wait y not just have agi learn the way we do
Large Language Models (LLMs) are traditionally trained by randomly sampling data blocks from massive datasets. However, this way to learn is probably dumb af.
Humans don’t learn effectively by randomly reviewing information -> LLMs might benefit from a more structured approach too.
You may have heard of duolingo $DUOL. They figured something out - humans learn well with spaced repitition.
They also figured out that we like the gamified dopamine hits from that dingy sound and really fantastic advertising. Unfortunately they haven’t yet learned that pittsburgh is a shithole and cmu (my alma mater) talent alone isn’t enough to prop up their entire company.
The same applies to that flashcard guru in ur 10th grade AP Calc class with her 4000 shades of teal crayons. She understood spaced repitition.
Below is my attempt to teach agi spaced repitition. (you getting it yet?)

Midjourney prompt: learning over time, nonathropromorphic, realistic
Abstract aka tldr
Large Language Model (LLM) pretraining usually just tosses data into the model in a random (often redundant, often easy) order. This is super inefficient, and it also leads to “forgetting” the trickier pieces of knowledge. Inspired by human study hacks like spaced repetition, lets propose an alternative “Learn–Concentrate–Repeat” approach that relentlessly hones in on tough data blocks whenever the model starts forgetting them. This drastically cuts training time (up to a 20× speed boost), while also improving downstream quality over standard random-sample training. Basically, the model does its version of flipping flashcards until the knowledge actually sticks.
im not gonna give u a history of spaced repition, or even define what it is. iykyk.
also bc, in the machine learning field – it doesnt fking exist. tho lets place it within the broader idea of curriculum learning, Bengio et al. (2009), which takes lessons from how animals (and kids) usually learn the simple tasks first, then ramp up the difficulty. You might define “easy” by short sentences (fewer tokens) and give easy examples for the first 5 epochs, slightly harder ones for the next 5, etc). That’s basically a linear or stepwise progression, akin to incrementing thru the curriculums of “first grade → second grade → grad school.”
the curriculum learning approaches were basically:
- train on short sentences first, then longer ones
- start with simple shapes, then more complex geometric stuff
- begin with basic tasks, then stack more complex ones on top
some big brains have tried similar-ish stuff:
- self-paced learning (Kumar et al., 2010): lets the model pick its own pace but doesn’t do the review cycles
- competence-based curriculum learning (Platanios et al., 2019): tries to match content difficulty to model competence, but still uses pre-defined difficulty metrics
- anti-curriculum learning (Liu et al. 2022): some madlads tried training on the hardest examples first (like ACCAN for speech recognition). works sometimes but mostly just makes the model cry
but there’s a huge problem with this: who tf decides what’s “easy” and what’s “hard”? in the literature theyre basing it on human annotators or questions that only “highly competent models” could answer. What we’re gonna do is a bit different:
1. dynamic difficulty: we don’t pre-decide what’s hard. the model tells us what it finds difficult through perplexity scores. it’s like when ur studying and ur brain is like “wtf is this” - that’s high perplexity
2. review cycles: traditional curriculum learning is one-way - once u move past the “easy” stuff, u never look back. with spaced repetition, we keep coming back to review shit the model struggled with, just like how u might review flash cards
3. dual-criterion sampling: we’re not just looking at how “hard” something is (perplexity), but also how much the model can learn from it (gradient magnitude). it’s like identifying not just what u find difficult, but also what’s worth spending time on
this is way closer to how humans actually learn. we don’t just go from ez to hard - we circle back, review stuff we’re shaky on, and naturally spend more time on things that are both challenging AND valuable to learn.
time to jump into uncharted waters.

Midjourney prompt: jumping into uncharted waters, in the style of wanderer above a sea of fog
no bs, heres the algorithm
actually thats too easy. its either here or here. 50/50 odds to be devastated.
spaced repitition, explained algorithmically
Split the pretraining process into three main phases $p$:
- Learn Phase
- Train on the entire dataset initially
- Record perplexities for all data blocks
- Duration: $p_1$ epochs - Concetrate Phase
- Remove $s_1$% of easiest data blocks (lowest perplexity)
- Train intensively on remaining difficult blocks
- Duration: $p_2$ epochs - Repeat Phase
- Reintroduce all data blocks
- Allow model to reinforce learning
- Duration: $p_3$ epochs
tbh u can just keep 🔂 2 & 3 until satisfied, as a human would do..
jumping into the pseudo code for the approach, this is where shit starts to get a bit complicated. if you just want to see graph go brrr, jump to here
Inputs:
- Training dataset $D$
- Model $M$ with initial parameters $\theta_0$
- Hyperparameters $p_1$, $s_1$, $p_2$, $p_3$, and $n_cycles$
Objective: Minimize Negative Log Likelihood $\mathrm{NLL}(x_j)$
Steps:
- $\mathrm{PPLs}, \theta_{p1} \leftarrow \text{Learn}(\theta_0, D, p_1)$
- for $r = 1, 2, \ldots, n_cycles$ do:
- $\text{Sort}(\mathrm{PPLs}, D)$
- $S_1 \leftarrow (100 - s_1)%D$
- $\theta_{p2} \leftarrow \text{Concentrate}(\theta_{p1}, S_1, p_2)$
- $\mathrm{PPLs}, \theta_{p3} \leftarrow \text{Repeat}(\theta_{p2}, D, p_3)$ - return $\theta$
Where:
- Learn($\theta_0$, $D$, $p_1$): Trains on entire dataset for $p_1$ epochs
- Concentrate($\theta_{p1}$, $S_1$, $p_2$): Trains on selected difficult subset for $p_2$ epochs
- repeat($\theta_{p2}$, $D$, $p_3$): Retrains on full dataset for $p_3$ epochs
- $s_1$: Percentage of data to retain in Concentrate phase
- $n_cycles$: Number of Learn-Concentrate-repeat cycles
to understand the above, we need to understand the below.
How do we know what is “hard” to learn?
usually, when taking an exam u crammed for 8 redbulls ago, just before u feel the panic onset, you flip through all the questions and look for which ones are the “hardest”.
lets do the same in ML terms.
-
Basic Definitions
- A sequence of tokens: $s_i = {x_{i,1}, x_{i,2}, …, x_{i,n}}$
- Each data block has length 1024 tokens
- Total number of blocks: $N$
- Current training iteration: $t$
-
Perplexity-Based Sampling
First, calculate Negative Log Likelihood (NLL) for each token in sequence $s_i$:$$\mathrm{NLL}(x_{i,k}) = -\log P(x_{i,k} | x_{i,<k}; \theta_t)$$
where:
- $x_{i,k}$ is the $k$-th token in sequence $i$
- $x_{i,<k}$ represents all tokens before $k$ in sequence $i$
- $\theta_t$ are model parameters at iteration $t$
Then calculate perplexity for sequence $s_i$: †
$$\mathrm{PPL}i(t) = \exp\left(\frac{1}{|s_i|}\sum)\right)$$}^{|s_i|} \mathrm{NLL}(x_{i,k
Basic perplexity-based sampling probability: †
$$p_i^{\mathrm{basic}}(t) = \frac{\mathrm{PPL}i(t)^{\alpha}}{\sum$$ }^{N} \mathrm{PPL}_j(t)^{\alpha}
where $\alpha$ is the perplexity importance hyperparameter.
-
Dual-Criterion Sampling: Incorporating gradient magnitude:
$$g_i(t) = |\nabla_{\theta_t}\ell_i(\theta_t)|$$
where $\ell_i$ is the loss for block $i$
Combined importance function:
$$I_i(t) = \mathrm{PPL}_i(t)^{\alpha} \times g_i(t)^{\beta}$$
where $\beta$ is the gradient importance hyperparameter.
Final sampling probability:
$$p_i^{\text{dual}}(t) = \frac{I_i(t)}{\sum_{j=1}^{N} I_j(t)}$$
The complete sampling probability formula is thus: †
$$p_i^{\mathrm{dual}}(t) = \frac{I_i(t)}{\sum_{j=1}^{N} I_j(t)} = \frac{\mathrm{PPL}i(t)^\alpha \cdot g_i(t)^{\beta}}{\sum$$}^{N} \mathrm{PPL}_j(t)^\alpha \cdot g_j(t)^{\beta}
🟰
$$p_i^{\mathrm{dual}}(t) = \frac{\left[\exp\left(\frac{1}{|s_i|}\sum_{x_j \in s_i} -\log \mathrm{P}(x_j | x_{<j}; \theta)\right)\right]^\alpha \cdot |\nabla_\theta\ell_i(\theta(t))|^\beta}{\sum_{j=1}^{N} \left[\exp\left(\frac{1}{|s_j|}\sum_{x_k \in s_j} -\log \mathrm{P}(x_k | x_{<k}; \theta)\right)\right]^\alpha \cdot |\nabla_\theta\ell_j(\theta(t))|^\beta}$$
🟰
$$p_i^{\mathrm{dual}}(t) = \frac{\left[\exp\left(\frac{1}{|s_i|}\sum_{x_j \in s_i} -\log \mathrm{P}(x_j | x_{<j}; \theta)\right)\right]^\alpha \cdot |\nabla_\theta(-\log \mathrm{P}(x_i|x_{<i};\theta))|^\beta}{\sum_{j=1}^{N} \left[\exp\left(\frac{1}{|s_j|}\sum_{x_k \in s_j} -\log \mathrm{P}(x_k | x_{<k}; \theta)\right)\right]^\alpha \cdot |\nabla_\theta(-\log \mathrm{P}(x_j|x_{<j};\theta))|^\beta}$$
.
thank god for claude lmao tbt to writing these out by hand in grad school.
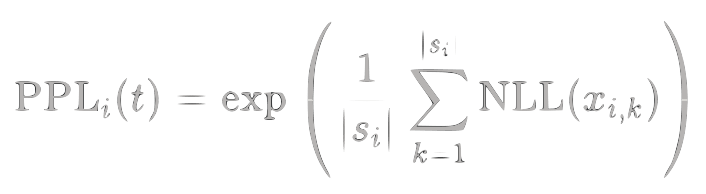{kind=link}
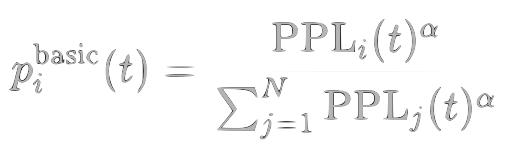{kind=link}
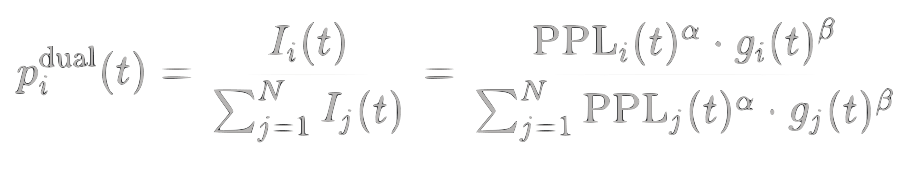{kind=link}
(re)Explanation of Parameters
-
$\mathrm{PPL}_i(t)$: The current (or moving-average) perplexity for data block $i$. Higher perplexity implies the model finds the block “harder.”
-
$|\nabla_\theta \ell_i(\theta(t))|$: The gradient magnitude with respect to parameters $\theta$, reflecting how much training signal block $i$ provides.
-
$\alpha$: A nonnegative hyperparameter that determines how strongly perplexity influences sampling.
-
$\beta$: A nonnegative hyperparameter that determines how strongly the gradient magnitude influences sampling.
side note, to handle large scale variations, we can introduce a normalize versions of both metrics: †
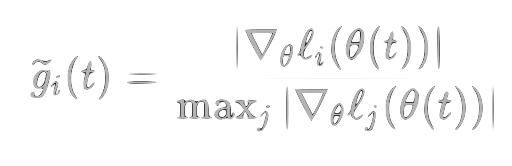{kind=link}
$$\widetilde{\mathrm{PPL}}_i(t) = \frac{\mathrm{PPL}_i(t)}{\max_j \mathrm{PPL}_j(t)}$$
$$\widetilde{g}i(t) = \frac{|\nabla\theta\ell_i(\theta(t))|}{\max_j |\nabla_\theta\ell_j(\theta(t))|}$$
The normalized importance function becomes:
$$I_i(t) = \widetilde{\mathrm{PPL}}_i(t)^\alpha \cdot \widetilde{g}_i(t)^\beta$$
Methodology
Let’s compare the GPT-2 model, trained with LFR, against the OpenAI baseline from huggingface in a five-shot setting bc i dont have the gpu credits nor patience for llama 420B.
For pretraining the GPT-2 models, you could choose the following combination of the aforementioned steps:
1. Phase 1: Learn for 1 epoch (p1 = 1).
2. Phase 2: Concentrate on 50% of the data for 1 epoch (s1 = 50, p2 = 1).
3. Phase 3: repeat the entire dataset for another epoch (p3 = 1).
4. Phase 4: Concentrate on 30% of the data for 5 epochs (n_cycles = 2, s2 = 70, p4 = 1).
To generate profiling information, u should record the data block ID (remember, each data block consists of 1024 tokens) and model perplexity each time a block is randomly sampled from the training corpus across all training iterations.
If you were to train the GPT2 345M model for 8 epochs, each data block will have at least 8 perplexity values captured at different training iterations. At the end of the training process, u’d have a record of the perplexities over time for each data block. From this record, classify each data block as one of the following:
1. Learned: recorded perplexities monotonically decrease.
2. Unlearned: recorded perplexities monotonically increase.
3. Forgotten: recorded perplexities first increase and then decrease.
Roughly 25% of data blocks are forgotten at least once during training and of the data blocks that are forgotten, 82% are forgotten multiple times during training, i.e., they display multiple descent behavior (Figure 1).
Results
i know ur monkey brain skipped the math, fk u i worked hard on that
anyway here r some pretty explications:
spaced repetion > gpt o1
| Subject | 1.5B-GPT2 | 1.5B-LFR |
|---|---|---|
| STEM | 24.5% | 26.1% |
| Humanities | 24.8% | 27.2% |
| Social Sciences | 24% | 23.8% |
| Other (business, health, misc.) | 27.8% | 25.1% |
| Average (across 57 subjects) | 25.3% | 25.5% |
Table uno: Accuracy results for the MMLU benchmark for LFR and the OpenAI Baseline for the 1.5B parameter model. Higher is better.
you might be like wtf its not that much better!!?!!?!?!?!?!
ur right, except ur wrong. the key thing here is that the time that it took to get to “parity” of around the same results for LFR went from 800k iterations to 40k.
a 20x boost.
and thats with shitty code.
for reference, the improvements in o1’s planning comes from the work of noam brown in planning. they found you can get a 15x reduction in number of steps needed – IF – you increase test time compute by 10x.
here i’m offering an algo that reduces by 20x with no strings attached (maybe some strings, idk). and again, thats with shity code.
“spaced repition is better than o1 search”
How does one know what was forgotten?
well if u read the methodology section and the “how do we know whats ‘hard’” section, which you’re reconsidering to do now, which you ultimately won’t actually do, which i’ll have to re-explain briefly, you’d know that “forgotten” facts (e.g. 9+10=21, actual examples in A.2) are hard bc they are high in perplexity (the uncertainty of output being correct) even after having already been learned.
for the ooga booga brained amongst you, this can visually learned by seeing that the perplexity score (PPL, not BBL) randomly increases at a later training epochs (running the same dataset back). aka they forgot the answer and are uncertain again.
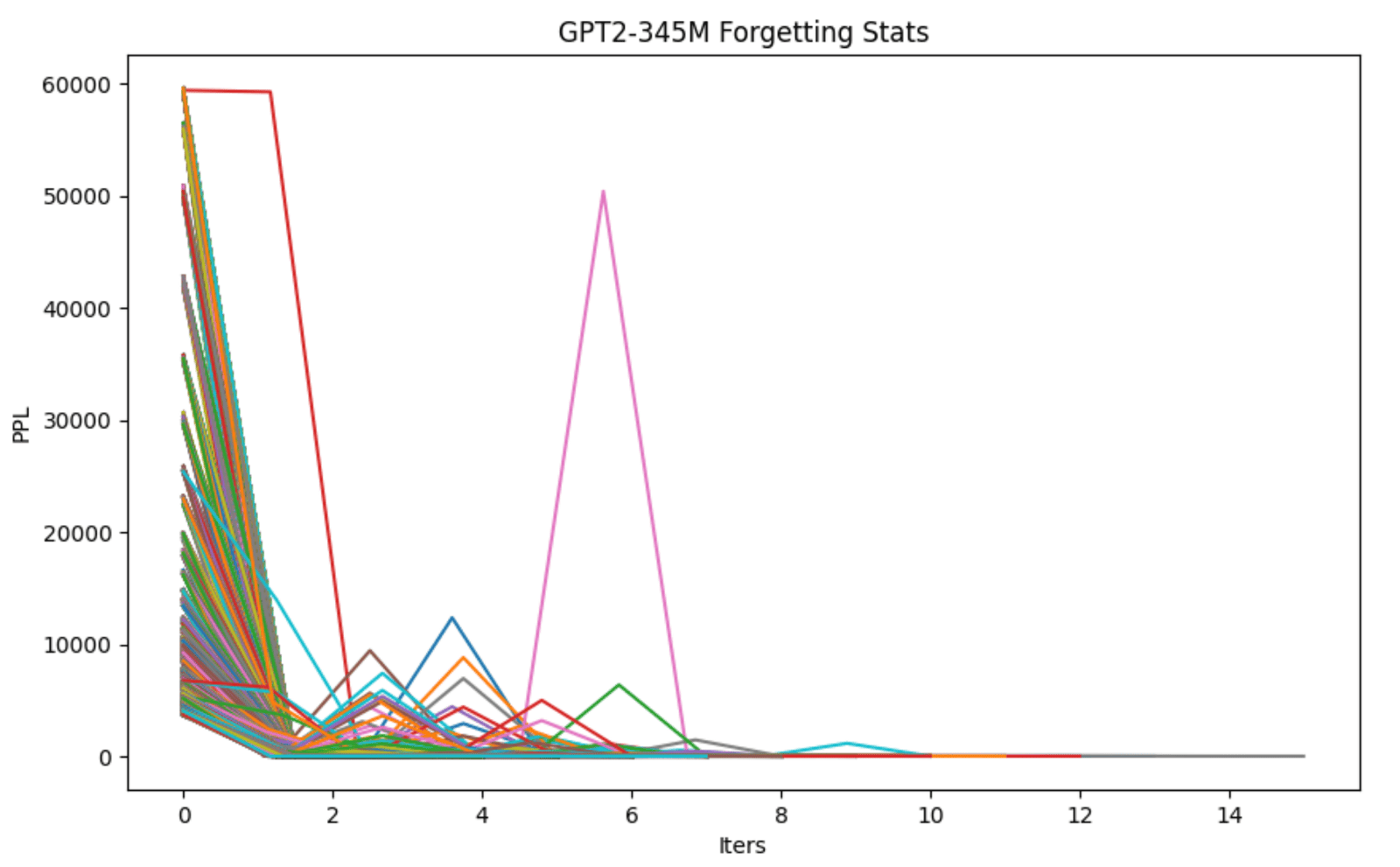
Figure uno: Perplexities of data samples being forgotton by the GPT2-345M model. Spikes mean it forgot the answer and became uncertain again. Lower is better.
In the training set, roughly 25% of all data blocks (1024 tokens) are forgotten. and it is almost always the “hard” facts. and its almost always the same ones, even after already having been “relearned”.
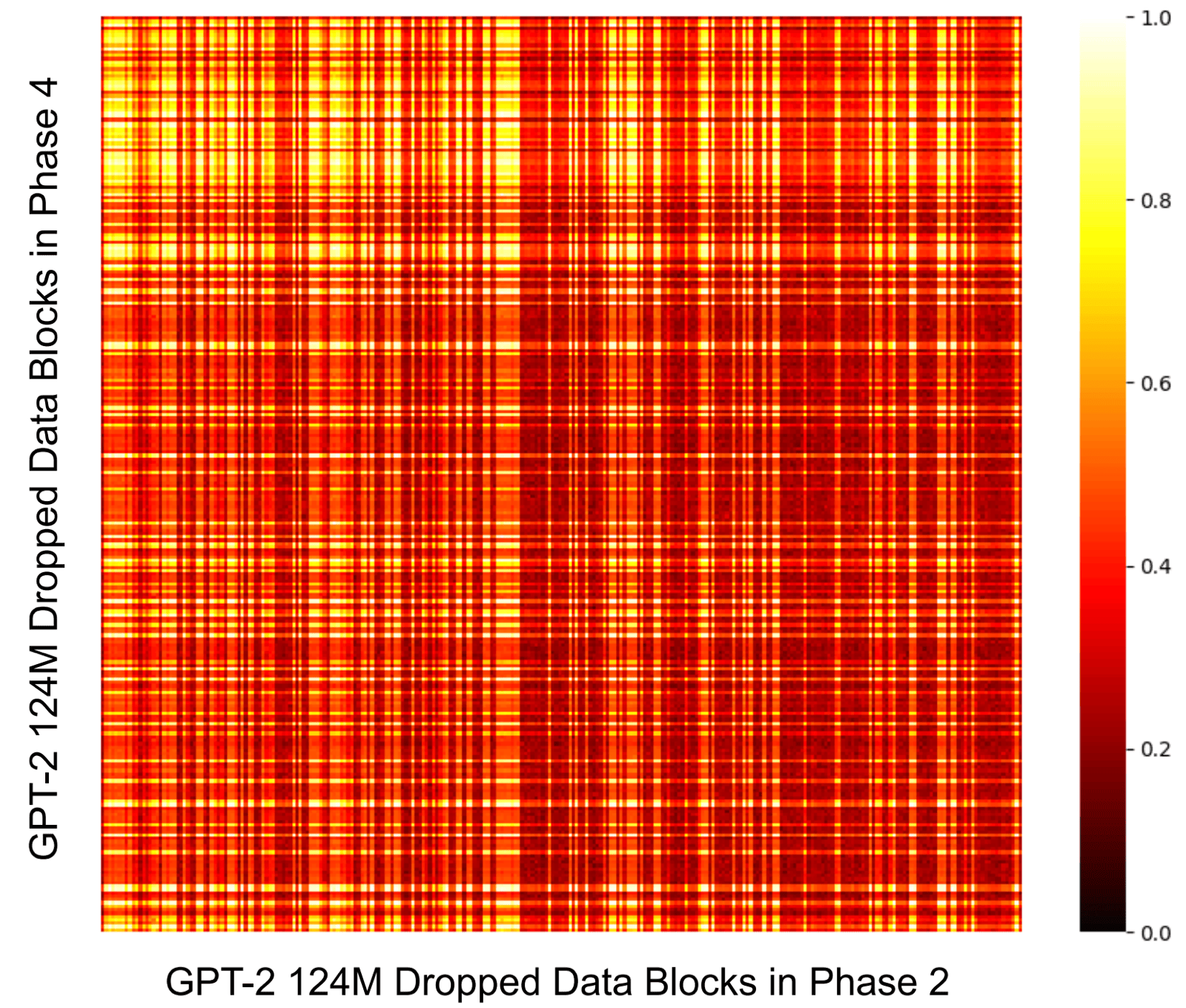
Figure dos: Cosine similarities of PPLs for each data block $i$. Higher = more similar.
This can be visually represented via a cosine similarity heatmap (how similar the uncertainty score was) for “hard” data blocks during phases 2 and 4 of pretraining for the GPT-2 124M model. A greater similarity in dropped data blocks over time (lighter color) indicates that it remained uncertain about similar data points.
feelings > facts
if u print out and go over all the texts dropped / retained in Phases 2 vs Phase 4 (first flashcard session vs $n^{th}$), and notice that text considered “easy” in phase 2 was more conversational, and those considered “easy” in phase 4 were more factual. (See examples in A.2)
This insinuates that the model first learned conversations and personal anecdotes, before being able to retain factual information. they’re just like us fr fr
ok what did we learn
- ☑️ GPTs that do spaced repetition can learn 20x faster
- ☑️ spaced repition is significantly better than o1 style planning/search
- ☑️ if o1 improved GPT4 by 50% (15/10), this could improve GPT4 by 2000%
- ☑️ GPTs forget about 25% of the data, mostly “hard” facts
- ☑️ “hard”-ness can be measured as perplexity score (how uncertain a model is about its output)
- ☑️ something data points are “hard” even after repeating their flashcard several times
- ☑️ GPT prioritizes learning how to handle conversations & anecdotes, then learns facts and esoteric information
- ☑️ AGI will not kill me bc i helped, right? @roko
tldr dual-criterion perplexity + gradient sampling generalizes spaced repetition principles to large language model training.
further reading
gwern has a bunch of papers in their literature review that are worth reading, if ur curious. here are some good ones and their abstracts:
- The New Organon – Francis Bacon (1620)
“If you read a piece of text through twenty times, you will not learn it by heart so easily as if you read it ten times while attempting to recite from time to time and consulting the text when your memory fails.”
- B. Tabibian, U. Upadhyay, A. De, A. Zarezade, B. Schölkopf, M. Gomez-Rodriguez, Enhancing human learning via spaced repetition optimization, Proc. Natl. Acad. Sci. U.S.A. 116 (10) 3988-3993, (2019).
We perform a large-scale natural experiment using data from Duolingo, a popular language-learning online platform, and show that learners who follow a reviewing schedule determined by our algorithm memorize more effectively than learners who follow alternative schedules determined by several heuristics.
- Smolen, P., Zhang, Y. & Byrne, J. The right time to learn: mechanisms and optimization of spaced learning. Nat Rev Neurosci 17, 77–88 (2016).
Spaced learning or training is robustly superior to massed [cramming] training for many forms of human learning and for virtually every animal model system that has been examined. The phenomenon has been a major focus of learning theorists for the past 50 years.
There are hundreds of studies involving the spacing effect:
-
Cepeda et al 2006 is a review of 184 articles with 317 experiments; other reviews include:
-
Ruch 1928, “Factors influencing the relative economy of massed and distributed practice in learning”
-
Crowder 1976, Principles of learning and memory
-
Dempster 1989, “Spacing effects and their implications for theory and practice”
-
Delaney et al 2010, “Spacing and testing effects: A deeply critical, lengthy, and at times discursive review of the literature”
-
Donovan & Radosevich 1999, “A meta-analytic review of the distribution of practice effect: Now you see it, now you don’t”
-
Greene 1992, Human memory: Paradigms and paradoxes
-
Janiszewski et al 2003, “A meta-analysis of the spacing effect in verbal learning: Implications for research on advertising repetition and consumer memory”
-
Pavlik & Anderson 2003, “An ACT-R model of the spacing effect”
-
Balota et al 2006, “Is Expanded Retrieval Practice a Superior Form of Spaced Retrieval? A Critical Review of the Extant Literature”
-
Carpenter et al 2012, “Using Spacing to Enhance Diverse Forms of Learning: Review of Recent Research and Implications for Instruction”
-
LessWrong: https://www.lesswrong.com/w/spaced-repetition
Appendix
Section 1: Da code
from dataclasses import dataclass
from typing import List, Optional, Dict, Tuple, Union
import torch
import torch.nn as nn
import numpy as np
from torch.utils.data import DataLoader, Dataset
from transformers import GPT2LMHeadModel, GPT2Config
import math
from torch.optim import Adam
from torch.optim.lr_scheduler import LambdaLR
@dataclass
class LFRConfig:
"""Configuration for LFR training"""
model_size: str # One of: "124M", "355M", "774M", "1.5B"
context_length: int = 1024
total_iterations: int = 40000
effective_batch_size: int = 512
block_size: int = 1024
weight_decay: float = 0.1
adam_beta1: float = 0.9
adam_beta2: float = 0.95
warmup_iterations: int = 2000
min_lr: float = 6e-5
max_lr: float = 6e-4
lr_decay_iters: int = 40000
# LFR specific parameters
alpha: float = 1.0 # Perplexity importance
beta: float = 0.5 # Gradient importance
p1_epochs: int = 1 # Initial learning phase
p2_epochs: int = 1 # Concentrate phase
p3_epochs: int = 1 # Repeat phase
s1_percent: float = 50.0 # Percentage of data to retain
n_cycles: int = 2 # Number of Concentrate-Repeat cycles
def __post_init__(self):
# Set model-specific parameters
model_configs = {
"124M": {"n_layer": 12, "n_head": 12, "n_embd": 768, "batch_size": 16, "grad_accum": 32},
"355M": {"n_layer": 24, "n_head": 16, "n_embd": 1024, "batch_size": 16, "grad_accum": 32},
"774M": {"n_layer": 36, "n_head": 20, "n_embd": 1280, "batch_size": 8, "grad_accum": 64},
"1.5B": {"n_layer": 48, "n_head": 25, "n_embd": 1600, "batch_size": 4, "grad_accum": 128},
}
self.model_config = model_configs[self.model_size]
class PerplexityTracker:
"""Tracks and computes perplexity for data blocks"""
def __init__(self, n_blocks: int):
self.n_blocks = n_blocks
self.block_ppls = torch.zeros(n_blocks)
self.block_counts = torch.zeros(n_blocks)
def update(self, block_ids: torch.Tensor, ppls: torch.Tensor):
"""Update running perplexity for blocks"""
self.block_counts[block_ids] += 1
self.block_ppls[block_ids] = ppls
def get_block_perplexities(self) -> torch.Tensor:
"""Get current perplexity estimates for all blocks"""
return self.block_ppls.clone()
class GradientTracker:
"""Tracks gradient magnitudes for data blocks"""
def __init__(self, n_blocks: int):
self.n_blocks = n_blocks
self.grad_norms = torch.zeros(n_blocks)
def update(self, block_ids: torch.Tensor, model: nn.Module):
"""Compute and store gradient norms for current batch"""
grad_norm = torch.norm(torch.stack([
p.grad.norm() for p in model.parameters() if p.grad is not None
]))
self.grad_norms[block_ids] = grad_norm
def compute_nll(logits: torch.Tensor, targets: torch.Tensor, ignore_index: int = -100) -> torch.Tensor:
"""Compute negative log likelihood loss"""
return nn.CrossEntropyLoss(ignore_index=ignore_index, reduction='none')(
logits.view(-1, logits.size(-1)), targets.view(-1)
)
def compute_perplexity(nll: torch.Tensor) -> torch.Tensor:
"""Compute perplexity from NLL values"""
return torch.exp(nll.mean())
class LFRTrainer:
def __init__(self, config: LFRConfig, model: nn.Module, train_dataloader: DataLoader):
self.config = config
self.model = model
self.train_dataloader = train_dataloader
# Initialize trackers
self.ppl_tracker = PerplexityTracker(len(train_dataloader.dataset))
self.grad_tracker = GradientTracker(len(train_dataloader.dataset))
# Initialize optimizer and scheduler
self.optimizer = Adam(
model.parameters(),
lr=config.max_lr,
betas=(config.adam_beta1, config.adam_beta2),
weight_decay=config.weight_decay
)
self.scheduler = self._create_scheduler()
def _create_scheduler(self) -> LambdaLR:
"""Create learning rate scheduler with warmup and decay"""
def lr_lambda(step):
# Linear warmup
if step < self.config.warmup_iterations:
return float(step) / float(max(1, self.config.warmup_iterations))
# Linear decay
decay_ratio = (step - self.config.warmup_iterations) / (
self.config.lr_decay_iters - self.config.warmup_iterations
)
return max(self.config.min_lr / self.config.max_lr, 1.0 - decay_ratio)
return LambdaLR(self.optimizer, lr_lambda)
def compute_sampling_probabilities(self) -> torch.Tensor:
"""Compute sampling probabilities for all blocks based on perplexity and gradients"""
ppls = self.ppl_tracker.get_block_perplexities()
grads = self.grad_tracker.grad_norms
# Combined importance scores
importance = (ppls ** self.config.alpha) * (grads ** self.config.beta)
# Normalize to probabilities
probs = importance / importance.sum()
return probs
def train_step(self, batch: Dict[str, torch.Tensor], block_ids: torch.Tensor) -> float:
"""Single training step"""
self.optimizer.zero_grad()
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
labels = batch["labels"]
# Forward pass
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs.loss / self.config.model_config["grad_accum"]
# Backward pass
loss.backward()
# Update trackers
with torch.no_grad():
nll = compute_nll(outputs.logits, labels)
ppl = compute_perplexity(nll)
self.ppl_tracker.update(block_ids, ppl)
self.grad_tracker.update(block_ids, self.model)
# Gradient accumulation
if (self.step + 1) % self.config.model_config["grad_accum"] == 0:
torch.nn.utils.clip_grad_norm_(self.model.parameters(), 1.0)
self.optimizer.step()
self.scheduler.step()
return loss.item()
def train(self):
"""Main training loop implementing LFR"""
self.step = 0
# Phase 1: Initial learning
for _ in range(self.config.p1_epochs):
self._train_epoch(use_full_dataset=True)
# Concentrate-Repeat cycles
for _ in range(self.config.n_cycles):
# Compute sampling probabilities
probs = self.compute_sampling_probabilities()
# Select subset of data for Concentrateed training
n_retain = int(len(probs) * (self.config.s1_percent / 100))
_, indices = torch.topk(probs, n_retain)
# Phase 2: Concentrate phase
for _ in range(self.config.p2_epochs):
self._train_epoch(subset_indices=indices)
# Phase 3: Repeat phase
for _ in range(self.config.p3_epochs):
self._train_epoch(use_full_dataset=True)
def _train_epoch(self, use_full_dataset: bool = True, subset_indices: Optional[torch.Tensor] = None):
"""Train for one epoch"""
dataloader = self.train_dataloader
if not use_full_dataset and subset_indices is not None:
# Create subset dataloader
subset_dataset = torch.utils.data.Subset(
self.train_dataloader.dataset, subset_indices.tolist()
)
dataloader = DataLoader(
subset_dataset,
batch_size=self.config.model_config["batch_size"],
shuffle=True
)
for batch, block_ids in dataloader:
loss = self.train_step(batch, block_ids)
self.step + = 1
if self.step >= self.config.total_iterations:
return
do u trust claude?
Section 2: Examples
The learning here is that phase 2 flashcards are “conversations” and phase 4 are “hard” facts – things that are harder to leran even after several spaced repitions.
| Phase 2 | Phase 4 |
|---|---|
| Become a fan of Slate on Facebook. Follow us on Twitter.The first time I crocheted a soccer ball was on the occasion of the 2010 World Cup. It was being held on the continent of Africa, and I thought the African Flower hexagon motif was the perfect vehicle for a crochet soccer ball celebrating the continent’s first time hosting the World Cup: This time around, instead of using all 9000 of my favorite colors, I limited myself to the colors of the flags of the thirty-two countries that had made it to the final rounds of the World Cup competition, and I did my best to incorporate the designs of their flags into the thirty-two hexagons and pentagons of a soccer ball. | ML-77 Missile Launcher: Based on existing technology, the ML-77 is a rapid-fire missile launcher using seeking projectiles. Each projectile features a friend-or-foe recognition system, ensuring it will find a hostile target even if the user’s aim is not completely accurate. The locking mechanism of the ML-77 allows the shooter to ignore cover and line of sight when shooting at locked on enemies, though an attack roll is still required. Locking on to an enemy requires a move action when the enemy is in line of sight and lasts for the rest of the encounter, or until a new target is locked. |
| In the book, the mythical California is ruled by Queen Califa and populated only with female warriors who brandish gold weapons. They even harness their animals in gold because it is the only mineral on the island. The legend of Califa and her island was well known among New World explorers. In 1536 when Hernán Cortéz arrived in Baja California, he believed he had landed on the legendary island. Over three hundred years later gold was discovered in California, making the legend partially true and earning the state its nickname: The Golden State | Segregated Witness, defined by Bitcoin Improvement Proposal 141 (BIP141), was deployed using an activation mechanism (BIP9) that requires 95 percent of all miners (by hash power) to signal support for the upgrade within the span of a two-week difficulty period. That’s at least 1916 blocks within 2016 blocks, to be exact. This threshold has just been reached. While the current difficulty period will not end until tomorrow, all blocks in this difficulty period are signaling support for the upgrade so far. This now totals over 1916 of them. |
| Unofficial reports claimed the car was powered by a 95kW 1.5-litre non-turbo petrol engine but Tada didn’t confirm. When asked what powers the S-FR Tada revealed he was considering three choices. “When you see the S-FR concept I suppose you imagine it is a 1.5-litre car but nowadays I can choose many kind of engines,” he explained. “Downsized turbo, 1.5-litre naturally aspirated and something additional as well. Now we are thinking which one is the best engine for a small sports car.” Tada also admitted that the company is unlikely to turn to a partner like it did with Subaru for the 86/BRZ or the new ’big brother’ sports car with BMW. | In April, MYIR released a Linux-powered MYS6ULX single board computer, which was notable for being available in two different versions using NXP’s low power, Cortex-A7 i.MX6 UltraLite (UL) or the more affordable, and almost identical i.MX6 ULL SoC. Now, MYIR has released an “MYB-6ULX Expansion Board” designed to stack onto either model. The $21.20 accessory adds a second 10100 Ethernet port to the MYS-6ULX, as well as new CAN, RS485, audio, micro-USB, RTC, and camera functions. MYB-6ULX Expansion Board with MYS-6ULX (left) and detail view (click images to enlarge). The MYB-6ULX Expansion Board has the same 70 x 55mm dimensions as the MYS-6ULX, which is available in two models: The i.MX6 UL based MYS-6ULX-IND has -40 to 85°C support instead of 0 to 70°C, and the i.MX6 ULL based MYS-6ULX-IOT features a USB-powered WiFi radio. The 4-layer expansion board runs on 5V power, and shares the industrial temperature support of the IND model. |
† = sometimes the formula doesnt display correctly. this has a backup/second life
published: 1-3-2025