of purchases of hotels is any different than that with a brand takeover, it means that some people didnt get their first choice. They were nudged into a suboptimal choice. In my personal opinion, this is evil.
In April 2024, Chief Business Officer Dmitry Shevelenko told Digiday about the plans for a road map focused on “accuracy, speed and readability.” Shevelenko added that the company didn’t plan to rank sponsors differently than organic answers. “The weighting will be the same. That’s our version of ‘Don’t Do Evil,’” Shevelenko told Digiday earlier this year. “We’re not going to buy us an answer. Whenever we have advertising, that’s the one thing we don’t do: You can’t pay us to have the answer be different because you’re paying us.”
That certainly makes sense for Perplexity, which has one other important factor working in their favor: relative to Google, Perplexity doesn’t have any revenue to lose. ChatGPT similarly claims it wont let you ‘buy an answer’:
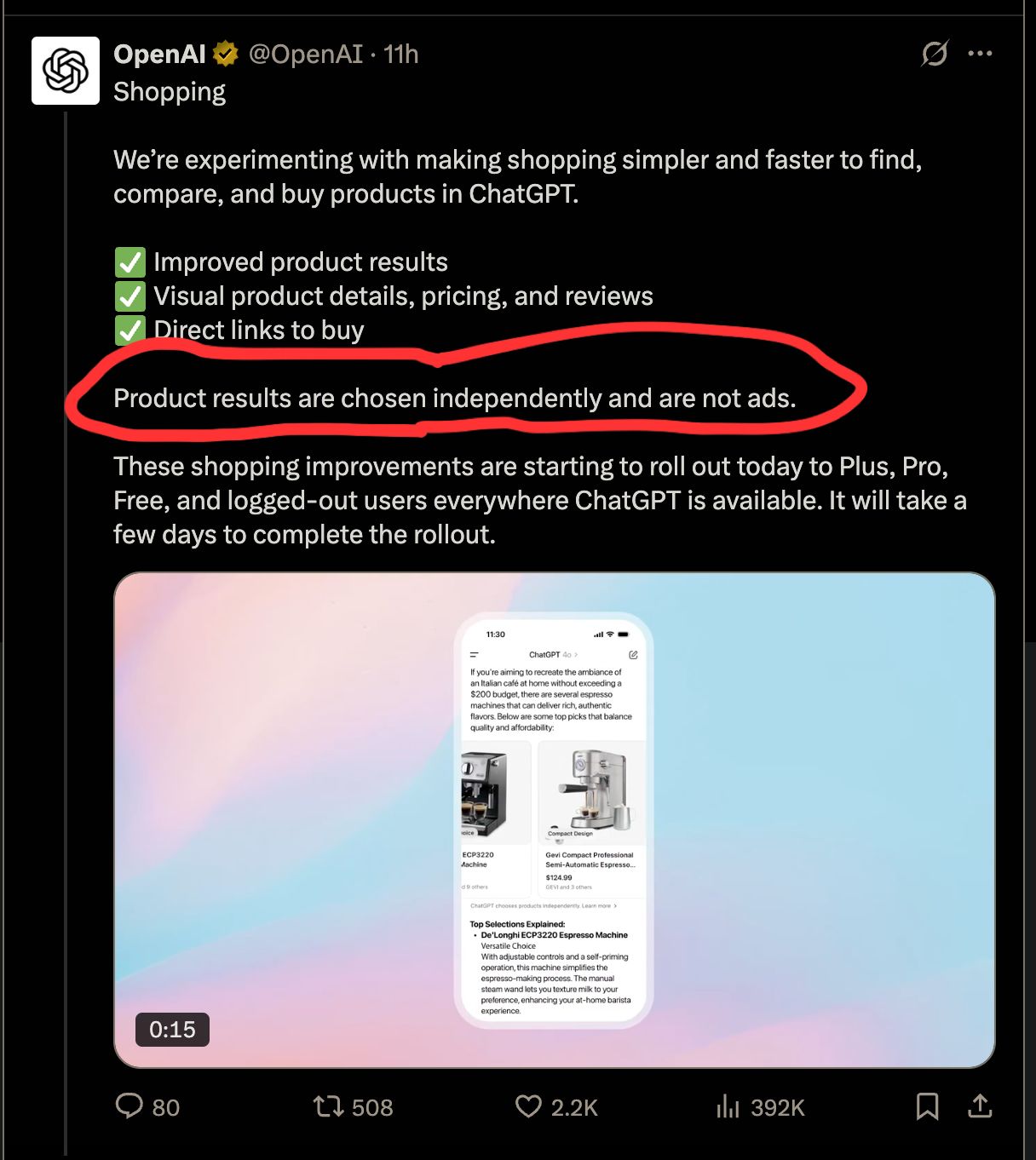
Figure: what happens when u usurp your core operating model.*
Yet its happening. Google announced a few days that it would pervasively display AIO ads. When does a banner ad taking up X% of the screen start having serious impacts on the freedom of choice? 1%->3%->10%->50%->100%? What about traffic to the websites?
The first customers will be major brand advertisers who are both not necessarily looking for a click, but rather to build brand awareness and affinity, and who have infrastructure in place for measuring that (and, helpfully, they have experimental budgets that Perplexity can tap into for now). Brands that have strict brand guidelines, know what keywords to omit and have the bandwith to write manual ‘Sponsor Related Questions’. By blowing large budgets on AI Overviews, these Fortune 200s can not only build consumer Awareness and Interest, but buy Actions that wouldn’t have otherwise taken place. It shouldnt be a surprise either, that these companies are more price inelastic when the search engines increase CPC.

On their pitch deck, Perplexity boasts a 46% Follow-up Question rate. They highlight this because it is one of the opportunities for ad placement, where you can place a website that encourages discovery (e.g. ‘best running shoes -> best running shoes for a marathon’). But to me that screams ineffectiveness: 46% of the time, the user is coming to the platform and not getting the answer theyre looking for (sure, yes, some percentage is discovery, but not all of it). As mentioned before, this points to the ugly truth that for most questions, one search result can’t satisfy everyone. It just isnt useful enough.
Its important to reiterate that with a single answer, we not only reliquishing agency of our choices to The Big Five, but get a suboptimal answer meant to satisfy everyone. In an AI-first world where “we are getting the answer and then moving on,” the multi-visit discovery phase vanishes, collapsing the critical revenue stream for both Google and content publishers. These problems are dialed up to 11 when there are no longer any humans browsing.
Problem 2: ai web
Where we started

The World Wide Web (1989) was built by humans, for humans, and it started with written text, because of course, we started with written text for distribution to the masses. As people began hyperlinking to each other’s websites, the web quickly became cluttered and ‘unparsable for humans’. Don Norman, one of many researchers exploring how people interact with computers in the 1990s, coined “User Experience” (UX) - a shift from focusing solely on aesthetics and/or functionality to considering the user’s needs and emotions.
Google’s subsequent intervention (drawing on Robin Li’s work) was a welcomed relief, bringing us back to human-legible designs. As we know from earlier, they iterated quite a bit to make information universally accessible and useful.
But things changed when agents began browsing the web.
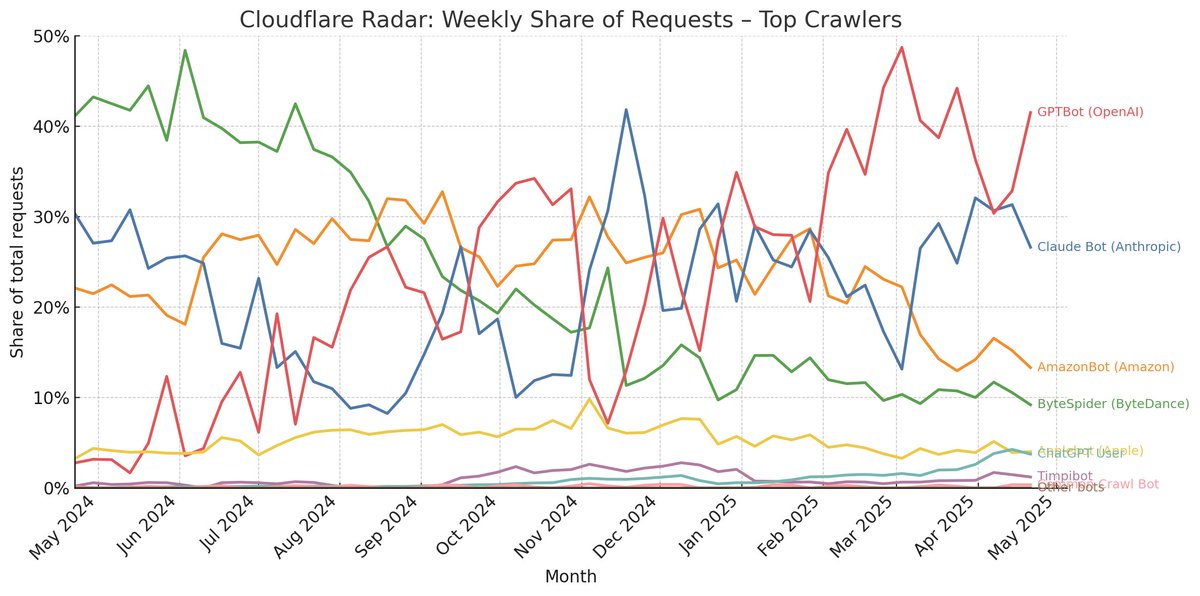
Figure: Source: Cloudflare Data Explorer
The Internet Archive announced back in 2017 that their crawler would ignore a widely accepted web standard known as the Robots Exclusion Protocol (robots.txt):
Over time we have observed that the robots.txt files that are geared toward search engine crawlers do not necessarily serve our archival purposes. Internet Archive’s goal is to create complete “snapshots” of web pages, including the duplicate content and the large versions of files. We have also seen an upsurge of the use of robots.txt files to remove entire domains from search engines when they transition from a live web site into a parked domain, which has historically also removed the entire domain from view in the Wayback Machine. In other words, a site goes out of business and then the parked domain is “blocked” from search engines and no one can look at the history of that site in the Wayback Machine anymore. We receive inquiries and complaints on these “disappeared” sites almost daily… We see the future of web archiving relying less on robots.txt file declarations geared toward search engines, and more on representing the web as it really was, and is, from a user’s perspective.
Maybe you can give them a pass, being a non-profit and all. But when these big AI companies started ignoring robots.txt, despite claiming that they don’t, things get complicated. Robb Knight at WIRED observed a machine — more specifically, one on an Amazon server and almost certainly operated by Perplexity — doing this on WIRED.com and across other Condé Nast publications. This, paired with clear regurgitations of NYT content by ChatGPT sparked a frenzy of lawsuits.

Figure: Source: The court case
OpenAI now lets you block its web crawler from scraping your site to help train GPT models. OpenAI said website operators can specifically disallow its GPTBot crawler on their site’s robots.txt file or block its IP address. “Web pages crawled with the GPTBot user agent may potentially be used to improve future models and are filtered to remove sources that require paywall access, are known to gather personally identifiable information (PII), or have text that violates our policies,” OpenAI said in the blog post. For sources that don’t fit the excluded criteria, “allowing GPTBot to access your site can help AI models become more accurate and improve their general capabilities and safety.”
Blocking the GPTBot may be the first step in OpenAI allowing internet users to opt out of having their data used for training its large language models. It follows some early attempts at creating a flag that would exclude content from training, like a “NoAI” tag conceived by DeviantArt last year. It does not retroactively remove content previously scraped from a site from ChatGPT’s training data.
Tbh this news isnt a solution. Call me cynical, but that last line explains why: OpenAI has already benefited from all of the data on the Internet, and established a norm that sites can opt out of future AI models, whicih cements the advantage of being a first mover and throws the ladder behind them. Since that announcement, GPTBot hasnt slowed down at all, as shown in the above image on crawlers. The opt out is nice, but its not like most publishers know how to update their robots.txt. Plus, who knows what economic impact of opting out these publishers would face.
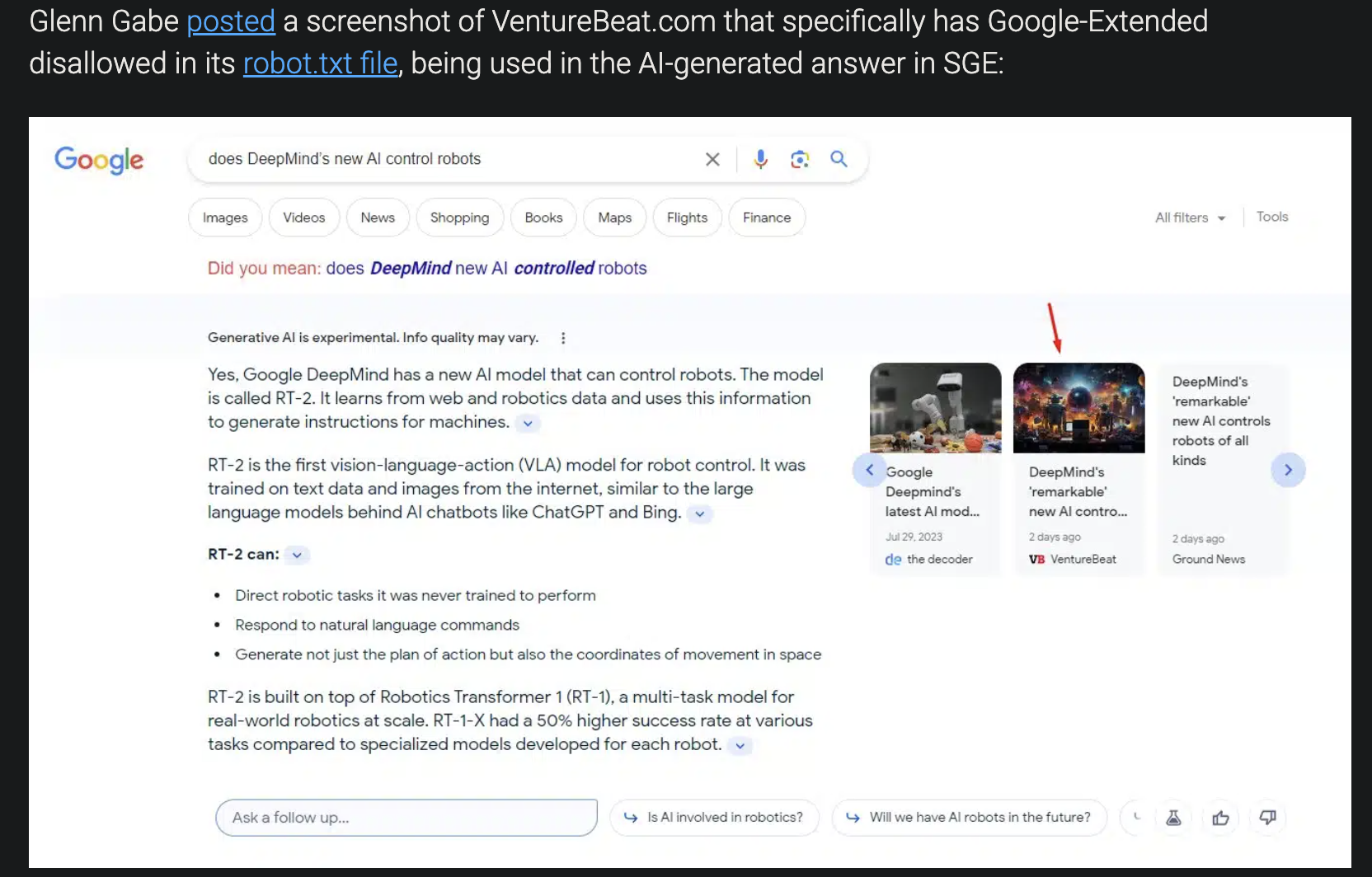
its not like its stopping them from displaying the text in AIO either source
History seems to be rhyming with the German and Belgian publishers 20 years ago. Additionally, if these publishers are not increntivized, to continue giving content to these AIs, are we the stuck in the 2010s internet forever?
Keep in mind that it’s unclear that crawling Internet data is in any way illegal; I think there is a strong case that this sort of data collection is fair use, although the final determination of that question will be up to the courts (e.g., Shutterstock, NYT, Sarah Silverman vs OpenAI & friends). What is certain is that OpenAI isn’t giving the data it collected back.
Where we’re going
Beautiful Soup (bs4) and Selenium have been widely used for testing and automating interactions with web applications. These tools have been instrumental in allowing developers to extract data and simulate user interactions (e.g. what happens when you get the Reddit Hug of Death). 🅱️rowserBase took these tools and made them much more scalable and efficient by abstracting much of the complexity involved in setting up and managing browser instances via the cloud, allowing developers to focus on the logic of their automation tasks. One such task can be penetration testing, sure, but lately a new question is emerging.
What happens when AI agents start browsing on our behalf?
Take a moment to watch this agent buy their human a sandwich via 🅱️rowserbase’s headless browser:
Figure: Source: Evan Fenster on X the everything app
Notice how the AI never stopped or clicked on an ad. The agent had a task, and executed it.
This task was simple enough, as the order and supplier were explicit. But what happens when someone asks their AI Agent to “buy them a red sweater”? We’ll explore more of what the solution requires here, but lets focus on the ad problem in this section.
How should google count these impressions? If they stepped away to brew some coffee, would the user even know about any ads on the websites the agent browsed? Should they?
In a similar vein of questioning, Openai and Perplexity have ‘promised’ to never let you buy an answer, but what happens when the AI Overview / first link upon ‘red sweater’ search result is an ad? This very quickly rehashes the earlier problems of trustworthiness and usefulness.
Taking this a step further: remove the web browser interface altogether. Where are you going put the ads? In the GET requests between Shopify and Openai APIs?
There are a lot of questions here with no clear answers. However, their answers in the pre-Agentic Web era were the foundation on which attribution and discovery were fueled. These measurable ‘bounce rates’, ‘time on site’, etc were what Google, Meta, Shopify & friends used to measure the effectiveness and conversions of ads on their platform. Its all about to be uprooted with ‘personal agents’.
The decline of ads is approaching quicker than we think, first with the decline of publishers, and then with the decline of websites altogether.
Problem 3: the incentives
| Title | Link | Outcome |
|---|---|---|
| Ahrefs Study on CTR Decline | Google AI Overviews Hurt Click-Through Rates | 34.5% drop in CTR for top organic positions when AI Overviews are present. |
| Amsive Research on CTR Impact | Google AI Overviews Hurt Click-Through Rates | Average 15.49% CTR decline across 700,000 keywords; up to 37% drop for non-branded queries. |
| Raptive Estimate on Traffic and Revenue Loss | Why Publishers Fear Traffic Ad Declines from Google’s AI-Generated Search Results | AI Overviews could reduce publisher visits by up to 25%, leading to $2 billion in annual ad revenue losses. |
| Swipe Insight Report on Traffic Decline | Google’s AI Overviews Cause Publisher Traffic Decline Estimated $2B Ad Revenue Loss | Some publishers experienced up to a 60% decrease in organic search traffic due to AI Overviews. |
| World History Encyclopedia Case Study | AI Took My Readers: Inside a Publisher’s Traffic Collapse | Observed a 25% traffic drop after content appeared in AI Overviews. |
| WARC Study on CTR Reduction | AI Overviews Hit Publisher Traffic Hard, Study Finds | Organic click-through rates dropped to 0.6% when AI Overviews are present, compared to 17% for traditional links. |
| Bloomberg Report on Independent Websites | Google AI Search Shift Leaves Website Makers Feeling Betrayed | Independent websites have seen significant declines in traffic due to AI-generated answers. |
| eWeek Analysis on Web Traffic Decline | Google AI Overviews SMB Impact | Some website owners experienced up to a 70% decline in web traffic following AI Overviews introduction. |
| Northeastern University Insight | Google AI Search Engine | AI Overviews could reduce website traffic by about 25%, particularly affecting web publishers reliant on search traffic. |
| Press Gazette Warning on Publisher Visibility | Devastating Potential Impact of Google AI Overviews on Publisher Visibility Revealed | AI Overviews could dramatically impact publisher traffic and ad revenue, especially in health-related queries. |
The foundational handshake of the internet, where content creators exchange their material for traffic and potential revenue, is being shattered by AI overviews that eliminate the necessity for users to visit original content sites. The many studies above, as well as the many previously mentioned (Chegg, Stack Overflow and Yelp), highlight a 15-35% decline in click-through rates (CTR) when AI Overviews are present, with some publishers experiencing up to a 70% decrease in organic search traffic.
Publishers, once riding high on search engine traffic, are now staring down a harsh new reality: their content is being consumed without any direct interaction. Publishers are missing opportunities to sell their goods and services.
This isn’t just about losing ad revenue; it’s about survival.
If these publishers (bloggers, newspapers, scientific research, how-to articles, etc.) no longer exist, or are less incentivized to create high-quality content due to cost savings, the consequences are dire. The pool of information that search engines rely on would become increasingly scarce, or diminish in quality and diversity. As publishers struggle to monetize their efforts, the incentive to invest in high-quality content creation wanes. This scarcity could lead to a homogenized internet landscape dominated by AI-generated content, which often lacks the depth, nuance, and originality that human creators provide. Ryan Broderick writes in Fast Company: “Why even bother making new websites if no one’s going to see them?”

Figure: Source Cision
As revenue becomes increasingly sparse, its understandable that (though these publishers will never admit to it) LLMs are very much generating content on their platforms. Either as a first draft or final draft, publishers first used the AIs to help produce for their long tail (SKU descriptions, sports coverage, etc). As we get more and more AIs publishing, the Dead Internet conspiracy becomes even more real. G/O Media faced social media backlash for using AI to produce articles in 2024, with readers describing the move as “pure corporate grossness” and criticizing the publication of “error-filled bot-authored content.” They ended up selling almost all their portfolio newspapers (including The Onion to my mentor Jeff Lawson, hi jeff <3) and laying off much of their staff. Similarly, when CNET published AI-generated articles without clear disclosure, leading to widespread criticism over factual errors and plagiarism. The controversy resulted in staff layoffs, unionization efforts, and a significant devaluation of the brand. In August 2024, Ziff Davis acquired CNET for 100 million USD, a stark drop from its previous valuation ($1.8B).
Quick Math
Ok lets recapulate and determine just how much $ is up in the air.
Lets deconstruct the global digital advertising market into the affected products. In 2023, Google’s share of digital advertising revenues worldwide was projected to amount to 39 percent. Facebook followed with a projected digital ad revenue share of 18 percent, while Amazon came in third with an expected seven percent. The player from Asia with the highest share is TikTok, with three percent, followed by Baidu, JD.com, as well as Tencent, all three with two percent. Lets break that down.
Global digital ad spend hit $1.1 trillion in 2024.
Digital formats account for roughly 72.7% of total ad spend, i.e. $790 billion.
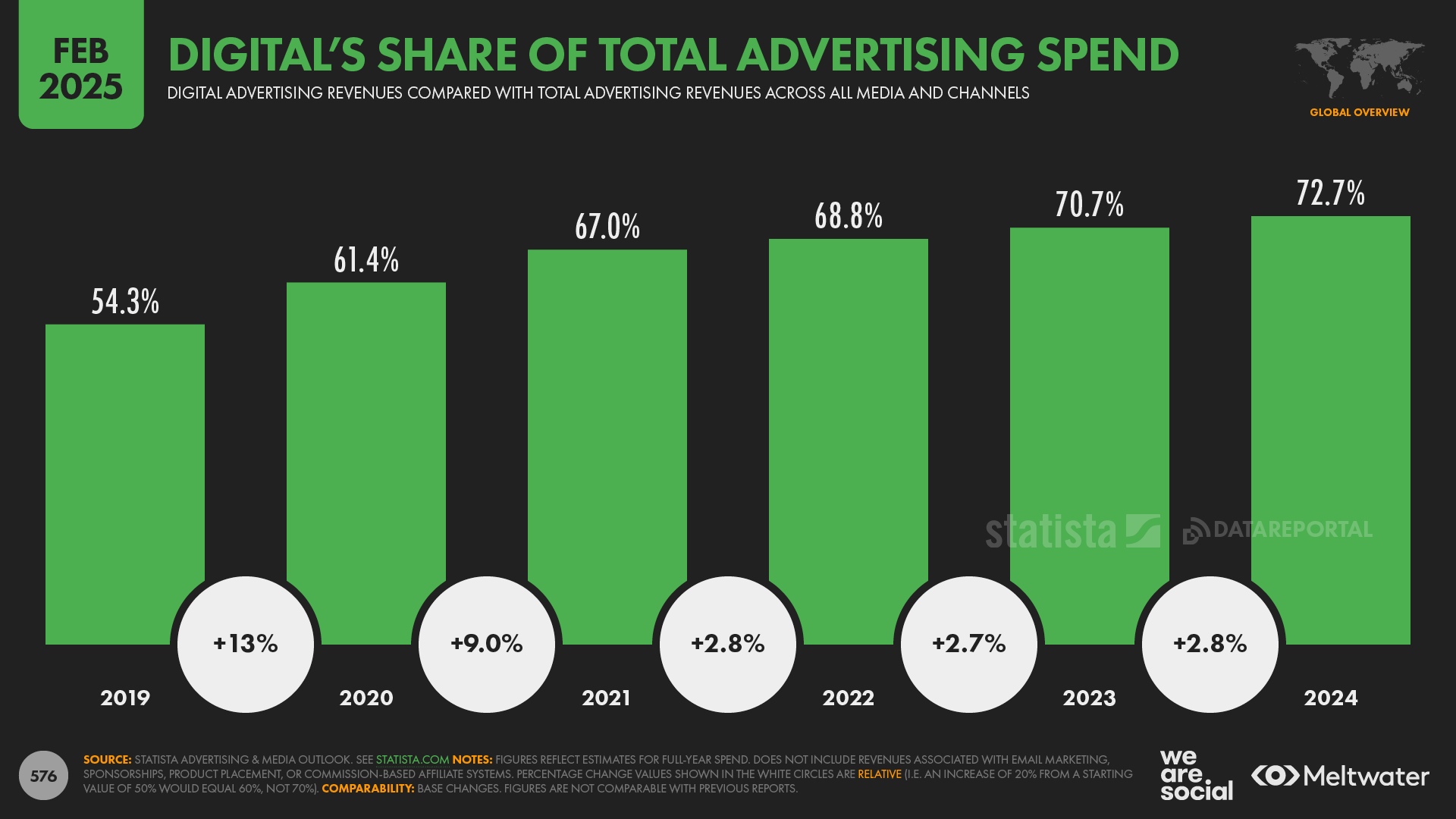
Figure: Source Cision
We can split this into two major spend types: search (SERP) and display (banners, rich media, video).
search ads
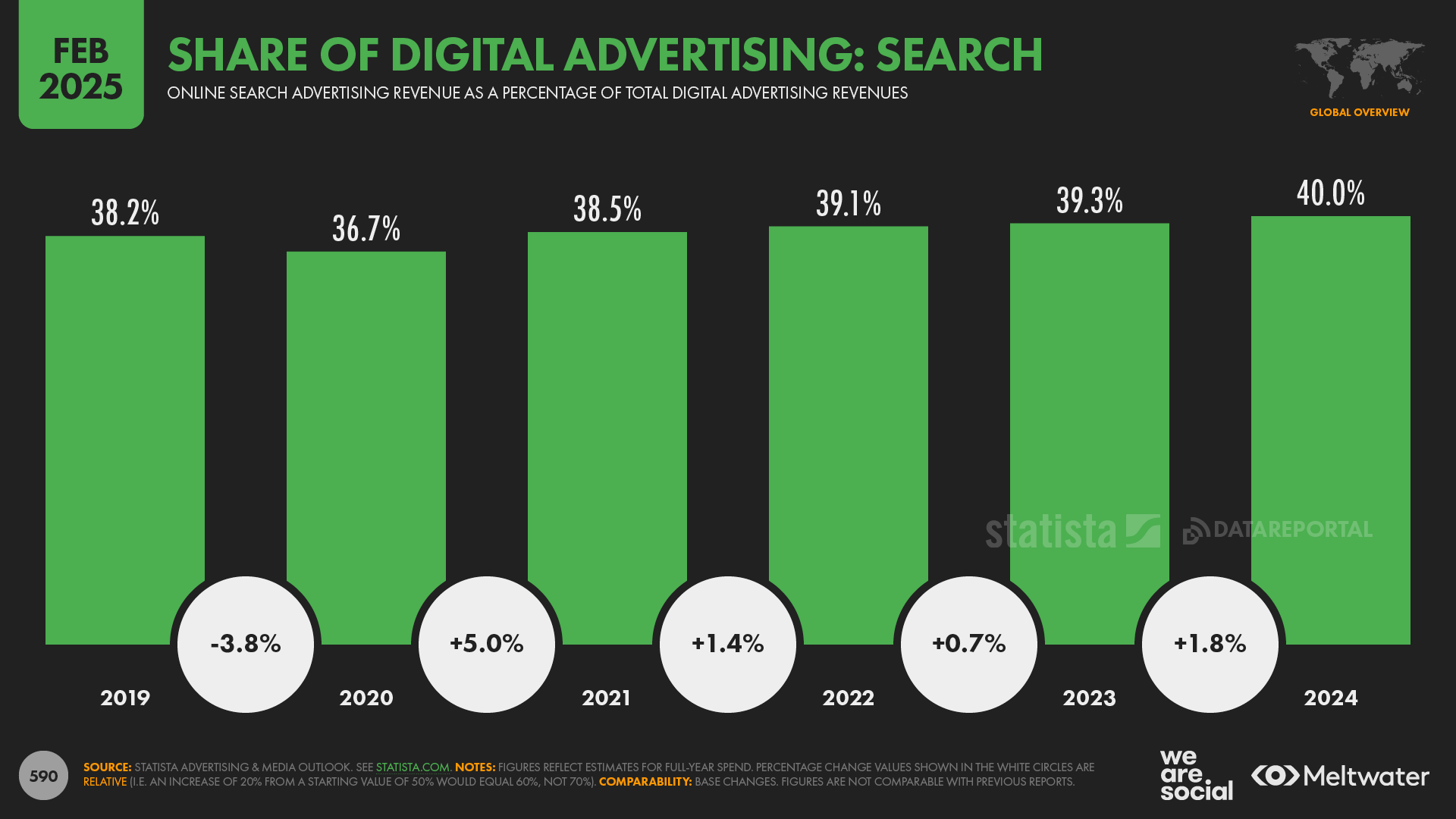
Figure: Source Cision
Obviously, all these numbers are estimates but statista claims 40% of digital spend goes to search, emarketer says 41.5%, and oberlo says 41.4% which means its somewhere in that ballpark. lets just go with the conservative numbers → $316 B
2025 search marketshare, has Google: 89.66% Bing: 3.88% Yandex: 2.53% Yahoo: 1.32% DuckDuckGo: 0.84% Baidu: 0.72% Others: 1.05%. But you can’t just distribute the add spend proportionally, since that would omit the other major search platform, retail.
According to eMarketer, 49% of Internet shoppers start their searches on Amazon, and only 22% on Google; Amazon’s share is far higher for Prime subscribers, which include over half of U.S. households.
Putting it altogether:
| Search Platform | Ad Spend (2024) | Reference |
|---|---|---|
| Google Search (SERP) | $198.1 B | Alphabet 2024 Annual Report |
| Amazon on-site Search | $56.22 B | Jungle Scout: Sponsored Products ≈ 78 % |
| Alibaba on-site Search | $25.2 B | Encodify: $42 B; 60%? is on-site search |
| Walmart Connect Search | $3.5 B | AdExchanger: $4.4 B global ad rev; 80%? on-site search |
| eBay Promoted Listings | $1.47 B | eBay Q4 “first-party ads” $368 M × 4 quarters |
| Target | $0.49 B | Marketing Dive: $649 M Roundel rev; 75%? is product-ad/search |
| Other search engines and retailers (Bing, Yandex, Baidu, etc) |
$43.4 B | Remainder |
| Totals | $316 B |
all of this is going to be seriously challenged by the AI Search renaissance.
display ads
Display ads (banners, rich media, video) represent about 56.4% of digital spend → $461.07 billion.
By 2025 programmatic channels will handle 90% of display ad budgets; assuming a similar rate for 2024, that was roughly $414.96 billion in programmatic display spend
Global affiliate marketing spend (performance-based links driving publisher commissions) will exceed $15.7 billion in 2024
Sponsored content (native, branded articles/videos) in the US alone tops $8.14 billion this year
In total, the combined spending on display ads, programmatic channels, affiliate marketing, and sponsored content is ~$438.8 billion in 2024.
Ad tech fees (exchanges, SSPs, DSPs) typically consume ~30% of programmatic budgets. If publishers capture the other ~70%, that implies 438.8B × 0.7 ≈ $307.16 billion in programmatic display‐ad revenue flowing to publishers. The flip of this is the 131.64B in revenue that the ad industry doesn’t get either.
to single out google’s AdSense for Content program, publishers keep about 68% percent of the revenue. Which, if Google’s programmatic‐platform market share is 28.6% → 111.5 B, publishers receive ~$75.8 B.
According to Gamob, Google’s search revenue sharing network, The Search Partner (AdSense for Search) represents roughly 10% of google’s total revenue. According to the actual 2024 anual report filing, it was closer to 8.67% ($30.36B). Publishers earn 51% of partner-network ad revenue → $15.18 B. Yandex, Yahoo, etc., offer limited or no comparable search-partner revenue-share programs, so we treat their downstream to external publishers as negligible for this estimate.
If we add google’s 198.08B from search, 30.36B from display and youtube/CTV’s 36.15B, it precisely equates to the 61659+64616+65854+72461=$264.59B in 2024 ad revenue we had in the figure back when we were discussing the slowing 8.47% YoY Growth in ad revenue, mitigated by increasing CPC costs. beautiful. whats gonna happen to it? what about these other companies?
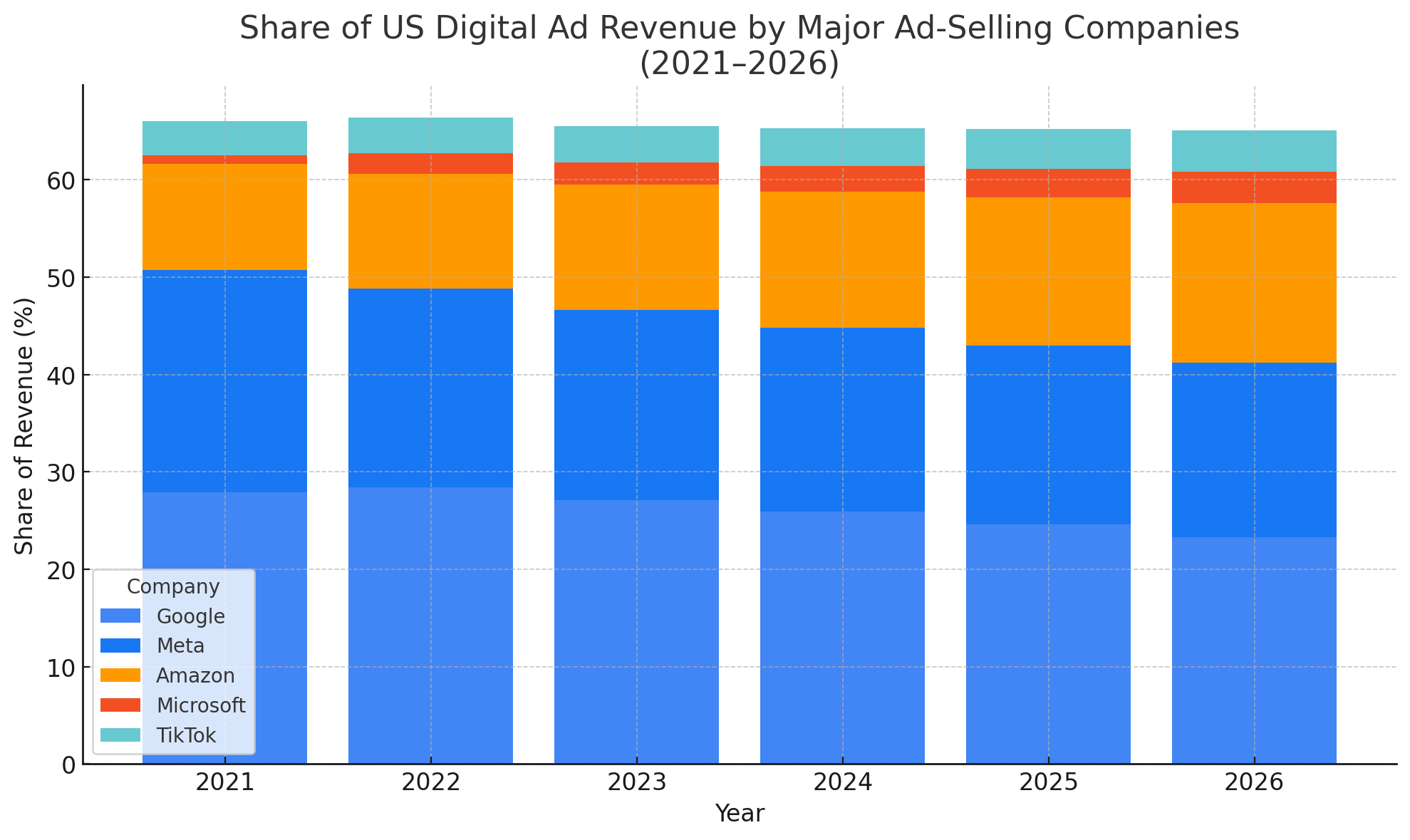
Figure: Source: math + claude viz
Continue: change means opportunity III