change means opportunity III: where to next
where to next?
ok so the economic model of the internet is broken. #genz yay 🙄
the incentives of publishers are no longer to produce high quality content, unless they want to game the algorithm to rank higher in AI Overviews (Generative Engine Optimization) and/or sign a faustian contract to let the algorithms pilage their articles.
when we look for information on the internet, the AI Overviews are not truthful not useful when they give us suboptimal or entirely false answers in the pursuit of ad placements or serving a majority of users.
All that was back when we were using human interfaces - increasingly so, agents are interfacing with the internet on our behalf.
Plus, whats gonna happen to the $316B in search spend? What will Proctor & Gamble gamble on? What will happen to the publishers that are no longer rewarded for web traffic with (~100B in) revenue sharing, and more importantly, can no longer (up)sell their products via their website?
trends
one of the ways to figure out what to do next is to see where things are heading more generally. we should look at what is possible now that previously wasn’t possible due to the advent or convergence of multiple innovations that collectively lead to generational companies. The lineage lines are very clear if you know your history:
Alexander Bell’s advent of the telephone in 1876 came off the convergence of telegraphy (morse code) adoption, electrification progress and the increasingly cheap railroad/wood costs to build poles that could vary the intensity of electric currents to replicate sound waves. With this development of electric signal broadcasting infrastructure, and the utility of instant communicatiton in WW1, broadcasting voice to many users (not just 1-1) was quickly adopted leading to radio’s pervasiveness. 40 years later as cost of producing visual media fell (e.g. photographs instead of paintings), it became more feasible to transmit not just voice but also images over long distances, leading to the first television broadcasts. Early television systems used mechanical methods, such as spinning disks, to scan and display images. With Steven Sasson’s (1975) realization that images could be captured AND stored electronically (by using a increasingly cheap CCD image sensors) he packaged the nobel prize invention with cassete tapes into a toaster sized 8lb portable digital camera.
The Bell Telephone Company established a vast conglomerate and monopoly in telecommunication services until ‘Ma Bell’ was forced to break up in 1982 due to antitrust regulations. This monopoly was based on the pre-allocation of network bandwidth, which involved assigning radio frequencies to different applications. During the Cold War, to prevent the public broadcasting of sensitive data, DARPA initiated the development of ARPANET. ARPANET was built on the foundation of packet-switching, TCP/IP protocols, and IMP routers. This ‘alternative’ to traditional telecommunications was progressively adopted by the university researchers that created it and eventually led to the creation of the web as we know it today. As mentioned earlier, it was important that these data packets sent and received were legible, so Tim Berners-Lee’s developed aa global hypertext system for information sharing. That information, text, voice or the now digial images ‘permitted’ Napster to share music files over the internet from one ‘peer-to-peer’. It was a shortlived movement, from 1999-2001 but revealed the public’s hunger for on-demand, personalized, frictionless access to media, decoupled (decentralized) from traditional broadcast and retail gatekeepers.
But what if, instead of downloading the (music/text/etc) data packets to my floppy disks, I could just host media on the public web and have people stream directly? Great question, YouTube founders. In 2005, as internet bandwidth became capable of file transfers at megabits per second, and Macromedia’s (later, Adobe) 1996 invention of Flash (RIP 1996-2020) enabled interactive websites, simple upload-and-share interfaces democratized video (text/music/etc) publishing while its streaming capabilities eliminated the need for complete downloads before viewing. In 2007, a certain turtlenecked individual merged all of the progress that made PCs more affordable/compute efficient, a digital camera, telephony compliance and internet browsing into (you guessed it) the iPhone. All founders have to mention it at some point, forgive me, but hopefully you can see why its such a landmark moment. Take a moment to bask:
Figure: Source: Evan Fenster on X the everything app
The iPhone revolution, via its app store, permitted social graphs, image sharing and instant news/information sharing that still struggles to satiate the public thirst. Driven by the now vast data published, cloud-distributed computing resources, and rehashed algorithmic research from the 70s, machines could learn patterns (in images, search intent, or entertainment). Its gotten to the point that it can even generate its own entertaining media, or answers to search queries as we very well know by now.
toys
The reason big new things sneak by incumbents is that the next big thing always starts out being dismissed as a “toy.” This is one of the main insights of Clay Christensen’s “disruptive technology” theory. This theory starts with the observation that technologies tend to get better at a faster rate than users’ needs increase. From this simple insight follows all kinds of interesting conclusions about how markets and products change over time.
Disruptive technologies are dismissed as toys because when they are first launched they “undershoot” user needs. The first telephone could only carry voices a mile or two. The leading telco of the time, Western Union, passed on acquiring the phone because they didn’t see how it could possibly be useful to businesses and railroads – their primary customers. What they failed to anticipate was how rapidly telephone technology and infrastructure would improve (technology adoption is usually non-linear due to so-called complementary network effects).
The same was true of how mainframe companies viewed the PC (microcomputer). Initially, PCs were seen as toys for hobbyists, incapable of the kinds of serious business applications that IBM handled. Yet, as software and hardware rapidly improved along the exponential curve of fabs doubling the number of transistors on a microchip approximately every two years, PCs became indispensable tools in both personal and professional settings.
Kodak made a lot of money with very good margins providing silver halide film; digital cameras, on the other hand, were digital, which means they didn’t need film at all. Kodak’s management was thus very incentivized to convince themselves that digital cameras would only ever be for amateurs. Kodak filed for bankrupcy in 2012.
YouTube’s early days featured grainy, amateur videos that serious media companies considered amateurish and irrelevant. “Broadcast yourself” seemed like a frivolous concept when the first videos were cats playing piano and awkward vlogs.
The first iPhone was ridiculed by BlackBerry executives for its poor battery life, virtual keyboard, and limited enterprise features. “It’s a toy for consumers,” panned by the likes of Microsoft’s Steve Ballmer — who laughed off its lack of a physical keyboard.
Early apps were basic utilities and games like “iBeer” (a virtual glass of beer) or keeping the flashlight on. Friendster, MySpace, and Facebook were considered trivial diversions for teenagers — mere digital yearbooks with Farmville and the ability to “poke” each other. Established media companies and advertisers dismissed them as fads, failing to see how these networks would become primary channels for news distribution, customer engagement, and political discourse. Steve Jobs saw right through this, watch this launch of Garageband:
Figure: Source: Evan Fenster on X the everything app
[12:24] I’m blown away with this stuff. Playing your own instruments, or using the smart instruments, anyone can make music now, in something that’s this thick and weighs 1.3 pounds. It’s unbelievable. GarageBand for iPad. Great set of features — again, this is no toy. This is something you can really use for real work. This is something that, I cannot tell you, how many hours teenagers are going to spend making music with this, and teaching themselves about music with this.
A couple years later, facebook left the world wide web to go mobile native. They were pegged as a way to play toy apps and video games. From TechCrunch in 2012:
Facebook is making a big bet on the app economy, and wants to be the top source of discovery outside of the app stores. The mobile app install ads let developers buy tiles that promote their apps in the Facebook mobile news feed (e.g. Farmville, Plants vs Zombies). When tapped, these instantly open the Apple App Store or Google Play market where users can download apps.
Much of the criticism of app install ads rests on obsolete assumptions that view apps as fun baubles instead of the dominant interaction layer between companies and consumers. If you start with the premise that apps are more important than web pages or any other form of interaction when it comes to connecting with consumers, being the dominant channel for app installs seems downright safe.
https://stratechery.com/2015/daily-update-bill-gurley-wrong-facebook-youtubes-competition/
Almost all early efforts of AI were to play recreational games like chess, Go, and poker. OpenAI started by training models to beat DoTA champions. These EXACT same algorithms power website ranking elos, protein folding research, and ChatGPT’s reasoning models. LLMs started with recipes and toy use cases but are maturing into enterprise use cases (starting, of course, with “fresh grad” tasks). the landmark AI Agent paper was about playing minecraft, and you can go watch Claude Play Pokemon right now.
Disruptive innovation is, at least in the beginning, not as good as what already exists; that’s why it is easily dismissed by managers who can avoid thinking about the business model challenges by (correctly!) telling themselves that their current product is better. The problem, of course, is that the disruptive product gets better, even as the incumbent’s product becomes ever more bloated and hard to use. That, though, ought only increase the concern for Google’s management that generative AI may, in the specific context of search, represent a disruptive innovation instead of a sustaining one.
AI
It’s become increasingly clear that AI is not a toy, and will become a defining pillar for the next generation of coalescing trends. We’ll explore many more in the future, but lets focus on AI first and foremost.
I’m not going to go into the history of AI because it’s pretty well known at this point and tbh not super helpful for the unfolding of the agentic web. What I will do, is define Artifical as ‘nonhuman’, and borrow the definition of Intelligence from Jeff Hawkins’ theory of the brain in A Thousand Brains: A New Theory of Intelligence. Hawkins writes:
Intelligence is the ability of a system to learn a model of the world. However, the resulting model by itself is valueless, emotionless, and has no goals. Goals and values are provided by whatever system is using the model. It’s similar to how the explorers of the sixteenth through the twentieth centuries worked to create an accurate map of Earth. A ruthless military general might use the map to plan the best way to surround and murder an opposing army. A trader could use the exact same map to peacefully exchange goods. The map itself does not dictate these uses, nor does it impart any value to how it is used. It is just a map, neither murderous nor peaceful. Of course, maps vary in detail and in what they cover. Therefore, some maps might be better for war and others better for trade. But the desire to wage war or trade comes from the person using the map. Similarly, the neocortex learns a model of the world, which by itself has no goals or values. The emotions that direct our behaviors are determined by the old brain. If one human’s old brain is aggressive, then it will use the model in the neocortex to better execute aggressive behavior. If another person’s old brain is benevolent, then it will use the model in the neocortex to better achieve its benevolent goals. As with maps, one person’s model of the world might be better suited for a particular set of aims, but the neocortex does not create the goals.
To the extent this is an analogy to AI, large language models are intelligent, but they do not have goals or values or drive. They are tech tools to be used by, well, anyone who is willing and able to take the initiative to use them.
How do we use tech today? There are two types of tech philosophies: tech that augments, and tech that automates. We’ll get more into that when looking at economic models for success in this new agentic world. But the quick question we should ask ourselves is: will AI be a bicycle for the mind; tech that we use for achieving our goals, or an unstoppable train we dont control that sweeps us to pre-set destinations unknown?
The route to the latter seems clear, and maybe even the default: this is a world where a small number of entities “own” AI, and we use it — or are used by it — on their terms. This is the outcome that has played out with ‘traditional’ AI algorithms like social media and GPS. This is the iphone outcome that Johny Ive claims as his frankenstein. This is the outcome being pushed by those obsessed with “safety”, and demanding regulation and reporting; the fact that those advocates also seem to have a stake in today’s leading models seems strangely ignored.
agents
The algorithms that are used to play chess and video games, are not particularly useful by themselves. The algorithms become much more capable when connected to tooling that allows them to interact with the world. This can be as simple as the functionality of moving a chess piece (digitally), to the complexity of humanoid robots. These AIs can go beyond their sandbox and actually assist on general tasks. With these increased capabilities comes increased responsibility.
In yesterday’s keynote, Google CEO Sundar Pichai, after a recounting of tech history that emphasized the PC-Web-Mobile epochs I described in late 2014, declared that we are moving from a mobile-first world to an AI-first one; that was the context for the introduction of the Google Assistant.It was a year prior to the aforementioned iOS 6 that Apple first introduced the idea of an assistant in the guise of Siri; for the first time you could (theoretically) compute by voice. It didn’t work very well at first (arguably it still doesn’t), but the implications for computing generally and Google specifically were profound: voice interaction both expanded where computing could be done, from situations in which you could devote your eyes and hands to your device to effectively everywhere, even as it constrained what you could do. An assistant has to be far more proactive than, for example, a search results page; it’s not enough to present possible answers: rather, an assistant needs to give the right answer.
Ben Thompson, Google and the Limits of Strategy (2016)
prophetic words from nearly 10 years ago. we still can’t seem to get there.
As written earlier, the tech not only has to be trustworthy, but also useful. In the agentic world, it isnt sufficient to offer 10 blue links, the UX is that the AI Agent will return with a single answer, trustworthy, useful and correct.
There is a delicate balance between these each of these attributes. For example, trustworthiness can be augmented with encoraging behavior without being to sycopanthic or untruthful if the output suggests cigarretes for a pregnant migraine even if thats what the user wants to hear. This is why correctness protocals are implemented, but overcorrectness can lead to non-useful answers that are overly politically/ethically biased. This gets increasingly muddled when ads are thrown into the AI answer mix.
Without rehashing too much of what has already been raised as qualms, lets look at where agents are headed. Today these agents are mostly the routine, rules based, repitive labor, like form filling and research. The trends of decreasing computation costs, increased algorithmic competency, and pervasive tooling mean that agents will become capable of increasingly complex tasks.
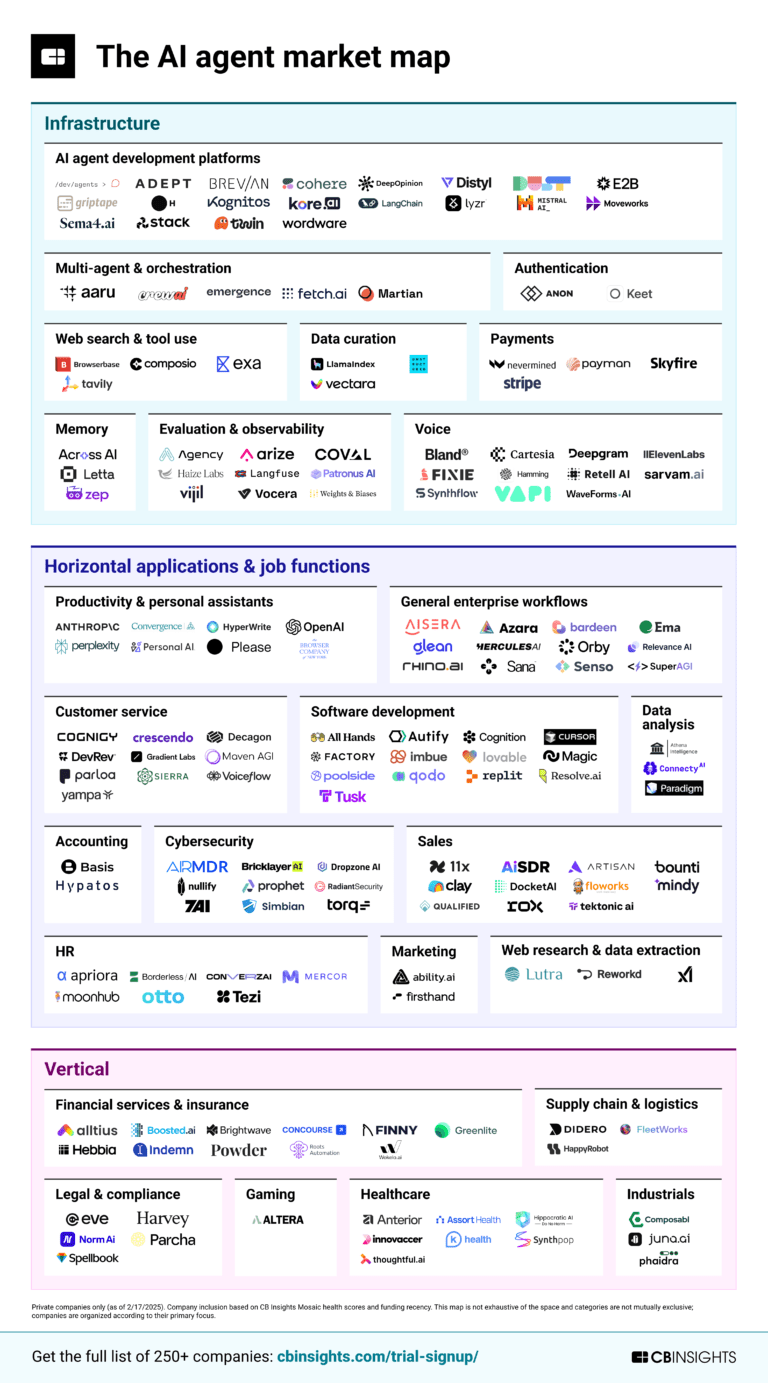
Figure: Source CB Insgights
The tooling for these agents is still in its infancy. Developers are using the scaffolding of Anthropic’s MCP servers, Google’s A2A protocol and OSSs like Langchain to enable their agents to get appropriate context for their tasks, as well as partner with the right services. You can read more about these protocols here: Tyllen on AI Agents.
But tools arent the only thing an agent needs to be successful in their task completion. In order to do what a human would’ve done when presented with the 10 blue links, we need more than just the browser tool and intelligence, we need to translate the user’s intention into a search query, navigate and incorporate the outputs, and structure them in a way useful for the agent and the human it is representing.
We’ll go deeper into intent translation later, as its very much defined by the interface the human contacts its agent through, but it shouldnt be a surprise that there are many startups creating a standardized AgentOS to improve the agentic experience (AX) on the agentic web. tools are just one component in the larger agent economic behavior ecosystem.
organizations
tooling is useful for the individual agent, but once agents start communicating with each other, complications arise. Its one thing to establish the communication protocals of Agent to Agent (A2A) with standards like web2’s HTTP/SSE/JSON-RPC (im compiling a list here), but what about the actions they take?
the most important one is probably payment security. How can I trust that the agent is spending real money, and will receive a real service? to save us both some time, I won’t go into the history of payments digitally, but the major companies who solved online purchasing are now turning their heads to pioneering agentic AI systems that enable AI agents to make payments on behalf of consumers. Visa, Mastercard, Stripe, Coinbase, and PayPal each have come out with a solution in the last 30 days addressing this emerging trend.
| Provider | Product / Toolkit | Description |
|---|---|---|
| Mastercard | Agent Pay | Developed in partnership with Microsoft and IBM. Uses virtual cards, known as Mastercard Agentic Tokens, to enable AI agents to make payments securely and with greater control. Each agent must register and authenticate via a Secure Remote Commerce MCP. |
| PayPal | MCP Servers & Agent Toolkit | Offers MCP servers and an Agent Toolkit that provide developers with tools and access tokens to integrate PayPal’s payment processes into AI workflows. |
| Stripe | Agent Toolkit & Issuing APIs | Provides a toolkit for agents and the option to issue single-use virtual cards for agents to use. The Issuing APIs allow for programmatic approval or decline of authorizations, ensuring that purchase intent aligns with authorization. Spending controls are available to set budgets and limit agent spending. Also available as an MCP |
| Coinbase | AgentKit | Offers a comprehensive toolkit for enabling AI agents to interact with the blockchain. It supports any AI framework and wallet, facilitating seamless integration of crypto wallets and on-chain interactions. With AgentKit, developers can enable fee-free stablecoin payments, enhancing the monetization capabilities of AI agents. The platform encourages community contributions to expand its functionality and adapt to various use cases. |
| Visa | Visa Intelligent Commerce | Allows developers to create AI agents that can search, recommend, and make payments using special cards linked to the user’s original card. Mark Nelsen, Visa’s global head of consumer products, highlights the transformative impact this system has on shopping and purchasing experiences. Visa Intelligent Commerce |
These are just a few of the many tools that anthropic reckognizes (and there’s even more: 5500+, 4500+) ranging from airbnb to oura rings to spotify and everything in between. i’ll be a bit more concrete for what im thinking about later, but picking AI payments as an arbitrary tool example was just meant to segway into whats to come.
AI Firms
Given appropriate tooling, trustworthy authentification and intercommunicated deep intelligence, the fourth level of OpenAI’s AGI roadmap introduces “Innovators” - AI systems capable of developing groundbreaking ideas and solutions across various fields. With the same access to what humans have had for the last N years, these agents will see ways to optimize and discover new cost savings and research discoveries. This stage represents a significant leap forward, as it signifies AI’s ability to drive innovation and progress independently.
To visualize this, conceptualize an agent that is tasked to develop and implement a restaurant menu item. lets say it is a sauce for a pasta dish. with access to a blender, pantry and kitchen utensils, the AI can combinatronically attempt every ingredient x volume x cooking method combination until it arrives at the ‘perfect dish’, innovated from research conducted without (much) human supervision. of coutse, restaurants are from being early adopters, so dont expect this anytime soon. but replace restaurants with wet labs and it is already very commonplace in vaccine research.
There are still a number of bottlenecks here; namely data, energy and feedback collection. This is one of the major upcoming opportunities for the next half-decade.
Ok but now how about collaboration between a group of agents? i should be able to dispatch a gaggle of agents to solve a task and through mutual (chronological) codiscovery they resolve said task - much like we would in a hackathon or school project. This is where things get complicated, not only because of the earlier A2A protocols that need establishing but because there are very few real-life scenerios that have played out like this as reference.
what comes first to mind is an expirement during the cold war where the US government hired three nuclear physicist PhDs and asked them to design a nuke using only public information. these students weren’t einsteins but they were certainly smarter than most ppl. long story short they succeeded. they presented schematics on how to build a working fission bomb. the point: what would happen when you get not 3, or ~20 top-of-their-field experts in a room to discuss and implement projects, but 10,000? 10,000,000,…,000? Even if they dont get any smarter than their current level of top perctentile grad student, the fact that they are digital, that they can be copied infinitely, is a massive unlock. The marginal cost of adding a peak human(+) level intelligence would (currenlty) be a couple dollars an hour.
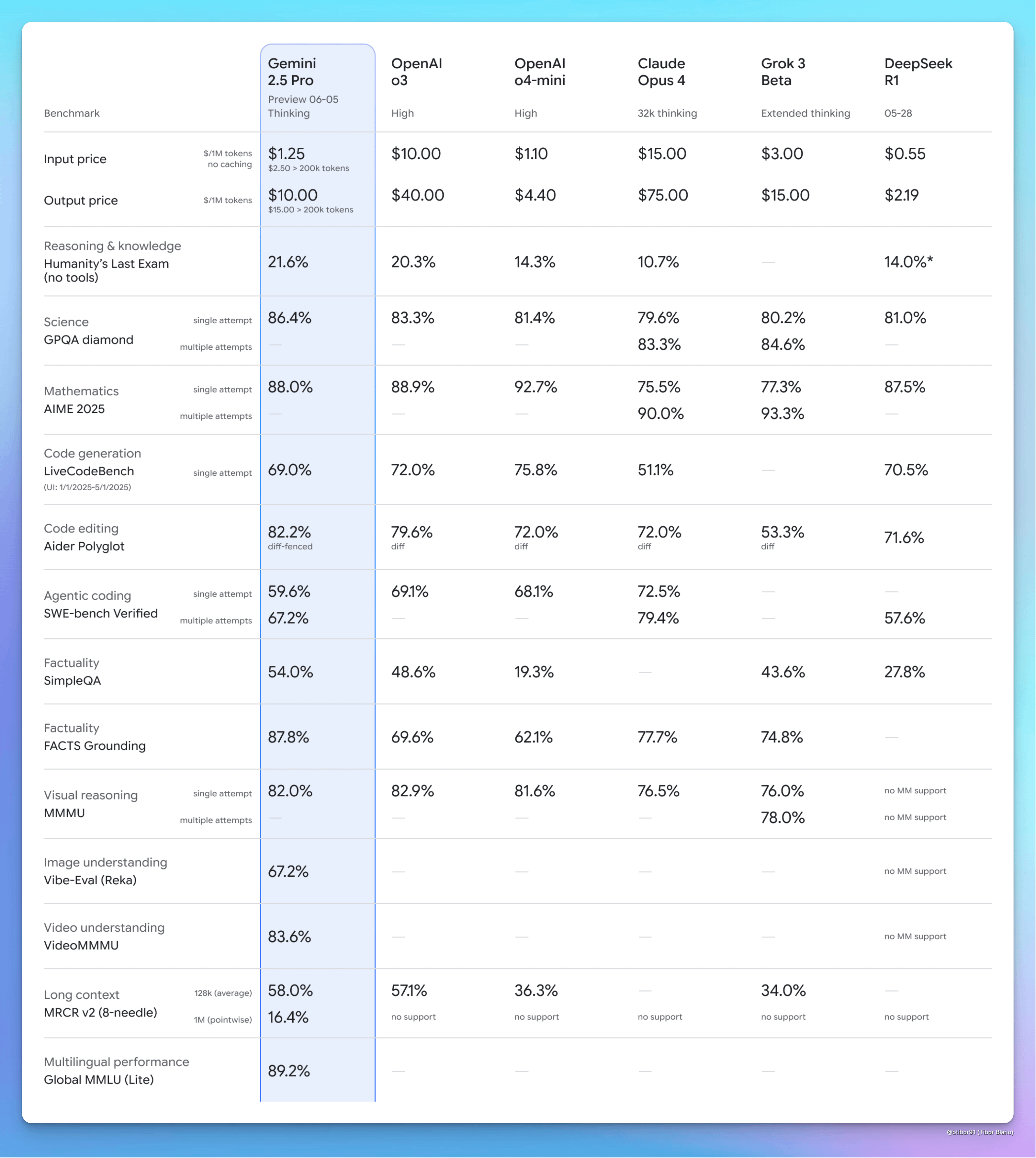
Source: Google 2.5 Pro release, for reference human expert accuracy percent is 81.3% on GPQA Diamond (MCQ test for PhD knowledge domain experts). Fun fact, non experts score 22.1% which is worse than random guessing
What if Google suddenly had 10 million AI software engineers independently contributing billions of hours of research? Copies of AI Sundar can craft every product’s strategy, review every pull request, answer every customer service message, and handle all negotiations - everything flowing from a single coherent vision. As much of a micromanager as Elon might be, he’s still limited by his single human form. But AI Elon can have copies of himself design the batteries, be the car mechanic at the dealership, and so on. And if Elon isn’t the best person for the job, the person who is can also be replicated, to create the template for a new descendant organization.
This is now where we get into Level 5 AGI, AI “Organizations” that can function as entire entities, possessing strategic thinking, operational efficiency, and adaptability to manage complex systems and achieve organizational goals.
While these advanced levels remain theoretical, they represent the ultimate ambition of AI researchers and highlight the potential for AI to revolutionize industries and organizational structures in the future.
It is at this point that sufficiently capital-funded and competent AIs can decide to ‘make or buy’ a service. Why license from A2A services that can do tax filings when the agent can create their own software themselves? Yes, I could pay intuit’s agent, but my agent could also leverage IRS’s recently open sourced direct filing code.
How will the AI firm convert trillions of tokens of data from customers, markets, news, etc every day into future plans, new products, etc? Does the (human?) board make all the decisions politburo-style and use $10 billion dollars of inference to run Monte Carlo tree search on different one-year plans? Or do you run some kind of evolutionary process on different departments, giving them more capital, and compute/labor based on their performance? Maybe closer to the approach of Eric Ries’s Lean Startup and most PE/VC portfolio hedging practices?
All this is far away, but where we’re headed – especially if the major payment providers cannot support A2A micropayments/tooling when the cost of coding the service from scratch would be less than the smallest macropayment.
and then?
this gets esoteric quickly but we should also think about the second-order effects — the broader changes enabled by new technology. For example, after cars were invented, we built highways, suburbs, and trucking infrastructure. A famous idea in science fiction is that
“good writers predict the car, but great writers predict the traffic jam”-Fredrik Pohl.
Historical data going back thousands of years indicates that population size is the key input for how fast your society comes up with more ideas, and thus progresses. This is a pattern that continues from antiquity into modern day: ancient Athens, Alexandria, Tang dynasty Chang’an, Renaissance Florence, Edo-period Tokyo, Enlightenment London, Silicon Valley VCs and startups, Shenzhen, Bangalore and Tel Aviv. The clustering of talent in cities, universities and top firms (e.g. paypal mafia, traitorous eight) produces such outsized benefits, simply because it enables slightly better knowledge flow between smart people.
but why is it so hard for corporations to keep their “culture” intact and retain their youthful lean efficiency? Corporations certainly undergo selection for kinds of fitness, and do vary a lot by industry and mission. but the problem is that corporations cannot replicate themselves … Corporations are made of people, not interchangeable, easily copied software widgets or strands of DNA .. leading to scleroticism and aging. read more directly from gwern.
AI firms will have population sizes that are orders of magnitude larger than today’s biggest companies - and each AI will be able to perfectly mind meld with every other, resulting in no information lost from the bottom to the top of the org chart. what new ideas will come from this?
media & entertainment
ok i need a dopamine distraction from the spooky future uncertainty.
I dont want to get too deep into the trends of the B2C world but you can basically boil it down to: time and attention are the scarse resources, and that people want entertainment in moments of leisure. The modernization of many services has allowed the average american more leisure time, and this will only increase with more services being productionized by AI Agents and Organizations. Stanford HAI and ‘matter experts’ guestimate 20-30% reduction in working hours by 2030, which essentialy means a 4day work week (finally?). Unlikely, though, as we’ll probably get people to just do 30% more work in the same 5 days. in late stage capitalism, the treadmill speed increases and those who dont adapt will be left behind.
Leisure, one would hope, is used for social gatherings, rest, and creating meaningful life experiences. This was the promise of the early social media networks. Facebook, MySpace and Tumblr had a chronological timeline of events that friends and family would post about online. Much to the chagrin of newspapers, the instantaneous nature of status updates meant that people were increasingly turning to these platforms for news - no need to wait for tomorrow’s newspaper. Facebook caught on and introduced the News Feed in 2006. Initially, the introduction of the news feed was met with backlash from users who were accustomed to a more static and controlled browsing experience. A day later Adam Mosseri (whom i met last week walking with his kids to get boba!) told Casey Newton on Platformer that Instagram would scale back recommended posts, but was clear that the pullback was temporary:
“When you discover something in your feed that you didn’t follow before, there should be a high bar — it should just be great,” Mosseri said. “You should be delighted to see it. And I don’t think that’s happening enough right now. So I think we need to take a step back, in terms of the percentage of feed that are recommendations, get better at ranking and recommendations, and then — if and when we do — we can start to grow again.” (“I’m confident we will,” he added.)
They reimplemented the News Feed soon thereafter because although there was some public outcry (privacy, relevance, etc), the statistics (DAU, engagement, etc) were saying otherwise. Users much prefered this UX, even though the shift to a dynamic feed, where content was constantly curated and updated algorithmically (via EdgeRank), felt intrusive and overwhelming to many. However, over time, as algorithms improved and users adapted, the news feed became an integral part of social media platforms, driving engagement and allowing for more personalized content delivery. This evolution highlights the delicate balance platforms must maintain between innovation and user acceptance, as well as the ongoing challenge of ensuring transparency and trust in algorithmic decision-making.
Michael Mignano calls this recommendation media in an article entitled The End of Social Media:
In recommendation media, content is not distributed to networks of connected people as the primary means of distribution. Instead, the main mechanism for the distribution of content is through opaque, platform-defined algorithms that favor maximum attention and engagement from consumers. The exact type of attention these recommendations seek is always defined by the platform and often tailored specifically to the user who is consuming content. For example, if the platform determines that someone loves movies, that person will likely see a lot of movie related content because that’s what captures that person’s attention best. This means platforms can also decide what consumers won’t see, such as problematic or polarizing content.
It’s ultimately up to the platform to decide what type of content gets recommended, not the social graph of the person producing the content. In contrast to social media, recommendation media is not a competition based on popularity; instead, it is a competition based on the absolute best content. Through this lens, it’s no wonder why Kylie Jenner opposes this change; her more than 360 million followers are simply worth less in a version of media dominated by algorithms and not followers.
Facebook made a nearly existential mistake though. They still relied on the social networks of your friends to decide what you would be interested in. If 10 of your family members liked a post about a cousin’s wedding, their scalable version of collaborative filtering would recommend that same post to you. It was indeed an improvement above what people were being served previously. But TikTok took this a step further. Instead of pulling only from those you are Following, they curated content For You. This could be completely novel videos none of your family have seen or interacted with - just other people that have similar scrolling habits. When you’re connected to 8B people, an infinite feed emerges. instead of the platform having to generate all of the content (TV), users generate all of the content themselves. This detail of personalization was much more precise than previously attainable and marked a profound shift. facebook and people were focused on building social networks, because they think people want to connect what their friends. thats not what they want. they want to sink into their couch, glaze over their eyes and injest nose-puffing humor until (the eternal) sleep. Leisure isnt being used for social fulfilment instead, it is almost entirely comprised of TV (4.28h/day if boomer) or the zoomer equivalent (1.9h/day youtube + 1.5h tiktok).
In a fireside chat with zuck last week, he mentioned where they’re headed next. A more formalized explanation can be found in recent interviews and earning reports.
“AI is not just going to be recommending content, but it is effectively going to be either helping people create more content or just creating it themselves. You can think about our products as there have been two major epochs so far. The first was you had your friends and you basically shared with them and you got content from them and now, we’re in an epoch where we’ve basically layered over this whole zone of creator content. So the stuff from your friends and followers and all the people that you follow hasn’t gone away, but we added on this whole other corpus around all this content that creators have that we are recommending. The third epoch is I think that there’s going to be all this AI-generated content and you’re not going to lose the others, you’re still going to have all the creator content, you’re still going to have some of the friend content. But it’s just going to be this huge explosion in the amount of content that’s available, very personalized and I guess one point, just as a macro point, as we move into this AGI future where productivity dramatically increases, I think what you’re basically going to see is this extrapolation of this 100-year trend where as productivity grows, the average person spends less time working, and more time on entertainment and culture. So I think that these feed type services, like these channels where people are getting their content, are going to become more of what people spend their time on, and the better that AI can both help create and recommend the content, I think that that’s going to be a huge thing. So that’s kind of the second category.”
-Zuck
Sam Lessin (former VP of FB Product) broke this down into five steps in July 2022 (pre-ChatGPT!):
- The Pre-Internet ‘People Magazine’ Era
- Content from ‘your friends’ kills People Magazine
- Kardashians/Professional ‘friends’ kill real friends
- Algorithmic everyone kills Kardashians
- Next is pure-AI content which beats ‘algorithmic everyone’
Zuck is building a 2GW+ datacenter the size of manhattan costing ~$60-65B specifically with aims to improve Llama and leaning into the ai slop. This is them learning from nearly fatal Tiktok risk and Adam Mosseri’s recommendation media: conducted behavior > preferred behavior. Less than 7% (1 in 14) of time on instagram is seeing content from friends, the trend will only continue to decrease.
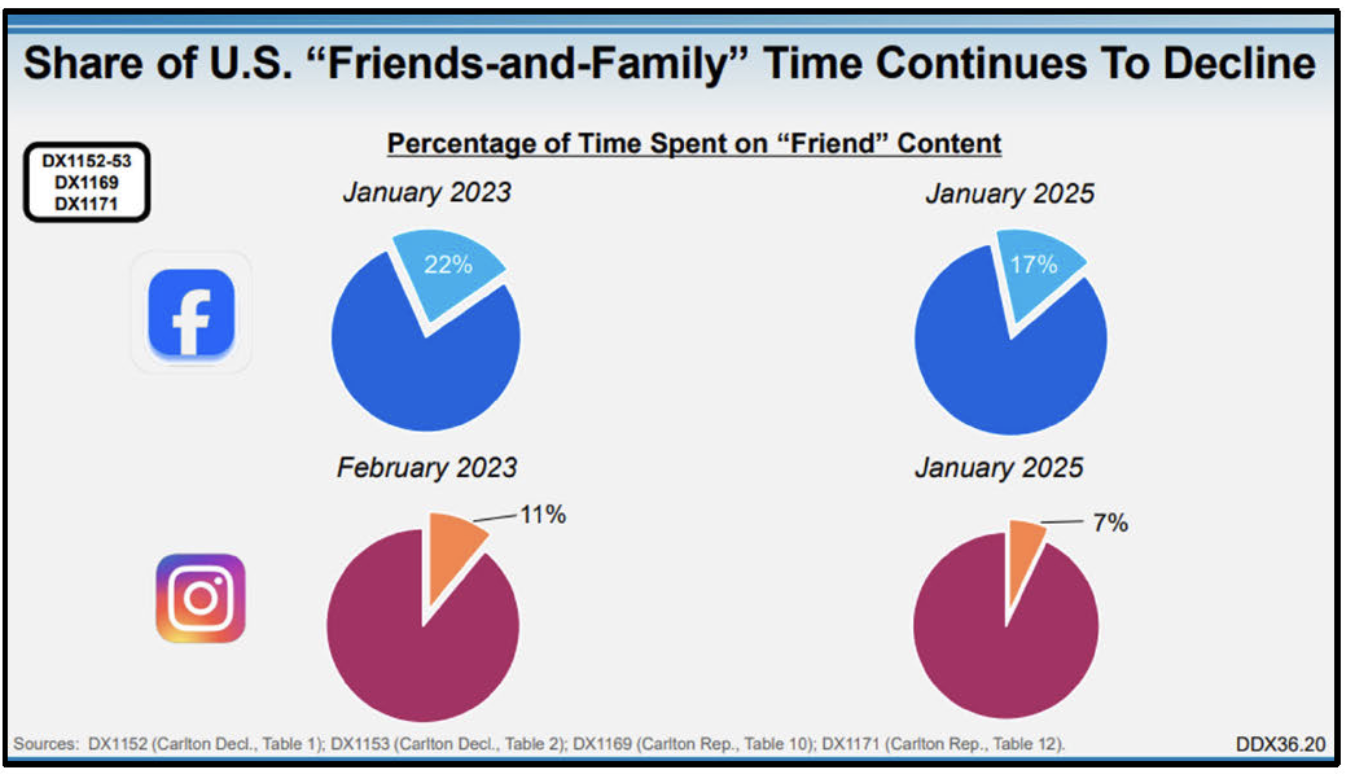
Source: FTC v. Meta Trial Exhibits
FWIW, we shouldn’t think of these platforms as social media networks. they aren’t. theyre entertainment platforms, competing for the mindshare of the leisuring gentry. the real social network are group chats (whatsapp, discord, iMessage), where 1-1 or 1-few conversations still happen. sidebar- the annoucement of ads in whatsapp killed a little flame in my soul. as long as we can keep (intentional) interest-defined trusted social groups away from the algo slop that has slowly consumed entertainment, I will continue to be an internet citizen.
Entertainment itself is evolving. And the trend is towards ever more immersive mediums. Facebook, for example, started with text but exploded with the addition of photos. Instagram started with photos and expanded into video. Gaming was the first to make this progression, and is well into the 3D era. The next step is full immersion (virtual reality) and while the format has yet to penetrate the mainstream this progression in mediums is perhaps the most obvious reason to be bullish about the possibility. Drawing from the large corpus of 360° videos, you could turn every image/video into interactive media with ai. Immersion is the next entertainment paradigm.
wearables as future

If you’ve seen an advertisement in the last 6 months, chances are you saw one of the new ray ban x meta ambassadors. They are investing an incredible amount of money into this, not only [hundreds of] millions in ad spend, but also eating the cost of production ($1000->$300) for each of the 2M+ sold. Not to mention the $20B in 2025 spend Meta CTO Andrew (Boz) Bozwell’s Reality Labs, topping the $80 billion since 2014, when they purchased VR headset maker Oculus. The Ray Ban glasses are just a stepping stone for their next play - hear it from Boz himself:
AB: So I’ll tell you another demo that we’ve been playing with internally, which is taking the Orion style glasses, actually super sensing glasses, even if they have no display, but they have always-on sensors. People are aware of it, and you go through your day and what’s cool is you can query your day. So you can say, “Hey, today in our design meeting, which color did we pick for the couch?”, and it tells you, and it’s like, “Hey, I was leaving work, I saw a poster on the wall”, it’s like, “Oh yeah, there’s a family barbecue happening this weekend at 4 PM”, your day becomes queryable.
And then it’s not a big leap, we haven’t done this yet, but we can, to make it agentic, where it’s like, “Hey, I see you’re driving home, don’t forget to swing by the store, you said you’re going to pick up creamer”. And it’s like, oh man, there’s all these things that start to change. So you’ve got this VR and MR as this output space for AI, and then you’ve got this kind of AR space where it’s like it’s in the AIs on the inputs.
Fully immersive virtual reality may still be a few years away, but Meta is making a massive bet that Augmented Reality is here, soon. Theyre not the only ones. Google and Warby Parker announced their partnership on May 20th. The next day Jony Ive joins Openai to launch a trailer for a product that will be AI native.
The vision for all of them is the same: Apple needs disrupting. The #1 company in the world by market cap has held a stronghold on the app economy, and interfaces to humans. It is the ultimate consumer product, everyone else is downstream.
Startups and upstarts like limitless, humane pin (now HP), rabbit r1, bee band, and the unfriendly avi behind friend are all jumping at the multi-trillion dollar opportunity as well.
The form factors differ wildly: glasses, pins, necklaces, wristbands, to ‘airpods with a camera’, but they all share the same capacity to have a queryable AI listening/seeing everything. MKBHD’s seminal review of the r1 was a brutal reminder that good enough isn’t good enough in consumer hardware. The final form factor continues to be unclear, but having a new interface to the end users is the bet every one of them are making.
Dont think apple is sleeping on this either, btw, they’re just throwing out flops like Apple Vision Pro and Apple Intelligence for reasons masterfully outlined in bloomberg. Essentially, they never took the AI opportunity seriously:
- Apple’s head of software engineering didn’t believe in AI
- Apple’s head of AI was skeptical about LLMs and chatbots
- Apple’s former CFO refused to commit sufficient funds for GPUs
- Apple’s commitment to privacy limited the company to purchased datasets
- Apple’s AI team is understaffed (and the relative talent level of an AI staffer still at Apple is uncomfortable to speculate about, but, given the opportunities elsewhere, relevant)
This also is taking a massive swing at google, where the interface that every year google pays $20B+ to be the default search engine of may soon dissapate as well. I can just ask my AI wearable to search for information, or perform tasks. Pair this with the recent damaging testimony from Eddy Cue that now that search volume’s down, they may switch: “Oh, maybe we’ll do Perplexity, maybe we’ll do some sort of AI search engine”. There’s more of a possibility of choosing something that is “better” today than there has been any other time. The anti-trust trials are highlighting that Google and Apple would’ve done well to give ground before they’re forced to.
There’s still some work to be done, namely bringing the price down, but having a live AI with Meta’s Orion, Google’s Astra, Snap’s spectacles is a magical experience. just look at lex’s reaction. there’s also a massive opportunity to match this with the data from google maps, niantic’s new company, or openstreetview
I like to think i was a pioneer back in 2017 with the snapchat spectacles, but theres a lot more we can build now. As the Ray Ban glasses permeate through culture, the gradual acceptance of AR via Pokemon Go (to the polls) and VR Chat reflect an inevitable trend: users are (sometimes) getting off their phone.
economic models
theres a lot more i want to say about some of the inevitabile tech/trends; notably on agentic shopping, logistic moats, web3, robots and digital physicalism but I’m going to save both of us time and abstractify. i’ll write about them later.
ben thompson at stratechery breaks tech into two major philosophies: tech that augments, and tech that automates. he calls these platforms and aggregators - worth a read.
The philosophy that computers are an aid to humans, not their replacement, is the older of the two. The expectation is not that the computer does your work for you, but rather that the computer enables you to do your work better and more efficiently. Apple and Microsoft are its most famous adherents, and with this philosophy, comes a different take on responsibility. Nadella insists that responsibility lies with the tech industry collectively, and all of us who seek to leverage it individually. From his 2018 Microsoft Build Keynote:
We have the responsibility to ensure that these technologies are empowering everyone, these technologies are creating equitable growth by ensuring that every industry is able to grow and create employment. But we also have a responsibility as a tech industry to build trust in technology. This opportunity and responsibility is what grounds us in our mission to empower every person and every organization on the planet to achieve more. We’re focused on building technology so that we can empower others to build more technology. We’ve aligned our mission, the products we build, our business model, so that your success is what leads to our success. There’s got to be complete alignment.
Similarly, Pichai, in the opening of Google’s keynote, acknowledged that “we feel a deep sense of responsibility to get this right”, but inherent in that statement is the centrality of Google generally and the direct culpability of its managers. Facebook has adopted a more extreme version of the same philosophy that guides Google: computers doing things for people. This is the difference in philosophies, more ‘creepily’ put by zuck in a 2018 f8 keynote:
I believe that we need to design technology to help bring people closer together. And I believe that that’s not going to happen on its own. So to do that, part of the solution, just part of it, is that one day more of our technology is going to need to focus on people and our relationships. Now there’s no guarantee that we get this right. This is hard stuff. We will make mistakes and they will have consequences and we will need to fix them. But what I can guarantee is that if we don’t work on this the world isn’t moving in this direction by itself.
Google and Facebook have always been predicated on doing things for the user, just as Microsoft and Apple have been built on enabling users and developers to make things completely unforeseen.
Google and Facebook, are products of the Internet, and the Internet leads not to platforms but to aggregators. While platforms need 3rd parties to make them useful and build their moat through the creation of ecosystems, aggregators attract end users by virtue of their inherent usefulness and, over time, leave suppliers no choice but to follow the aggregators’ dictates if they wish to reach end users. The business model follows from these fundamental differences: a platform provider has no room for ads, because the primary function of a platform is provide a stage for the applications that users actually need to shine. platforms are powerful because they facilitate a relationship between 3rd-party suppliers and end users; Aggregators, on the other hand, intermediate and control it. Google and Facebook deal in the trade of information, and ads are simply another type of information.
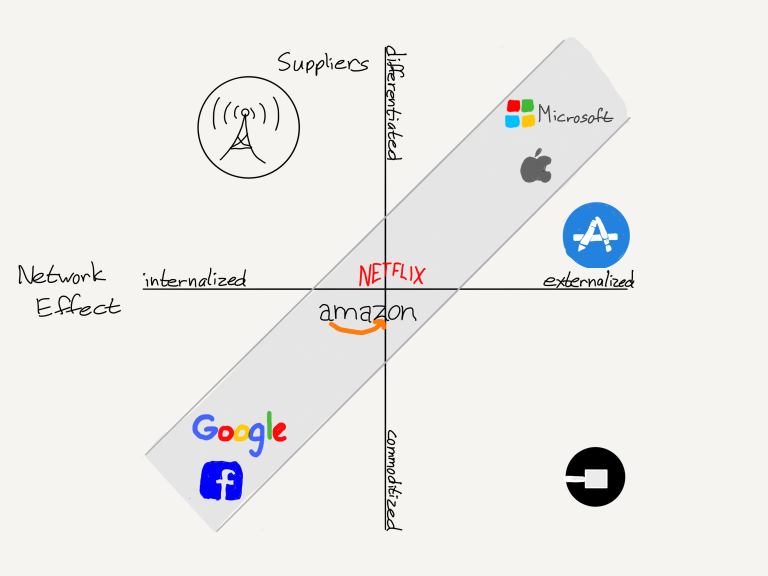
Figure: Stratechery
This relationship between the differentiation of the supplier base and the degree of externalization of the network effect forms a map of effective moats; to again take these six companies in order:
- Facebook has completely internalized its network and commoditized its content supplier base, and has no motivation to, for example, share its advertising proceeds.
- Google similarly has internalized its network effects and commoditized its supplier base; however, given that its supply is from 3rd parties, the company does have more of a motivation to sustain those third parties (this helps explain, for example, why Google’s off-site advertising products have always been far superior to Facebook’s).
- Netflix and Amazon’s network effects are partially internalized and partially externalized, and similarly, both have differentiated suppliers that remain very much subordinate to the Amazon and Netflix customer relationship.
- Apple and Microsoft, meanwhile, have the most differentiated suppliers on their platforms, which makes sense given that both depend on largely externalized network effects. “Must-have” apps ultimately accrue to the platform’s benefit.
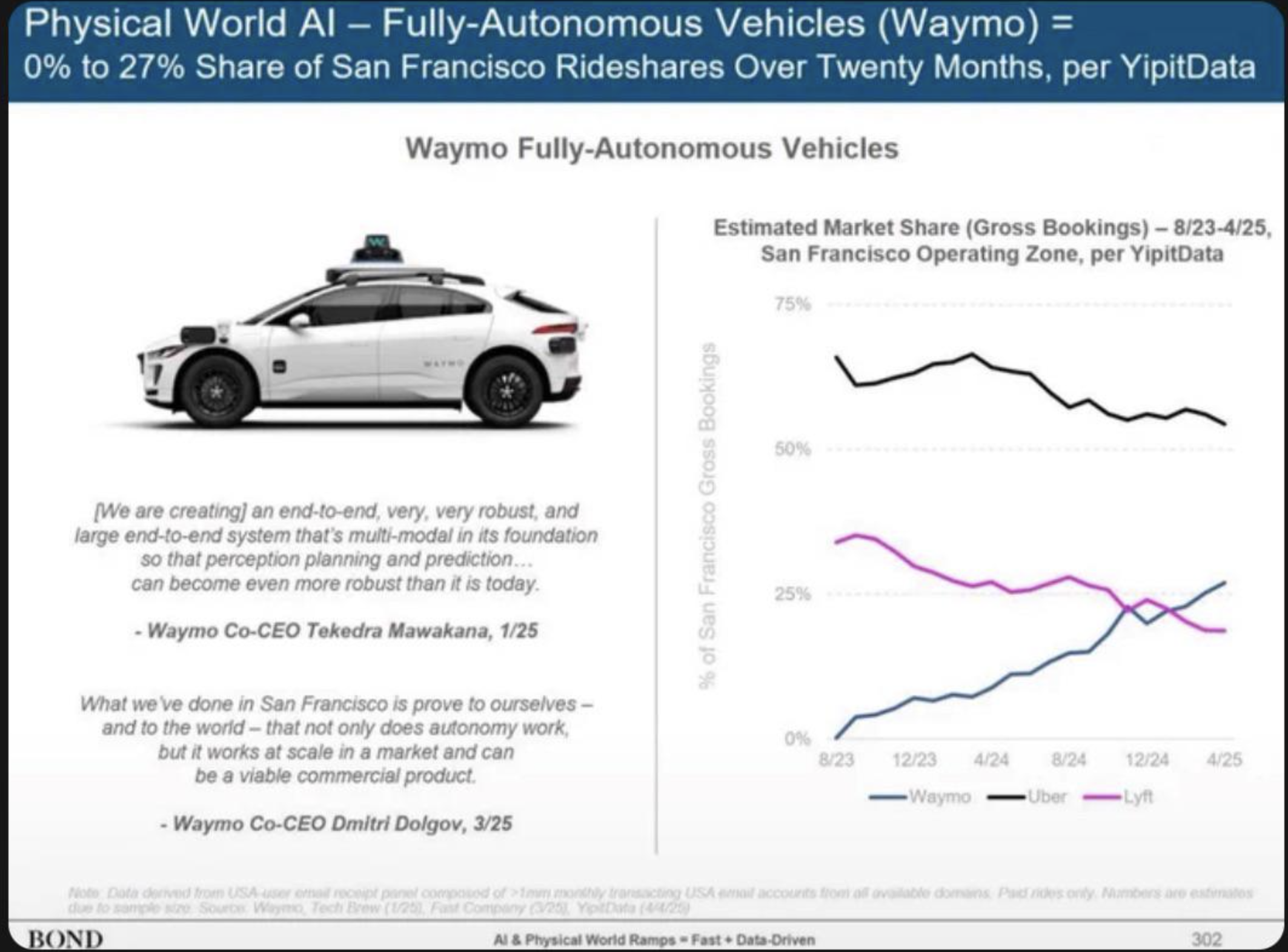
Another example is Uber: on the one hand, Uber’s suppliers are completely commoditized. This might seem like a good thing! The problem, though, is that Uber’s network effects are completely externalized: drivers come on to the platform to serve riders, which in turn makes the network more attractive to riders. This leaves Uber outside the Moat Map. The result is that Uber’s position is very difficult to defend; it is easier to imagine a successful company that has internalized large parts of its network (by owning its own fleet, for example), or done more to differentiate its suppliers. The company may very well succeed thanks to the power from owning the customer relationship, but it will be a slog. Its already lost in China and APAC, and is rapidly losing market share to Waymo.
On the opposite side of the map are phone carriers in a post-iPhone world: carriers have strong network effects, both in terms of service as well as in the allocation of fixed costs. Their profit potential, though, was severely curtailed by the emergence of the iPhone as a highly differentiated supplier. Suddenly, for the first time, customers chose their carrier on the basis of whether or not their preferred phone worked there; today, every carrier has the iPhone, but the process of reaching that point meant the complete destruction of carrier dreams of value-added services, and a lot more competition on capital-intensive factors like coverage and price.
Continue: change means opportunity IV