change means opportunity

my goal with this (now 125+ page!) schpeel was to say that the economic covenant of the internet is breaking. we’re witnessing the end of a 30-year handshake deal that built the modern web. there’s a $316B search advertising bubble that’s about to pop. When AI agents browse the web on our behalf, never clicking through to websites, the entire economic model that funds the internet no longer works.
But change means opportunity. The collapse of the old model creates space for new ones. AI-native commerce, agentic interfaces, memory-driven personalization, and collaborative human-AI workflows represent enormous opportunities for those who build the infrastructure of what comes next. The window is narrow. The platforms that will define the next era of the internet are being built right now, by teams that understand both the depth of what’s breaking and the audacity required to build its replacement.
22,100. Thats the amount of musicians that made over $50k in royalties from spotify in 2024. thats a livable wage, and certainly couldnt have been possible ‘in the old days’. its def gotten better. the 100,000th-ranked artist on Spotify has seen their generated royalties multiply by over 10x (increasing from well under 600 USD in 2014 to almost 6,000 USD in 2024). but there are sooo many more artists (12 million) who are pursuing their creative passions (in reality its much more that aren’t on the platform), and earn almost nothing, trapped in a system where platforms extract the lion’s share of value while dangling the promise of discovery and audience reach.
most would point their finger at the platform and labels to yap that they squeeze all the revenue for themselves. this is why taylor swift wanted to separate from her label and pursue her independence, and why kanye, jayz, madonna etc created their own streaming company. It’s the same reason nebula was spun up by youtube creators: they were tired of losing nearly half of their potential revenue. patreon - headed by my fav cover band pomplamoose/scary pockets leader jack conte – was a last ditch resort to find new ways to compensate creators (akin to donationware in oss). These platforms represent early attempts to escape the coming collapse, but theyre rearranging deck chairs on the titanic.
it feels like everything is about to break. implode. a massive bubble is imminent. im not sure we realize what it means for the future of the social and economic contracts that have been at the base of how the internet works since its inception. hundreds of billions are at stake.
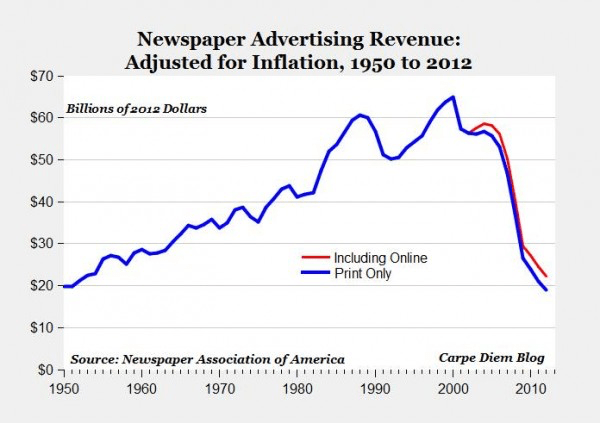
The first internet banner ad was bought by AT&T in 1994. This ad appeared on the website HotWired, which was the online version of Wired magazine. It marked the beginning of online advertising, a pivotal moment that has since evolved into a massive industry (~73% of $1.1T, 9% CAGR, most of which is going towards ‘the big five’, aka Big Tech). In 2017 it was already “massive” at $83B and 16% growth rate.
This digital advertising model, which powers ‘the big five’, is about to fking explode.
the incentive structure of internet has been driven by the handshake promise that google can use my content in return for traffic to my website where i can thereafter sell goods / services. we would add a robots.txt and cookies.txt that allow part of my website to be scraped and users to be tracked so that google could list me on their discovery engine, since navigating every website would be too cumbersome for a user. you can of course replace google with any of the other big five: meta, amazon, microsoft, and alibaba.
the idea is that once a google user is on my website, i could upsell them for other goods/services, like bundling nike shoes and socks for ‘marathon personas’, or insurance premiums for your home, roof and pet frog. this is the unwritten rule of loss leaders, hero products and accenture’s methodology of getting a foot in the door.
Brands pay exorbitant amounts to rank at the top for keywords like shampoo, Chinese food, and accounting firms so that they have the opportunity to fulfill the product/service request (and upsell) thereafter. Companies that didn’t join this race often got overshadowed by those that did, as seen with the success of Zappos in online shoe retail, NYT with SEO headlines, and TripAdvisor in tourism. Much more on this later
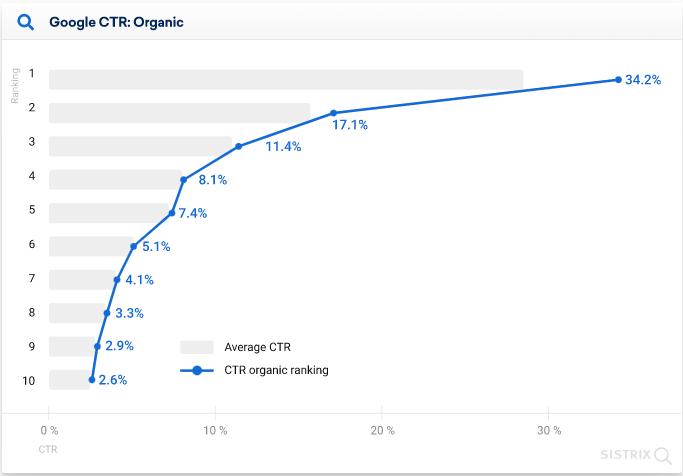
Figure: 96.2% of all clicks are on one of the top 10 links.
concretelely, a human inputs a few words and the genie search platform will conjure 10 blue links for users to navigate until they find their answer. for decades this was called ‘googling’. If you multiply the estimated 13 to 16 billion daily searches google processes daily by the 17.1% boost of being the top ranked link, it makes sense that brands pay in aggregate ~$175 billion in search ad revenue to drive traffic to their site.
But if a Google AI Overview or ChatGPT agent browses on the user’s behalf and returns the answer, why would the human continue onto the brand websites? this is the dramatic threat. Sama says they’re now handling a staggering 2.5 billion prompts every day, with 330 million daily queries coming from the U.S. alone. This is 1/6th of google’s volume. 8 months ago that figure was <1B … what rate will this continue to grow at?
in the future there is no reason for the customer to continue onto the website once theyve retrieved their answer. this is the catalyst for the implosion.
we are getting the answer and then moving on.
is this inevitable? what is required to enable this? what does it mean for the future of commerce, advertising and user experiences? Is there a generational startup opportunity? I’m not sure, but I’d like to find out.
history

In the beginning there was nothing. big primordial void. im gonna skip ahead a couple years past the grunting apes to when we codified a set of sounds to represent observed objects and experiences. Functionally, we were communicating (transferring) information: nearby danger, territorial claims, etc. This happened mostly orally, with some hand waving and a lot of bonking.
To no ones modern surprise, the scalability of conveying information to the entire population orally is infeasible within a life time. some bloke was fed up with managing record keeping through a game of telephone and decided to write onto a slab of rock the Kish tablet. Writing is important because it unlocked the rate at which information could be consumed. 2(+) people could read it at the same time. at any point in the day. without blud even being there. plus the information was (literally) set in stone - no one could mishear things.
However, writing itself had a bottleneck: duplication. To reach a wider audience, written material had to be manually copied or moved, which limited the dissemination of ideas. for a couple thousand years, ppl would just show up to the town square or have many scribes reproduce the works - no wonder so many religious monks had commentaries on the commentaries. The invention of the printing press unlocked duplication by stamping the same pages over and over. This is particularly important because (until 1440 - tho china figured it out in the 800s) only powerful institutions with the manpower could disseminate (and contril) ideas. to no ones postmodern surprise, the second major use of the printing press was porn.
Ok now we got consumable information, duplicatable at close to 0 marginal cost. the next bottleneck was
distribution: getting written information into the hands of the public was still a complex task. steam-powered printing presses drastically reduced the cost of printing and enabled newspapers to produce large volumes of copies at a lower price. The “Relation aller Fürnemmen und gedenckwürdigen Historien” in Germany, and the “Gazette” in France, provided regular updates on news, events and information to the masses.
The bottleneck of distribution gradually got less restrictive until the internet made distribution virtually free and accessible to everyone. Additionally, it was global. There were no physical or geographical limitations anymore. This is a major crux of this manifesto: infinite distribution + commoditization = personalization.
Before we go any further, there is an important milestone that I jumped over. Between the written mediums of newspapers and the internet, there existed (still exists?) the proliferation of ideas and information through radio and television. This is very very noteworthy because (for the first time outside of church) we would hear (and eventually see) information directly from its source, immediately. no next day paper. now.
There still remains two challenge: the creation and substantiation of ideas. while I can have numerous ideas and the Internet allows me to distribute them globally, I still need to write them down, just as artists need to create images and musicians need to compose songs. It is becoming increasingly evident that this bottleneck is also on the brink of being eliminated. Ill get to this later, but tldr: AI.
the history of ads

One of the earliest known ads was found in Thebes, Egypt, promoting a reward to capture and return a runaway slave named Shem. Since then, we have paid a very heavy price.
During the 1500s, print ads mainly focused on promoting events, plays, concerts, and products like books and medicines.
The first newspaper advertisement was published on April 17, 1704, in the Boston News-Letter, promoting an estate for sale. In 1741,
none other than the face of the $100 bill himself, pioneered magazine advertising in his ‘General Magazine’ booklet. Ben, frankly, this was a founding moment. In 1835, the very first billboard advertisement was created by Jared Bell in New York to promote Barnum & Bailey Circus.tbt to when zoos were cool and exotic

In 1841, Volney B. Palmer, the first ad agency, was established in Philadelphia. Instead of having to sell ads and build relationships with multiple newspapers, advertisers could work with the ad agency, which could leverage its connections with all those newspapers and serve multiple clients.
Radio gained significant popularity during and after World War II, but the first paid radio ad aired on August 22, 1922, on the New York City radio station, WEAF. The 15-minute ad, paid for by a real estate company called the Queensboro Corporation, promoted apartments in Jackson Heights, Queens. Later, the first television commercial aired in 1941 by the Bulova Watch Company. You can watch it here. It was ten seconds long and viewed by ~4,000 people in New York (#viral?).
The usefulness of ad agencies only grew as more advertising formats like radio and TV emerged. Particularly with TV, advertisers not only needed to place ads but also required significant help in creating them; ad agencies invested in ad-making expertise because they could apply this expertise across multiple clients. This led to the Golden Age of Advertising, where businesses made substantial investments in advertising to convey their brand’s uniqueness and engage their target audience.
Simultaneously, advertisers were rapidly expanding their geographic reach, especially after the Second World War; naturally, ad agencies expanded their reach as well, often through mergers and acquisitions. The primary business opportunity remained the same: provide advertisers with a one-stop shop for all their advertising needs.
Years later, after the development of ARPANET (1960s) and the World Wide Web (1989), the first online display ad was created in 1994 by AT&T, which asked users, “Have you ever clicked your mouse right HERE?” with an arrow pointing to text that read “YOU WILL.” The ad achieved a click-through rate of 44% - a figure that would astonish modern-day marketers. Fitting that the first ad was clickbait.

but why do ads actually work???
When the Internet came along, with its infinite distribution to infinite users, the newspapers, brands, and ad agencies were pumped af: more users = more money! Ad agencies in particular were frothing as more channels means more complexity and the ad agencies could abstract that away for their clients!
Before the Internet, a newspaper like the New York Times was limited in reach; now it can reach anyone on the planet! The problem for publishers, though, is that the free distribution provided by the Internet is not an exclusive. It’s available to every other newspaper as well. Moreover, it’s also available to publishers of any type. In the early internet (and to this day) individuals could post their own news updates, and to the indifferent HTML protocol, it was on ‘completely equal footing’.
That abundance of publications (blogs, webpages, brandsites, etc) meant that discovery was far more important than distribution.
So, two kids in a garage in palo alto decide to invent a way to rank pages, aptly called PageRank. Actually, much like the printing press, the groundwork was done in china. The first successful strategy for site-scoring and page-ranking was link analysis: ranking the popularity of a web site based on how many other sites had linked to it. Robert Li’s RankDex was created in 1996, filed for patent in 1997, granted in 1999, and then he used it to found Baidu in 2000. Larry Page referenced Robin Li’s work in the citations for PageRank.
Increasingly users congregated on two discovery platforms: Google for things for which they were actively looking, and Facebook for entertainment.
IRL
Start with the top 25 advertisers in the U.S. The list is made up of:
4 telecom companies (AT&T, Comcast, Verizon, Softbank/Sprint)
4 automobile companies (General Motors, Ford, Fiat Chrysler, Toyota)
4 credit card companies (America Express, JPMorgan Chase, Bank of America, Capital One)
3 consumer packaged goods (CPG) companies (Procter & Gamble, L’Oréal, Johnson & Johnson)
3 entertainment companies (Disney, Time Warner, 21st Century Fox)
3 retailers (Walmart, Target, Macy’s)
1 from electronics (Samsung), pharmaceuticals (Pfizer), and beer (Anheuser-Busch InBev)
Before going into Google and Facebook’s operating models more deeply, lets look to a more simple analog example. Buying the swiffer (Procter & Gamble’s cleaning mop stick thingy) in a Target. why do we decide to do so?
Ad agencies would say it is due to successful guidance through the Purchase Funnel, a concept initially introduced in 1925 in Edward Strong’s book, The Psychology of Selling and Advertising. The funnel is composed of: “attention, interest, desire, action, satisfaction”.
The real credit goes to E. St. Elmo Lewis, who in 1898 introduced the slogan, “Attract attention, maintain interest, create desire,” during an advertising course he taught in Philadelphia. He mentioned that he derived the idea from studying the psychology of William James. Later, he expanded the formula to include “get action.” Around 1907, A.F. Sheldon further enhanced it by adding “permanent satisfaction” as a crucial element. Although few in 1907 recognized the importance of this last phrase, today it is widely acknowledged as essential for providing service, gaining the buyer’s goodwill, meeting their needs, and ensuring lasting satisfaction.
Anyway,
- Attention: make the buyer aware of a problem they have
- Interest: the buyer becomes interested in solving their problem
- Desire: the buyer becomes interested in your solution to their problem
- Action: the buyer acquires your solution
A classic example of the complete AIDA model condensed into a single commercial is this roll-out campaign for the Swiffer mop
The entire funnel is encapsulated in this ad:
- Attention: Traditional cleaning methods stir up dirt
- Interest: Dirt needs to be removed, not just moved
- Desire: Swiffer cloths collect dirt and can be thrown away
- Action: Find Swiffer in the household cleaning aisle
The reference to the aisle is crucial: shelf space has long been the cornerstone for large consumer packaged goods companies. Swiffer achieved widespread distribution immediately upon launch because P&G could leverage its other popular products during negotiations with retailers like Walmart and Target to secure the best shelf location placement. Importantly, simply being on shelves increases the likelihood that customers will discover you independently or recognize you after repeated exposure. in ‘traditional retail advertising’ shelf space provided both distribution and discovery.
Notice that the vast majority of the industries on the list are dominated by massive companies that compete on scale and distribution. CPG is the perfect example: building a “house of brands” allows a company like Procter & Gamble to leverage scale to invest in R&D, reduce the cost of products, and target demographic groups without perfect personalization. TV is the perfect medium to cater to the masses. In fact, the top 200 advertisers in the U.S love TV so much that they make up 80% of television advertising, despite accounting for only 51% of total advertising spend (and 41% of digital).
Linear television and its advertisers were fundamentally based on controlling distribution (i.e. retail shelf space) and thereby controlling customers.
Many of the companies on this list are now under threat from the Internet. When supply was limited by physical space, shelves were highly valuable for both discovery and distribution. But with the Internet making shelf space virtually limitless, these brands can no longer monopolize the once-scarce shelf space. and I’m no mathematician, but it’s clear that trying to dominate an infinite space is a losing battle. Specifically:
- CPG companies face threats on two fronts: on the high end, the combination of e-commerce and highly-targeted, highly-measurable Facebook advertising has led to a rise in boutique CPG brands offering superior products to very specific groups. On the low end, e-commerce not only diminishes the shelf-space advantage but also sees Amazon making significant moves into private label products.
- Similarly, big box retailers that offer little beyond availability and low prices are being surpassed by Amazon in both areas. In the long term, it’s difficult to see how they will continue to survive.
- Automobile companies, on the other hand, are dealing with three distinct challenges: electrification, transportation-as-a-service (like Uber), and self-driving cars. The latter two, in particular (and to some extent the first), suggest a future where cars become mere commodities purchased by fleets, making advertising to customers obsolete.
Many of these major companies, consciously, unconsciously, or under the veil of ‘Hate Speech’, decided to boycott Facebook in 2020. Household brands like Coca-Cola, J.M. Smucker Company, Diageo, Mars, HP, CVS Health, Clorox, Microsoft, Procter & Gamble, Samsung, Walmart, Geico, Hershey and 1000 others decided to pull their spending on the app. Seems like a major blow, right? Zuckerberg was unphased.
For reference, 2019 Facebook’s top 100 advertisers made up less than 6% of the company’s ad revenue. Most of the $69.7 billion the company brought in came from its long tail of 8 million advertisers. This explains why the news about large CPG companies boycotting Facebook is, from a financial perspective, simply not a big deal.
Unilever’s measly $11.8 million in U.S. ad spend, to take one example, is replaced with the same automated efficiency that Facebook’s timeline ensures you never run out of content. Facebook loses some top-line revenue – in an auction-based system, less demand corresponds to lower prices. And yet, due to these lower prices, smaller direct-to-consumer companies can now bid and steal customers from massive conglomerates like Unilever. The content will be filled regardless, and the markets are very efficient.
The unavoidable truth is that TV advertisers are 20th-century entities: designed for mass markets, not niches, designed for brick-and-mortar retailers, not e-commerce. These companies were built on TV, and TV was built on their advertisements. While they are currently supporting each other, the decline of one will accelerate the decline of the other. For now, the interdependence of these models is keeping them afloat, but it only means that when the end comes, it will arrive more quickly and broadly than anyone anticipates.
Online
the traditional marketing funnel made sense in a world where different parts of the customer journey happened in different places — literally. You might see an advertisement on TV, then a coupon in the newspaper, and finally the product on an end cap in a store. Every one of those exposures was a discrete advertising event that culminated in the customer picking up the product in question in putting it in their (literal) shopping cart.
One of the hallmarks of the Internet is that the entire AIDA funnel can be often compressed into a single Facebook ad that you might only see for a fraction of a second; perhaps something will catch your eye, and you will swipe to see more, and if you are intrigued, you can complete the purchase right then and there. The journey is increasingly compressed into a single impression: you see an ad on Instagram, you click on it to find out more, you login with Shop Pay, and then you wonder what you were thinking when it shows up at your door a few days later. The loop for apps is even tighter: you see an ad, click an ‘Install’ button, and are playing a level just seconds later. Sure, there are things like re-targeting or list building, but by-and-large Internet advertising, particularly when it comes to Facebook, is almost all direct response. You might even forget about your purchase right up until a mysterious package shows up at your door a few days later.
Due to the format of these ads, digital advertising has worked much better for direct response marketing. Aka impulse purchases. Notice how this is a very different commerce behavior than having gone to Target, motivated by a TV ad + newspaper coupon, to examine the physical usefulness. Now:
- Facebook helps find the customers
- Shopify or WooCommerce build the storefronts
- Stripe or PayPal handle payments
- Third-party logistics providers package and ship the goods
- USPS, Fedex, and UPS deliver the actual packages
In the same way that the internet made the distribution and duplication of content indiscriminantly, facebook ads allows anyone to put an ad that can reach anyone. This has the same effect of creating perfect competition.
Here is the problem for DTC commerce: Facebook really is better at finding brands’ customers than anyone else. This alludes to Zuck’s endgame, but essentialy DTC ad budgets are forced onto facebook as it is the best (measured) return-on-investment for acquired customers on Facebook, where DTC companies are competing against all of the other DTC companies and mobile game developers and incumbent CPG companies and everyone else for user attention. That means the real winner is Facebook, while DTC companies are slowly choked by ever-increasing customer acquisition costs. Facebook is the company that makes the space work, and so it is only natural that Facebook is harvesting most of the profitability from the DTC value chain.
What made the Facebook model work is that the Meta Pixel (now CAPIs) could map a conversion (downloading of an app/purchasing the swiffer) to ad-targeted customers on their social media app. because Facebook knew a lot about someone who saw each ad and thereafter converted, they created an algorithm in 2013 that could easily find other people who were similar and show them similar ads (lookalike audiences). Along with the news feed, this was one of the biggest moments in Facebook’s history. From then on, they could use the data flywheel to continually optimizing their targeting and increasing their understanding along the way. Now Advantage+ is essentially a 1-click “set it and forget it”.
This has fundamentally changed the plane of competition: no longer do distributors compete based upon exclusive supplier relationships, with consumers/users an afterthought. Instead, suppliers can be commoditized leaving consumers/users as a first order priority. By extension, this means that the most important factor determining success is the user experience: the best distributors/aggregators/market-makers win by providing the best experience, which earns them the most consumers/users, which attracts the most suppliers, which enhances the user experience in a virtuous cycle.
Ben Thompson, Aggregation Theory (2015)
To be fair to the DTC companies, they are hardly the first to make this mistake: when the internet newspapers looked at the Internet and only saw the potential of reaching new customers; they didn’t consider that because every other publisher in the world could now reach those exact same customers, the integration that drove their business — publishing and distribution in a unique geographic area — had disintegrated. For a (long) time, Newspapers dominated both editorial and advertisements, but it turns out that was simply a function of who owned printing presses and delivery trucks; once the Internet came along advertisers, which cared about reaching customers, not supporting journalists, switched to Facebook and Google, which had aggregated the former and commoditized the latter. It is the same lesson that TV-era brands are facing now that they can’t just win by dominating shelf space. If some part of the value chain becomes free, that is not simply an opportunity but also a warning that the entire value chain is going to be transformed. How will brands adapt?
https://stratechery.com/2020/email-addresses-and-razor-blades/
Facebook, Amazon, Netflix, and Google (plus Uber/Airbnb etc) are structurally very similar companies: all leveraged zero distribution costs and zero transaction costs to own users at scale via a superior experience that commoditized suppliers and let them skim off the middle, either through fees, subscriptions, and/or ads.
Google, though, has a built-in advantage: Google doesn’t have to figure out what you are interested in because you do the company the favor of telling it by searching for it. The odds that you want a hotel in San Francisco are rather high if you search for “San Francisco hotels”; it’s the same thing with life insurance or car mechanics or e-commerce.
Amazon goes a step further and has effectively integrated the entire e-commerce stack when it comes to the distribution of goods consumers are explicitly searching for:
- Customers come to Amazon directly
- Searches on Amazon lead to Amazon product pages or 3rd-party merchant listings that look identical to Amazon product pages
- Amazon handles payments
- Amazon packages and ships the goods
- Amazon increasingly delivers the actual packages
This is great for aggregators like Google and Amazon, but not so great for P&G: remember, dominating shelf space was a core part of their strategy, and Amazon and Google have infinite shelf space! Anyone can publish, and this creates perfect competition - terrible for suppliers who face commoditization and shrinking margins, but great for consumers who enjoy more choices and lower prices.
gaming the algorithms
There are two big challenges when it comes to winning search:
- Because search is initiated by the customer, you want that customer to not just recognize your brand (which is all that is necessary in a physical store), but to also recall your brand (and enter it in the search box). This is a much stiffer challenge and makes the amount of time and money you need to spend on a brand that much greater.
- If prospective customers do not search for your brand name but instead search for a generic term like “laundry detergent” then you need to be at the top of the search results. And, the best way to be at the top is to be the best-seller. In other words, having lots of products in the same space can work against you because you are diluting your own sales and thus hurting your search results.
In order to survive on the Internet, an ugly truth was emerging. One has to cater to Google. They have all the customers. Yelp and countless other sites depend on Google to bring them web traffic — eyeballs for their advertisers.
Yelp, like many other review sites, has deep roots in SEO — search-engine optimization. Their entire business was long predicated on Google doing their customer acquisition for them. This meant a heavy emphasis on both speed and SEO, and an investment in anticipating and creating content to answer consumer questions. This includes using tools like SemRush and hiring SEO-specialized ad agencies to flourish online. And to their credit, since their founding in 2004, they’ve had great success in being the destination website for restaurant reviews and the sort.
You may think, are does anything even change if you play the SEO game? The answer is a big-time yes. Even a small boost at the scale at which google operates (13.7B searches/day, 5T/year), would be huge.
| Google Search Feature | Click Through Rate (CTR) |
|---|---|
| Ad Position 1 | 2.1% |
| Ad Position 2 | 1.4% |
| Ad Position 3 | 1.3% |
| Ad Position 4 | 1.1% |
| Search Position 1 | 39.8 § |
| Search Position 2 | 18.7% §§ |
| Search Position 3 | 10.2% |
| Search Position 4 | 7.2% |
| Search Position 5 | 5.1% |
| Search Position 6 | 4.4% |
| Search Position 7 | 3.0% |
| Search Position 8 | 2.1% |
| Search Position 9 | 1.9% |
| Search Position 10 | 1.6% |
- § If snippet, then 42.9%; If AI overview, then 38.9%; If local pack present, then 23.7%
- §§ If snippet, then 27.4%; If AI overview, then 29.5%; If local pack present, then 15.1%
Source: First Page Sage
But the data is more than just a small boost - the jump from 18.7% to 27.4% CTR is massive. For most companies, going from search position 8 to search position 3 (or vice versa) can make or break a business.
But AI Overviews (AIO) are existential threats to companies like Yelp. Look at what Chegg wrote in their 2024 Annual Financial Report:
While we made significant headway on our technology, product, and marketing programs, 2024 came with a series of challenges, including the rapid evolution of the content landscape, particularly the rise of Google AIO, which as I previously mentioned, has had a profound impact on Chegg’s traffic, revenue, and workforce. As already mentioned, we are filing a complaint against Google LLC and Alphabet Inc. in the U.S. District Court for the District of Columbia, making three main arguments. We allege in our complaint, Google AIO has transformed Google from a “search engine” into an “answer engine,” displaying AI-generated content sourced from third-party sites like Chegg. Google’s expansion of AIO forces traffic to remain on Google, eliminating the need to go to third-party content source sites. The impact on Chegg’s business is clear. Our non-subscriber traffic plummeted to negative 49% in January 2025, down significantly from the modest 8% decline we reported in Q2 2024.
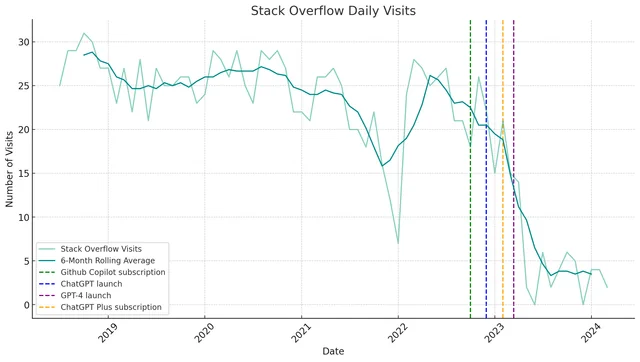
Theyre not the only one, Stack Overflow has taken a massive hit too. These companies relied on the handshake promise that google can use my content in return for traffic to my website where i can thereafter sell goods / services. Or at the very least display banner ads on their website.
In a 2014 video that Yelp put out, while it makes many of the same arguments as the Chegg lawsuit, instead of being focused on regulators it is targeting Google itself. They argue that Google isn’t living up to its own standards by not featuring the best results, and not driving traffic back to sites that make the content Google needs (by, for example, not including prominent links to the content filling its answer boxes; Yelp isn’t asking that they go away, just that they drive traffic to 3rd parties). Google may be an aggregator, but it still needs supply, which means it needs a sustainable open web.
Yelp, Chegg and Stack Overflow are not the first and not the last to be at the whims of Google. Back in 2006, Belgian news publishers sued Google over their inclusion in the Google News, demanding that Google remove them. After winning the initial suit, Google dropped them as demanded. Then the publications, watching their traffic drop dramatically, scrambled to get back in. That same year’s Field v. Google held that Google’s usage of snippets of the plaintiff’s content was fair use, and furthermore, that Blake Fields, the author, had implicitly given Google a license to cache his content by not specifying to Google to not crawl his website.
In 2014, A group of German publishers started legal action against the search giant, demanding 11 percent of all revenue stemming from pages that include listings from their sites. In the case of the Belgian publishers in particular, it was difficult to understand what they were trying to accomplish. After all, isn’t the goal more page views (it certainly was in the end!)? The German publishers in this case are being a little more creative: like the Belgians before them they are alleging that Google benefits from their content, but instead of risking their traffic by leaving Google, they’re instead demanding Google give them a cut of the revenue they feel they deserve.
The obvious reaction to this case, as with the Belgian one, is to marvel at the publisher’s nerve; after all, as we saw with the Belgians, Google is the one driving traffic from which the publishers profit. “Ganz im Gegenteil!” say the publishers. “Google would not exist without our content.” And, at a very high level, I suppose that’s true, but it’s true in a way that doesn’t matter, and understanding why it doesn’t matter gets at the core reason why traditional journalistic institutions are having so much trouble in the Internet era.
The ugly truth, though, as these newspaper publishers found out, is that not being in Google means a dramatic drop in traffic. No website can afford to exclude Google’s crawler from robots.txt because it would be economically ruinous. AI Overviews snippets in search (Google’s defense against AI-chatbot incursions into their search dominance) requires that if you want your content available to Google Search — and any publisher must — then your content will go into Google’s most important AI product as well.
Not everyone wants to play into Google’s game, though. Even when their ad business tanked 30% around the same time snippets were introduced, the New York Times wrote:
We are, in the simplest terms, a subscription-first business. Our focus on subscribers sets us apart in crucial ways from many other media organizations. We are not trying to maximize clicks and sell low-margin advertising against them. We are not trying to win a pageviews arms race. We believe that the more sound business strategy for The Times is to provide journalism so strong that several million people around the world are willing to pay for it. Of course, this strategy is also deeply in tune with our longtime values. Our incentives point us toward journalistic excellence … [yet] our journalism must change to match, and anticipate, the habits, needs and desires of our readers, present and future.
That raises the question as to what are the vectors on which “destination sites” — those that attract users directly, independent of the Aggregators — compete? The obvious two candidates are focus and quality. What is important to note, though, is that while quality is relatively binary, the number of ways to be focused — that is, the number of niches in the world — are effectively infinite; success, in other words, is about delivering superior quality in your niche — the former is defined by the latter.
The transformative impact of the Internet is only starting to be felt, which is to say that the long run will be less about traditional companies adopting digital than it will be about their entire way of doing business being rendered obsolete.
why now
It was a symbiotic relationship. Google benefited from being on THE place to find information. Users benefited by quickly finding what they needed. Websites and content creators benefited with larger audiences, focused and happy users, and a clear-cut path toward success. We all got what we needed out of the relationship.
Source: brob
As long as Google was providing ten blue links, it could serve everyone, no matter their values; after all, the user decided which link to click.
By providing ads alongside those ten blue links, Google deputized the end user to choose the winner of the auction it conducted amongst advertisers; those advertisers would pay a premium to win that auction because their potential customer was affirmatively choosing to go to their site, which meant (1) a higher chance of conversion and (2) the possibility of building a long-term relationship to increase lifetime value.
AI threatens this:
If a user doesn’t have to choose from search results, said user also doesn’t have the opportunity to click an ad, thus choosing the winner of the competition Google created between its advertisers for user attention. Because AI gives an answer instead of links, there is no organic place to put the advertisements, bid in its 4 SERP auctions. It is not that Google is artificially constraining its horizontal business model; it is that its business model is being constrained by the reality of a world where, as Pichai noted, artificial intelligence comes first.
In the world of AI Agents you must own the interaction point, and unfortunately there is no room for ads, rendering both Google’s distribution and business model moot. For Google, both must change for the company’s technological advantage to come to the fore.

Ben Thompson, India and Gemini: Ten Blue Links & The Complicity Framework (2024)
Additionally, when AI reduces the 10 blue links to one answer, if the subject rests on subjective values, the search result can never satisfy everyone, Google risks upsetting a significant portion of demand, weakening its Aggregator position and potentially decreasing its leverage on costs. For example, a WIRED analysis demonstrated that:
despite claims that Perplexity’s tools provide “instant, reliable answers to any question with complete sources and citations included,” doing away with the need to “click on different links,” its chatbot, which is capable of accurately summarizing journalistic work with appropriate credit, is also prone to bullshitting, in the technical sense of the word.
This undermines the trustworthiness of the AI Overview, and thus also information the end user consumes (and could therafter recite).
There are three major open threads here (opportunities?), which we’ll go into more in depth in the sections on AI Web, Human Interfacing and Economic Incentives.
what now?
What exactly is happening rn in search?
Sundar Pichai when asked about search volume in their 2024 Q4 Earnings Call:
On Search usage overall, our metrics are healthy. We are continuing to see growth in Search on a year-on-year basis in terms of overall usage. Of course, within that, AI overviews has seen stronger growth, particularly across all segments of users, including in younger users. So it’s being well received. But overall, I think through this AI moment, I think Search is continuing to perform well. And as I said earlier, we have a lot more innovations to come this year. I think the product will evolve even more. And I think as you make Search, as you give, as you make it more easy for people to interact and ask follow-up questions, et cetera, I think we have an opportunity to drive further growth. Our Products and Platforms put AI into the hands of billions of people around the world. We have seven Products and Platforms with over 2 billion users and all are using Gemini. That includes Search, where Gemini is powering our AI overviews. People use Search more with AI overviews and usage growth increases over time as people learn that they can ask new types of questions. This behavior is even more pronounced with younger users who really appreciate the speed and efficiency of this new format.
This echoes the “we built Google for users, not websites” Eric Schmidt ethos that Google generally adheres to. In Q1 2025 Pichai writes that they have 1.5B monthly active users using AI Overviews.
Ok so if there are no places to put Search Enging Result Page (SERP) ads anymore, but does that mean there’s no place to put ads at all? Of course not.
In the Perplexity pitch deck, Perplexity explains how their ads would show up as a side banner or a sponsored ‘follow up link’. In October, Google rolled out displaying ads alongside the AI answer (also see last week’s launch of NexAD for smaller AI search engines), much like what Perplexity pioneered a few months earlier. CBO Philipp Schindler reports positive results for AI search overview advertising:
First of all, AI overviews, which is really nice to see, continue to drive higher satisfaction and search usage. So, that’s really good. And as you know, we recently launched the ads within AI overviews on mobile in the U.S., which builds on our previous rollout of ads above and below. And as I talked about before, for the AI overviews overall, we actually see monetization at approximately the same rate, which I think really gives us a strong base on which we can innovate even more.
“We do have very good ideas for native ad concepts but you’ll see us lead with user experience…just like you’ve seen with YouTube, we’ll give people options over time, but for this year I think you’ll see us be focused on the subscription.” - pichai
Figure: Source: Alphabet Filings, MBI.*
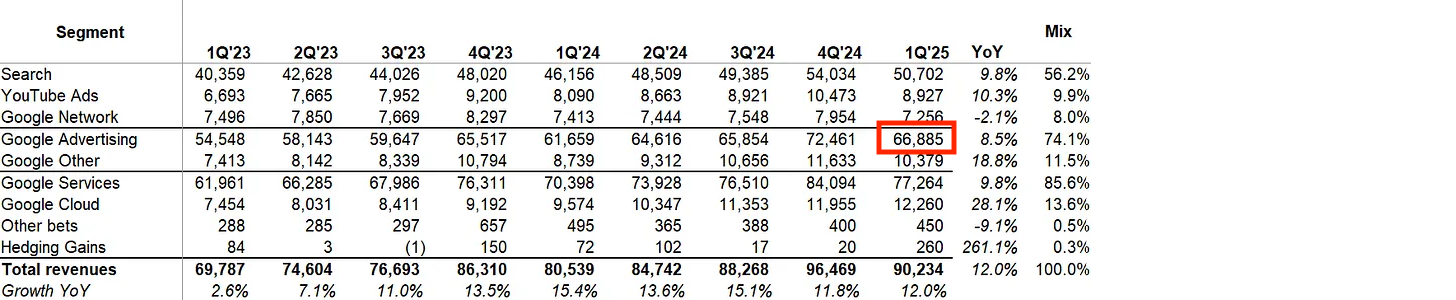
Although this is true, there is is some obfuscation to this truth. We can see that after the gradual rollout of AIO in Q4, Q1 reigned in $66,886M “approximately the same” as last year’s 61,659M. This is notably much less, though. An 8.47% YoY Growth is similar, sure, but also strictly worse than the previous year’s (61659÷54548) 13.03%.
Not only is it worse, but they’re hiding something very important - Cost Per Click has been increasing quite a bit. They cant do this forever.
Unfortunately, these are temporary fixes to a much larger problem.
Problem 1: human interfacing

Figure: Source: Alphabet Filings, MBI.*
Its one thing to replace human agencnies. Its another to replace human agency.
Yes, many of these ad agencies are built on helping brands like Proctor & Gamble find and market to their customers. Since the inception of the advertisement the goal has been to nudge customers to grow an affinity to and purchase their goods and services. Ads encourage the Attention, Interest, Desire and/or Action of purchasing behavior.
Search ads have always been a great place for advertisement because they catch users at a high intent moment. Meaning, a user is actively looking for something, and if you can provide the solution (according to their taste), theyll pick you!
One of the benefits of having 10 blue links was the choice. Users could be the arbiter of taste. Ads and SEO optimized links were entered into the arena of usefulness and the user could declare the victor. This was particularly relevant for Google, who could use a human’s click as a ranking parameter. Now, when an AI Overview is spitting out the answer, the search engine is the arbiter of taste.
This is problematic for two major reasons: Trustworthiness and Usefulness.
Trustworthiness
Google wants to “make information universally accessible and useful”. So, over the years, they’ve tried a bunch of stuff:

Each feature launch was an incremental improvement for Google’s search users. Search for a local restaurant, get a widget in the sidebar (nice and out of the way) with important information like the phone number, address, and even a link to the website. Nice!
All these changes make sense from the Google Side - Google ads became more important (and thus user engagement became more important), so Google wanted fewer users leaving the search page.
Seeing a 2 on the screen when a consumer enters 1+1 is handy, but it’s not without cost. If someone runs a calculator website, showing the 2 could lead to the calculator website’s traffic decline. Google must, therefore, make tradeoffs. These tradeoffs typically are good for users, but not always. As Eric Schmidt once said, “we built Google for users, not websites.” That’s reasonable, especially when it comes to immutable facts. Giving billions of users a quick answer to 1+1 seems like it outweighs the cost of lost traffic to the calculator website operator. But who decides that?
And what if its not true?!
Yes that seems silly to say when the quick snippet answer to 1+1= spits out 2, everyone can indeed agree it is truthful (fun fact it took Bertrand Russell and Alfred North Whitehead 300+ pages to prove this). But what if the “answer” being served up is best pediatrician mountain view ca?
Google will give you an answer: 10 blue links that point capture 99.37% of clicks. meaning, if you’re not in the top 10 ranked pediatricians, you wont get any business. And so SEO optimization games begin for attention capture and algorithmic blessing. These aren’t actually the best pediatricians in mountain view - theyre the best SEO optimized pediatricians in mountainview. This is untrustworthy in itself sure, but AI Overviews take this to another level because it draws from the gamified blue links and its own intuited world model.
When Google’s AIO came out, there was a HUGE problem with the trustworthiness of its answers. It would suggest putting glue on pizza to stop the cheese from sliding, smoking 2-3 cigarretes/day while pregnant and that it indeed violates antitrust law (wait that one actually might be true). See a funny compilation here. Even within their own official pitch deck, Perplexity’s AI answer includes a hallucination – the Studio Ghibli Museum isnt in Shinjuku, in fact, it isn’t even in Tokyo!
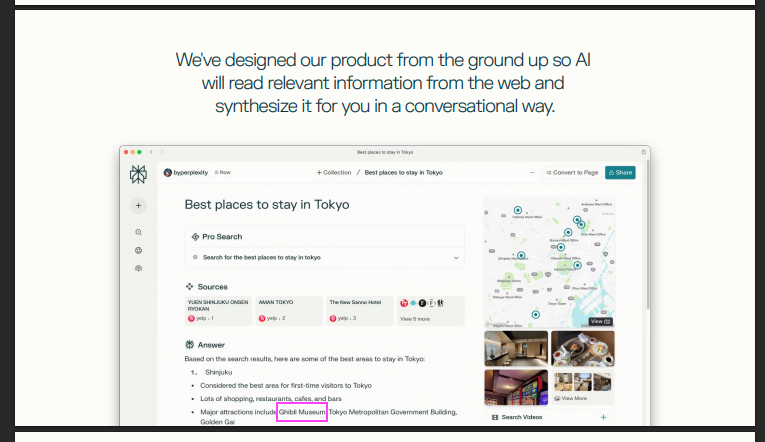
Figure: perplexity is a series Z company.
The web has a rich, competitive offering of services to help answer such a question, yet these search engines give themselves exclusive access to the prime real estate of the page, proclaiming ‘the best answer’ in its answer snippet. By doing this, user’s choices are being made for them. Your choice.
Are you worse off?
Its one thing to replace human agencnies. Its another to replace human agency.
Usefulness
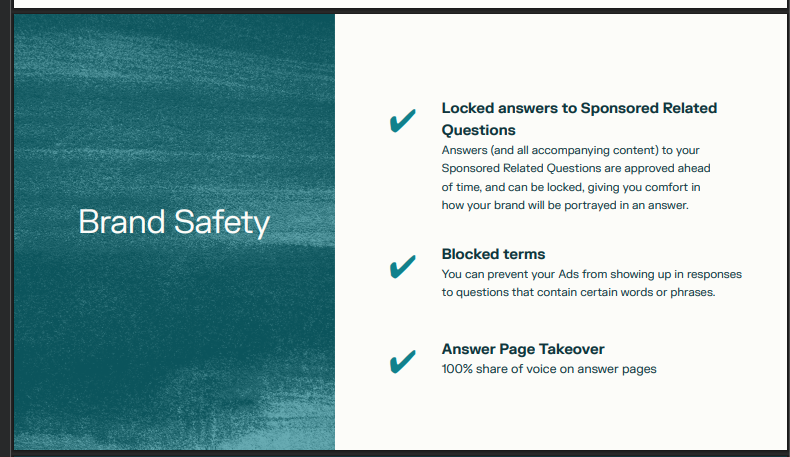
One could argue that a 100% brand takeover is fine if its useful. Lets say you search for a hotel in shinjuku, and the hilton takes over. What percentage of people would just ‘go with it’, without further research? Taking it a step further, what if the there is a One Click 🪄✨ Button?
If your answer (/intuition) is any greater than the % that wouldve selected the same hotel after self discovery, we’ve lost agency, obviously. But usefulness? Harder to measure, but we can look at the counterfactual. If people search through the ten blue links until they find something they are content with, navigating all the levers (price, distance, availability, (subjective) quality, etc), and the distribution of purchases of hotels is any different than that with a brand takeover, it means that some people didnt get their first choice. They were nudged into a suboptimal choice. In my personal opinion, this is evil.
In April 2024, Chief Business Officer Dmitry Shevelenko told Digiday about the plans for a road map focused on “accuracy, speed and readability.” Shevelenko added that the company didn’t plan to rank sponsors differently than organic answers. “The weighting will be the same. That’s our version of ‘Don’t Do Evil,’” Shevelenko told Digiday earlier this year. “We’re not going to buy us an answer. Whenever we have advertising, that’s the one thing we don’t do: You can’t pay us to have the answer be different because you’re paying us.”
That certainly makes sense for Perplexity, which has one other important factor working in their favor: relative to Google, Perplexity doesn’t have any revenue to lose. ChatGPT similarly claims it wont let you ‘buy an answer’:
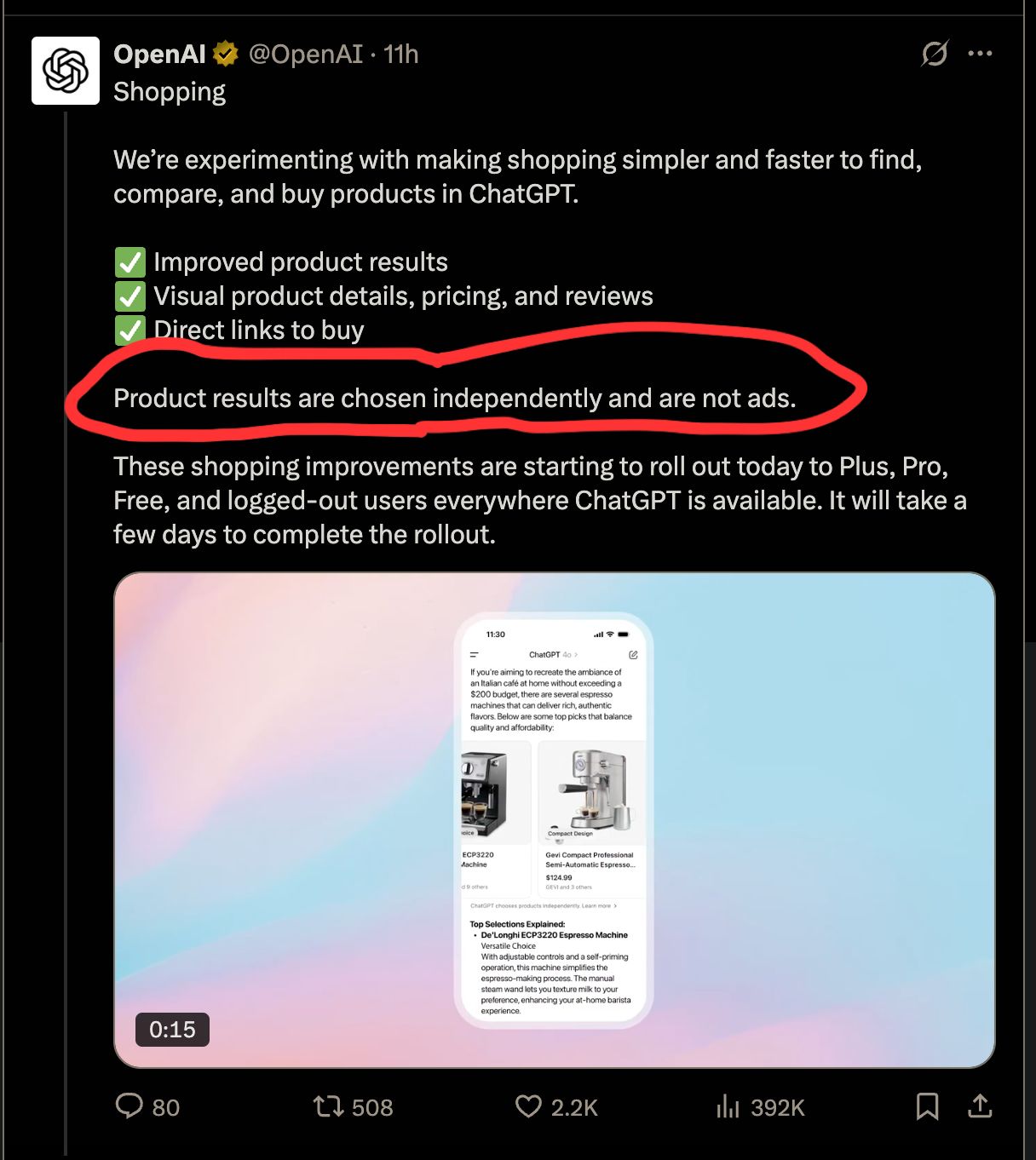
Figure: what happens when u usurp your core operating model.*
Yet its happening. Google announced a few days that it would pervasively display AIO ads. When does a banner ad taking up X% of the screen start having serious impacts on the freedom of choice? 1%->3%->10%->50%->100%? What about traffic to the websites?
The first customers will be major brand advertisers who are both not necessarily looking for a click, but rather to build brand awareness and affinity, and who have infrastructure in place for measuring that (and, helpfully, they have experimental budgets that Perplexity can tap into for now). Brands that have strict brand guidelines, know what keywords to omit and have the bandwith to write manual ‘Sponsor Related Questions’. By blowing large budgets on AI Overviews, these Fortune 200s can not only build consumer Awareness and Interest, but buy Actions that wouldn’t have otherwise taken place. It shouldnt be a surprise either, that these companies are more price inelastic when the search engines increase CPC.

On their pitch deck, Perplexity boasts a 46% Follow-up Question rate. They highlight this because it is one of the opportunities for ad placement, where you can place a website that encourages discovery (e.g. ‘best running shoes -> best running shoes for a marathon’). But to me that screams ineffectiveness: 46% of the time, the user is coming to the platform and not getting the answer theyre looking for (sure, yes, some percentage is discovery, but not all of it). As mentioned before, this points to the ugly truth that for most questions, one search result can’t satisfy everyone. It just isnt useful enough.
Its important to reiterate that with a single answer, we not only reliquishing agency of our choices to The Big Five, but get a suboptimal answer meant to satisfy everyone. In an AI-first world where “we are getting the answer and then moving on,” the multi-visit discovery phase vanishes, collapsing the critical revenue stream for both Google and content publishers. These problems are dialed up to 11 when there are no longer any humans browsing.
Problem 2: ai web
Where we started

The World Wide Web (1989) was built by humans, for humans, and it started with written text, because of course, we started with written text for distribution to the masses. As people began hyperlinking to each other’s websites, the web quickly became cluttered and ‘unparsable for humans’. Don Norman, one of many researchers exploring how people interact with computers in the 1990s, coined “User Experience” (UX) - a shift from focusing solely on aesthetics and/or functionality to considering the user’s needs and emotions.
Google’s subsequent intervention (drawing on Robin Li’s work) was a welcomed relief, bringing us back to human-legible designs. As we know from earlier, they iterated quite a bit to make information universally accessible and useful.
But things changed when agents began browsing the web.
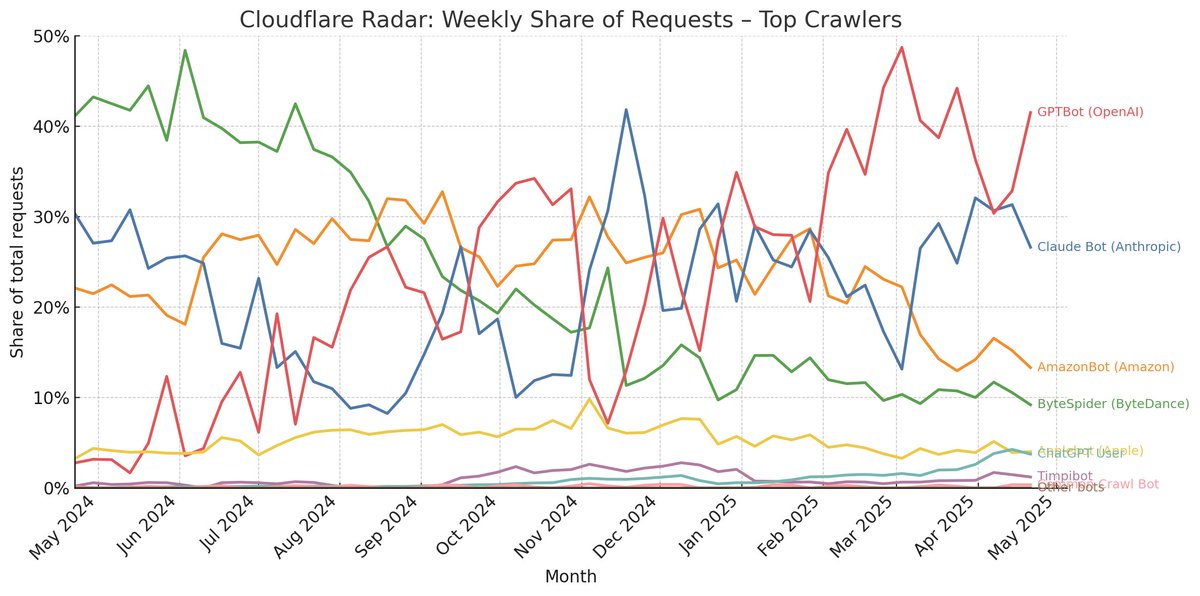
Figure: Source: Cloudflare Data Explorer
The Internet Archive announced back in 2017 that their crawler would ignore a widely accepted web standard known as the Robots Exclusion Protocol (robots.txt):
Over time we have observed that the robots.txt files that are geared toward search engine crawlers do not necessarily serve our archival purposes. Internet Archive’s goal is to create complete “snapshots” of web pages, including the duplicate content and the large versions of files. We have also seen an upsurge of the use of robots.txt files to remove entire domains from search engines when they transition from a live web site into a parked domain, which has historically also removed the entire domain from view in the Wayback Machine. In other words, a site goes out of business and then the parked domain is “blocked” from search engines and no one can look at the history of that site in the Wayback Machine anymore. We receive inquiries and complaints on these “disappeared” sites almost daily… We see the future of web archiving relying less on robots.txt file declarations geared toward search engines, and more on representing the web as it really was, and is, from a user’s perspective.
Maybe you can give them a pass, being a non-profit and all. But when these big AI companies started ignoring robots.txt, despite claiming that they don’t, things get complicated. Robb Knight at WIRED observed a machine — more specifically, one on an Amazon server and almost certainly operated by Perplexity — doing this on WIRED.com and across other Condé Nast publications. This, paired with clear regurgitations of NYT content by ChatGPT sparked a frenzy of lawsuits.

Figure: Source: The court case
OpenAI now lets you block its web crawler from scraping your site to help train GPT models. OpenAI said website operators can specifically disallow its GPTBot crawler on their site’s robots.txt file or block its IP address. “Web pages crawled with the GPTBot user agent may potentially be used to improve future models and are filtered to remove sources that require paywall access, are known to gather personally identifiable information (PII), or have text that violates our policies,” OpenAI said in the blog post. For sources that don’t fit the excluded criteria, “allowing GPTBot to access your site can help AI models become more accurate and improve their general capabilities and safety.”
Blocking the GPTBot may be the first step in OpenAI allowing internet users to opt out of having their data used for training its large language models. It follows some early attempts at creating a flag that would exclude content from training, like a “NoAI” tag conceived by DeviantArt last year. It does not retroactively remove content previously scraped from a site from ChatGPT’s training data.
Tbh this news isnt a solution. Call me cynical, but that last line explains why: OpenAI has already benefited from all of the data on the Internet, and established a norm that sites can opt out of future AI models, whicih cements the advantage of being a first mover and throws the ladder behind them. Since that announcement, GPTBot hasnt slowed down at all, as shown in the above image on crawlers. The opt out is nice, but its not like most publishers know how to update their robots.txt. Plus, who knows what economic impact of opting out these publishers would face.
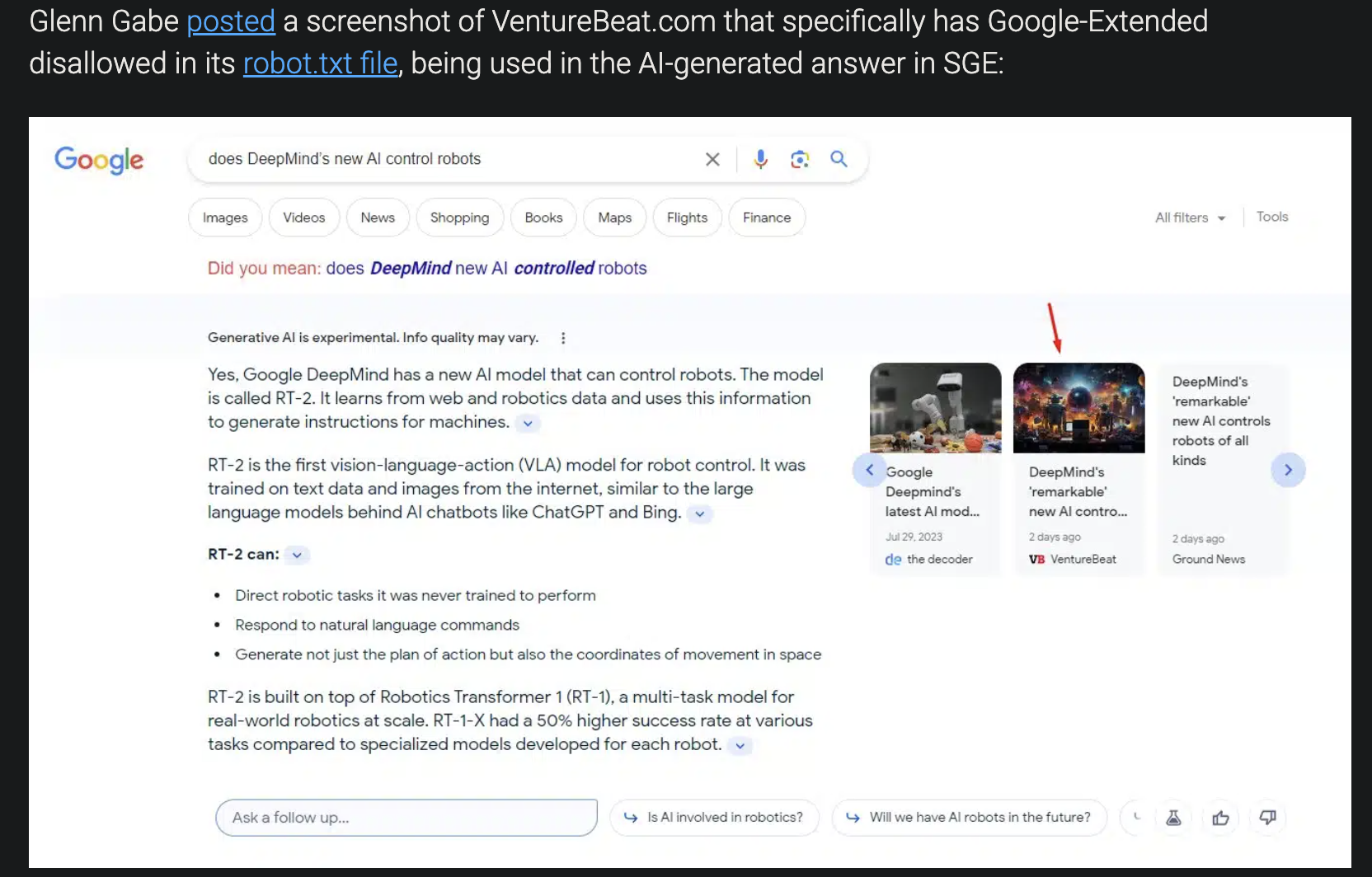
its not like its stopping them from displaying the text in AIO either source
History seems to be rhyming with the German and Belgian publishers 20 years ago. Additionally, if these publishers are not increntivized, to continue giving content to these AIs, are we the stuck in the 2010s internet forever?
Keep in mind that it’s unclear that crawling Internet data is in any way illegal; I think there is a strong case that this sort of data collection is fair use, although the final determination of that question will be up to the courts (e.g., Shutterstock, NYT, Sarah Silverman vs OpenAI & friends). What is certain is that OpenAI isn’t giving the data it collected back.
Where we’re going
Beautiful Soup (bs4) and Selenium have been widely used for testing and automating interactions with web applications. These tools have been instrumental in allowing developers to extract data and simulate user interactions (e.g. what happens when you get the Reddit Hug of Death). 🅱️rowserBase took these tools and made them much more scalable and efficient by abstracting much of the complexity involved in setting up and managing browser instances via the cloud, allowing developers to focus on the logic of their automation tasks. One such task can be penetration testing, sure, but lately a new question is emerging.
What happens when AI agents start browsing on our behalf?
Take a moment to watch this agent buy their human a sandwich via 🅱️rowserbase’s headless browser:
Figure: Source: Evan Fenster on X the everything app
Notice how the AI never stopped or clicked on an ad. The agent had a task, and executed it.
This task was simple enough, as the order and supplier were explicit. But what happens when someone asks their AI Agent to “buy them a red sweater”? We’ll explore more of what the solution requires here, but lets focus on the ad problem in this section.
How should google count these impressions? If they stepped away to brew some coffee, would the user even know about any ads on the websites the agent browsed? Should they?
In a similar vein of questioning, Openai and Perplexity have ‘promised’ to never let you buy an answer, but what happens when the AI Overview / first link upon ‘red sweater’ search result is an ad? This very quickly rehashes the earlier problems of trustworthiness and usefulness.
Taking this a step further: remove the web browser interface altogether. Where are you going put the ads? In the GET requests between Shopify and Openai APIs?
There are a lot of questions here with no clear answers. However, their answers in the pre-Agentic Web era were the foundation on which attribution and discovery were fueled. These measurable ‘bounce rates’, ‘time on site’, etc were what Google, Meta, Shopify & friends used to measure the effectiveness and conversions of ads on their platform. Its all about to be uprooted with ‘personal agents’.
The decline of ads is approaching quicker than we think, first with the decline of publishers, and then with the decline of websites altogether.
Problem 3: the incentives
| Title | Link | Outcome |
|---|---|---|
| Ahrefs Study on CTR Decline | Google AI Overviews Hurt Click-Through Rates | 34.5% drop in CTR for top organic positions when AI Overviews are present. |
| Amsive Research on CTR Impact | Google AI Overviews Hurt Click-Through Rates | Average 15.49% CTR decline across 700,000 keywords; up to 37% drop for non-branded queries. |
| Raptive Estimate on Traffic and Revenue Loss | Why Publishers Fear Traffic Ad Declines from Google’s AI-Generated Search Results | AI Overviews could reduce publisher visits by up to 25%, leading to $2 billion in annual ad revenue losses. |
| Swipe Insight Report on Traffic Decline | Google’s AI Overviews Cause Publisher Traffic Decline Estimated $2B Ad Revenue Loss | Some publishers experienced up to a 60% decrease in organic search traffic due to AI Overviews. |
| World History Encyclopedia Case Study | AI Took My Readers: Inside a Publisher’s Traffic Collapse | Observed a 25% traffic drop after content appeared in AI Overviews. |
| WARC Study on CTR Reduction | AI Overviews Hit Publisher Traffic Hard, Study Finds | Organic click-through rates dropped to 0.6% when AI Overviews are present, compared to 17% for traditional links. |
| Bloomberg Report on Independent Websites | Google AI Search Shift Leaves Website Makers Feeling Betrayed | Independent websites have seen significant declines in traffic due to AI-generated answers. |
| eWeek Analysis on Web Traffic Decline | Google AI Overviews SMB Impact | Some website owners experienced up to a 70% decline in web traffic following AI Overviews introduction. |
| Northeastern University Insight | Google AI Search Engine | AI Overviews could reduce website traffic by about 25%, particularly affecting web publishers reliant on search traffic. |
| Press Gazette Warning on Publisher Visibility | Devastating Potential Impact of Google AI Overviews on Publisher Visibility Revealed | AI Overviews could dramatically impact publisher traffic and ad revenue, especially in health-related queries. |
The foundational handshake of the internet, where content creators exchange their material for traffic and potential revenue, is being shattered by AI overviews that eliminate the necessity for users to visit original content sites. The many studies above, as well as the many previously mentioned (Chegg, Stack Overflow and Yelp), highlight a 15-35% decline in click-through rates (CTR) when AI Overviews are present, with some publishers experiencing up to a 70% decrease in organic search traffic.
Publishers, once riding high on search engine traffic, are now staring down a harsh new reality: their content is being consumed without any direct interaction. Publishers are missing opportunities to sell their goods and services.
This isn’t just about losing ad revenue; it’s about survival.
If these publishers (bloggers, newspapers, scientific research, how-to articles, etc.) no longer exist, or are less incentivized to create high-quality content due to cost savings, the consequences are dire. The pool of information that search engines rely on would become increasingly scarce, or diminish in quality and diversity. As publishers struggle to monetize their efforts, the incentive to invest in high-quality content creation wanes. This scarcity could lead to a homogenized internet landscape dominated by AI-generated content, which often lacks the depth, nuance, and originality that human creators provide. Ryan Broderick writes in Fast Company: “Why even bother making new websites if no one’s going to see them?”

Figure: Source Cision
As revenue becomes increasingly sparse, its understandable that (though these publishers will never admit to it) LLMs are very much generating content on their platforms. Either as a first draft or final draft, publishers first used the AIs to help produce for their long tail (SKU descriptions, sports coverage, etc). As we get more and more AIs publishing, the Dead Internet conspiracy becomes even more real. G/O Media faced social media backlash for using AI to produce articles in 2024, with readers describing the move as “pure corporate grossness” and criticizing the publication of “error-filled bot-authored content.” They ended up selling almost all their portfolio newspapers (including The Onion to my mentor Jeff Lawson, hi jeff <3) and laying off much of their staff. Similarly, when CNET published AI-generated articles without clear disclosure, leading to widespread criticism over factual errors and plagiarism. The controversy resulted in staff layoffs, unionization efforts, and a significant devaluation of the brand. In August 2024, Ziff Davis acquired CNET for 100 million USD, a stark drop from its previous valuation ($1.8B).
Quick Math
Ok lets recapulate and determine just how much $ is up in the air.
Lets deconstruct the global digital advertising market into the affected products. In 2023, Google’s share of digital advertising revenues worldwide was projected to amount to 39 percent. Facebook followed with a projected digital ad revenue share of 18 percent, while Amazon came in third with an expected seven percent. The player from Asia with the highest share is TikTok, with three percent, followed by Baidu, JD.com, as well as Tencent, all three with two percent. Lets break that down.
Global ad spend hit $1.1 trillion in 2024.
Digital formats account for roughly 72.7% of total ad spend, i.e. $790 billion.
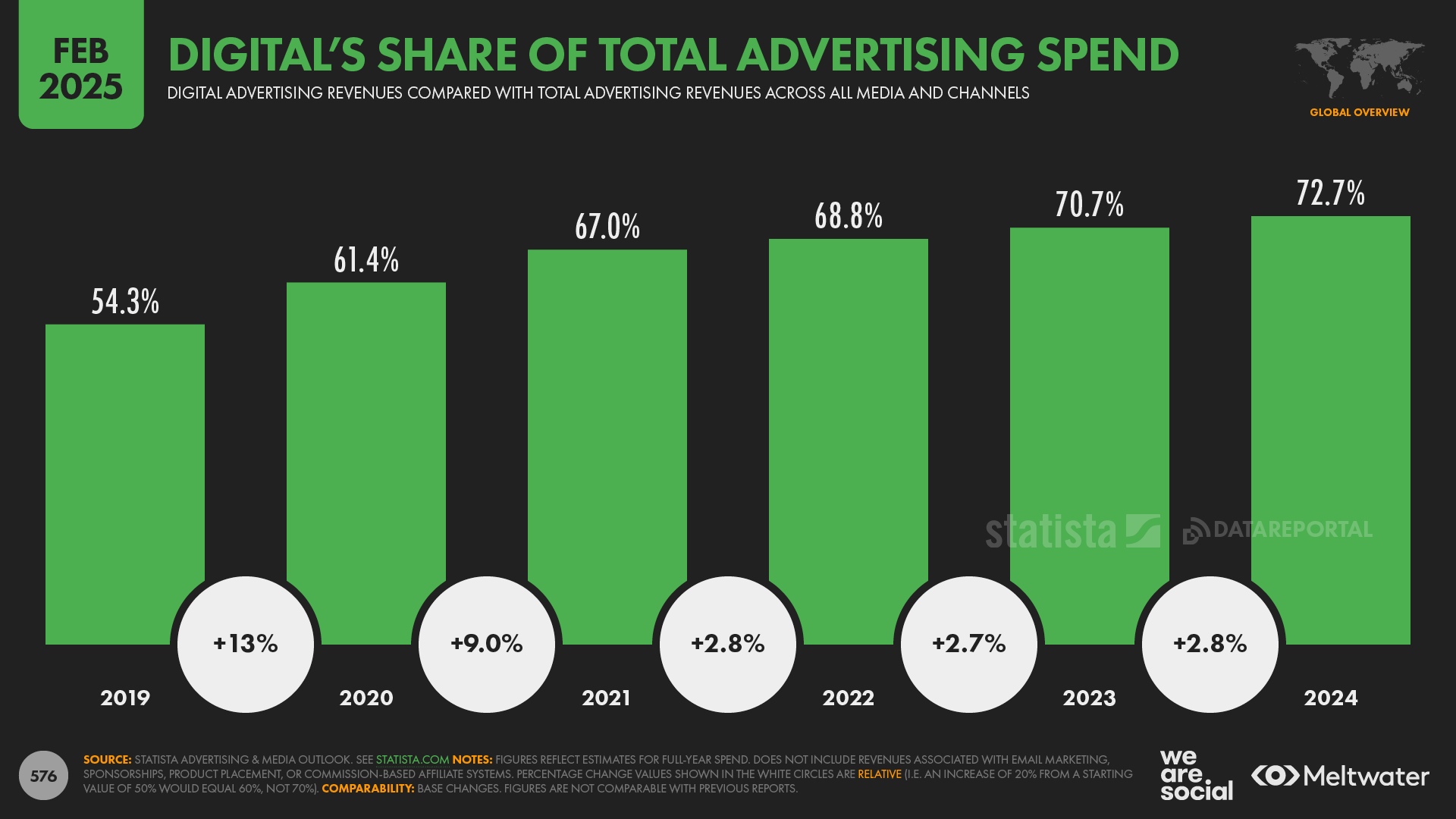
Figure: Source Cision
We can split this into two major spend types: search (SERP) and display (banners, rich media, video).
search ads
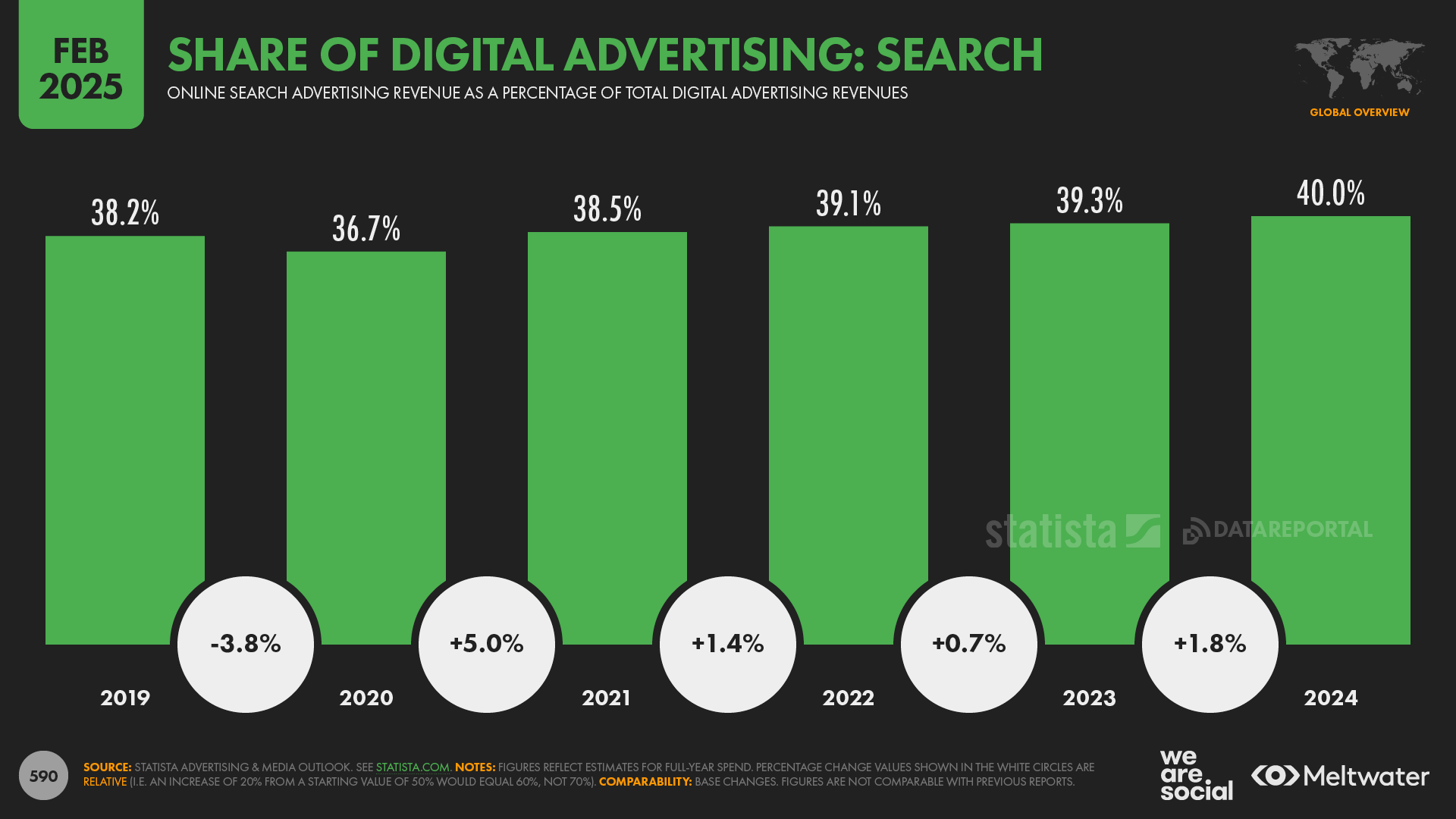
Figure: Source Cision
Obviously, all these numbers are estimates but statista claims 40% of digital spend goes to search, emarketer says 41.5%, and oberlo says 41.4% which means its somewhere in that ballpark. lets just go with the conservative numbers → $316 B
2025 search marketshare, has Google: 89.66% Bing: 3.88% Yandex: 2.53% Yahoo: 1.32% DuckDuckGo: 0.84% Baidu: 0.72% Others: 1.05%. But you can’t just distribute the add spend proportionally, since that would omit the other major search platform, retail.
According to eMarketer, 49% of Internet shoppers start their searches on Amazon, and only 22% on Google; Amazon’s share is far higher for Prime subscribers, which include over half of U.S. households.
Putting it altogether:
| Search Platform | Ad Spend (2024) | Reference |
|---|---|---|
| Google Search (SERP) | $198.1 B | Alphabet 2024 Annual Report |
| Amazon on-site Search | $56.22 B | Jungle Scout: Sponsored Products ≈ 78 % |
| Alibaba on-site Search | $25.2 B | Encodify: $42 B; 60%? is on-site search |
| Walmart Connect Search | $3.5 B | AdExchanger: $4.4 B global ad rev; 80%? on-site search |
| eBay Promoted Listings | $1.47 B | eBay Q4 “first-party ads” $368 M × 4 quarters |
| Target | $0.49 B | Marketing Dive: $649 M Roundel rev; 75%? is product-ad/search |
| Other search engines and retailers (Bing, Yandex, Baidu, etc) |
$43.4 B | Remainder |
| Totals | $316 B |
all of this is going to be seriously challenged by the AI Search renaissance.
display ads
Display ads (banners, rich media, video) represent about 56.4% of digital spend → $461.07 billion.
By 2025 programmatic channels will handle 90% of display ad budgets; assuming a similar rate for 2024, that was roughly $414.96 billion in programmatic display spend
Global affiliate marketing spend (performance-based links driving publisher commissions) will exceed $15.7 billion in 2024
Sponsored content (native, branded articles/videos) in the US alone tops $8.14 billion this year
In total, the combined spending on display ads, programmatic channels, affiliate marketing, and sponsored content is ~$438.8 billion in 2024.
Ad tech fees (exchanges, SSPs, DSPs) typically consume ~30% of programmatic budgets. If publishers capture the other ~70%, that implies 438.8B × 0.7 ≈ $307.16 billion in programmatic display‐ad revenue flowing to publishers. The flip of this is the 131.64B in revenue that the ad industry doesn’t get either.
to single out google’s AdSense for Content program, publishers keep about 68% percent of the revenue. Which, if Google’s programmatic‐platform market share is 28.6% → 111.5 B, publishers receive ~$75.8 B.
According to Gamob, Google’s search revenue sharing network, The Search Partner (AdSense for Search) represents roughly 10% of google’s total revenue. According to the actual 2024 anual report filing, it was closer to 8.67% ($30.36B). Publishers earn 51% of partner-network ad revenue → $15.18 B. Yandex, Yahoo, etc., offer limited or no comparable search-partner revenue-share programs, so we treat their downstream to external publishers as negligible for this estimate.
If we add google’s 198.08B from search, 30.36B from display and youtube/CTV’s 36.15B, it precisely equates to the 61659+64616+65854+72461=$264.59B in 2024 ad revenue we had in the figure back when we were discussing the slowing 8.47% YoY Growth in ad revenue, mitigated by increasing CPC costs. beautiful. whats gonna happen to it? what about these other companies?
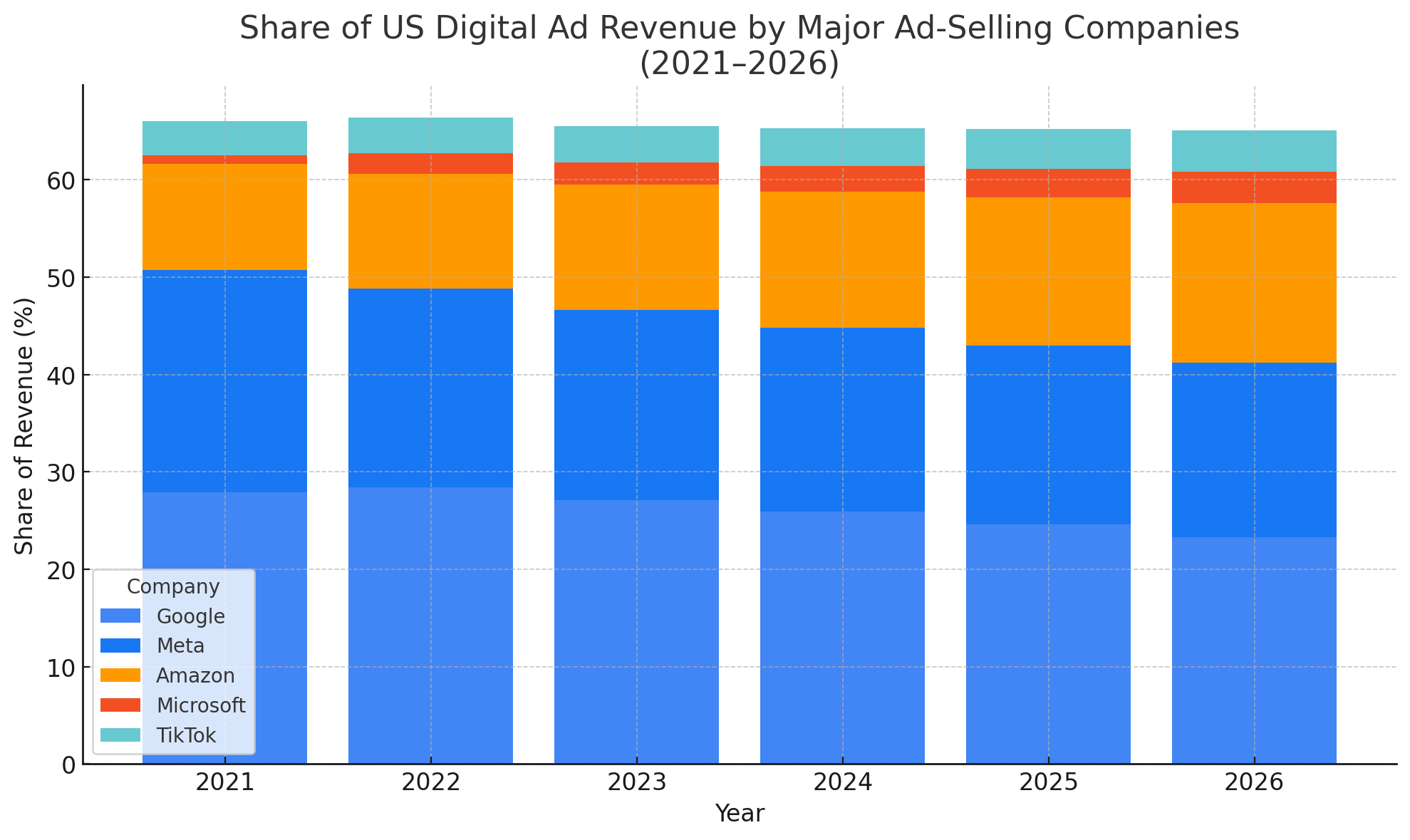
Figure: Source: math + claude viz
where to next?
ok so the economic model of the internet is broken. #genz yay 🙄
the incentives of publishers are no longer to produce high quality content, unless they want to game the algorithm to rank higher in AI Overviews (Generative Engine Optimization) and/or sign a faustian contract to let the algorithms pilage their articles.
when we look for information on the internet, the AI Overviews are not truthful not useful when they give us suboptimal or entirely false answers in the pursuit of ad placements or serving a majority of users.
All that was back when we were using human interfaces - increasingly so, agents are interfacing with the internet on our behalf.
Plus, whats gonna happen to the $316B in search spend? What will Proctor & Gamble gamble on? What will happen to the publishers that are no longer rewarded for web traffic with (~100B in) revenue sharing, and more importantly, can no longer (up)sell their products via their website?
trends
one of the ways to figure out what to do next is to see where things are heading more generally. we should look at what is possible now that previously wasn’t possible due to the advent or convergence of multiple innovations that collectively lead to generational companies. The lineage lines are very clear if you know your history:
Alexander Bell’s advent of the telephone in 1876 came off the convergence of telegraphy (morse code) adoption, electrification progress and the increasingly cheap railroad/wood costs to build poles that could vary the intensity of electric currents to replicate sound waves. With this development of electric signal broadcasting infrastructure, and the utility of instant communicatiton in WW1, broadcasting voice to many users (not just 1-1) was quickly adopted leading to radio’s pervasiveness. 40 years later as cost of producing visual media fell (e.g. photographs instead of paintings), it became more feasible to transmit not just voice but also images over long distances, leading to the first television broadcasts. Early television systems used mechanical methods, such as spinning disks, to scan and display images. With Steven Sasson’s (1975) realization that images could be captured AND stored electronically (by using a increasingly cheap CCD image sensors) he packaged the nobel prize invention with cassete tapes into a toaster sized 8lb portable digital camera.
The Bell Telephone Company established a vast conglomerate and monopoly in telecommunication services until ‘Ma Bell’ was forced to break up in 1982 due to antitrust regulations. This monopoly was based on the pre-allocation of network bandwidth, which involved assigning radio frequencies to different applications. During the Cold War, to prevent the public broadcasting of sensitive data, DARPA initiated the development of ARPANET. ARPANET was built on the foundation of packet-switching, TCP/IP protocols, and IMP routers. This ‘alternative’ to traditional telecommunications was progressively adopted by the university researchers that created it and eventually led to the creation of the web as we know it today. As mentioned earlier, it was important that these data packets sent and received were legible, so Tim Berners-Lee’s developed aa global hypertext system for information sharing. That information, text, voice or the now digial images ‘permitted’ Napster to share music files over the internet from one ‘peer-to-peer’. It was a shortlived movement, from 1999-2001 but revealed the public’s hunger for on-demand, personalized, frictionless access to media, decoupled (decentralized) from traditional broadcast and retail gatekeepers.
But what if, instead of downloading the (music/text/etc) data packets to my floppy disks, I could just host media on the public web and have people stream directly? Great question, YouTube founders. In 2005, as internet bandwidth became capable of file transfers at megabits per second, and Macromedia’s (later, Adobe) 1996 invention of Flash (RIP 1996-2020) enabled interactive websites, simple upload-and-share interfaces democratized video (text/music/etc) publishing while its streaming capabilities eliminated the need for complete downloads before viewing. In 2007, a certain turtlenecked individual merged all of the progress that made PCs more affordable/compute efficient, a digital camera, telephony compliance and internet browsing into (you guessed it) the iPhone. All founders have to mention it at some point, forgive me, but hopefully you can see why its such a landmark moment. Take a moment to bask:
Figure: Source: Evan Fenster on X the everything app
The iPhone revolution, via its app store, permitted social graphs, image sharing and instant news/information sharing that still struggles to satiate the public thirst. Driven by the now vast data published, cloud-distributed computing resources, and rehashed algorithmic research from the 70s, machines could learn patterns (in images, search intent, or entertainment). Its gotten to the point that it can even generate its own entertaining media, or answers to search queries as we very well know by now.
toys
The reason big new things sneak by incumbents is that the next big thing always starts out being dismissed as a “toy.” This is one of the main insights of Clay Christensen’s “disruptive technology” theory. This theory starts with the observation that technologies tend to get better at a faster rate than users’ needs increase. From this simple insight follows all kinds of interesting conclusions about how markets and products change over time.
Disruptive technologies are dismissed as toys because when they are first launched they “undershoot” user needs. The first telephone could only carry voices a mile or two. The leading telco of the time, Western Union, passed on acquiring the phone because they didn’t see how it could possibly be useful to businesses and railroads – their primary customers. What they failed to anticipate was how rapidly telephone technology and infrastructure would improve (technology adoption is usually non-linear due to so-called complementary network effects).
The same was true of how mainframe companies viewed the PC (microcomputer). Initially, PCs were seen as toys for hobbyists, incapable of the kinds of serious business applications that IBM handled. Yet, as software and hardware rapidly improved along the exponential curve of fabs doubling the number of transistors on a microchip approximately every two years, PCs became indispensable tools in both personal and professional settings.
Kodak made a lot of money with very good margins providing silver halide film; digital cameras, on the other hand, were digital, which means they didn’t need film at all. Kodak’s management was thus very incentivized to convince themselves that digital cameras would only ever be for amateurs. Kodak filed for bankrupcy in 2012.
YouTube’s early days featured grainy, amateur videos that serious media companies considered amateurish and irrelevant. “Broadcast yourself” seemed like a frivolous concept when the first videos were cats playing piano and awkward vlogs.
The first iPhone was ridiculed by BlackBerry executives for its poor battery life, virtual keyboard, and limited enterprise features. “It’s a toy for consumers,” panned by the likes of Microsoft’s Steve Ballmer — who laughed off its lack of a physical keyboard.
Early apps were basic utilities and games like “iBeer” (a virtual glass of beer) or keeping the flashlight on. Friendster, MySpace, and Facebook were considered trivial diversions for teenagers — mere digital yearbooks with Farmville and the ability to “poke” each other. Established media companies and advertisers dismissed them as fads, failing to see how these networks would become primary channels for news distribution, customer engagement, and political discourse. Steve Jobs saw right through this, watch this launch of Garageband:
Figure: Source: Evan Fenster on X the everything app
[12:24] I’m blown away with this stuff. Playing your own instruments, or using the smart instruments, anyone can make music now, in something that’s this thick and weighs 1.3 pounds. It’s unbelievable. GarageBand for iPad. Great set of features — again, this is no toy. This is something you can really use for real work. This is something that, I cannot tell you, how many hours teenagers are going to spend making music with this, and teaching themselves about music with this.
A couple years later, facebook left the world wide web to go mobile native. They were pegged as a way to play toy apps and video games. From TechCrunch in 2012:
Facebook is making a big bet on the app economy, and wants to be the top source of discovery outside of the app stores. The mobile app install ads let developers buy tiles that promote their apps in the Facebook mobile news feed (e.g. Farmville, Plants vs Zombies). When tapped, these instantly open the Apple App Store or Google Play market where users can download apps.
Much of the criticism of app install ads rests on obsolete assumptions that view apps as fun baubles instead of the dominant interaction layer between companies and consumers. If you start with the premise that apps are more important than web pages or any other form of interaction when it comes to connecting with consumers, being the dominant channel for app installs seems downright safe.
https://stratechery.com/2015/daily-update-bill-gurley-wrong-facebook-youtubes-competition/
Almost all early efforts of AI were to play recreational games like chess, Go, and poker. OpenAI started by training models to beat DoTA champions. These EXACT same algorithms power website ranking elos, protein folding research, and ChatGPT’s reasoning models. LLMs started with recipes and toy use cases but are maturing into enterprise use cases (starting, of course, with “fresh grad” tasks). the landmark AI Agent paper was about playing minecraft, and you can go watch Claude Play Pokemon right now.
Disruptive innovation is, at least in the beginning, not as good as what already exists; that’s why it is easily dismissed by managers who can avoid thinking about the business model challenges by (correctly!) telling themselves that their current product is better. The problem, of course, is that the disruptive product gets better, even as the incumbent’s product becomes ever more bloated and hard to use. That, though, ought only increase the concern for Google’s management that generative AI may, in the specific context of search, represent a disruptive innovation instead of a sustaining one.
AI
It’s become increasingly clear that AI is not a toy, and will become a defining pillar for the next generation of coalescing trends. We’ll explore many more in the future, but lets focus on AI first and foremost.
I’m not going to go into the history of AI because it’s pretty well known at this point and tbh not super helpful for the unfolding of the agentic web. What I will do, is define Artifical as ‘nonhuman’, and borrow the definition of Intelligence from Jeff Hawkins’ theory of the brain in A Thousand Brains: A New Theory of Intelligence. Hawkins writes:
Intelligence is the ability of a system to learn a model of the world. However, the resulting model by itself is valueless, emotionless, and has no goals. Goals and values are provided by whatever system is using the model. It’s similar to how the explorers of the sixteenth through the twentieth centuries worked to create an accurate map of Earth. A ruthless military general might use the map to plan the best way to surround and murder an opposing army. A trader could use the exact same map to peacefully exchange goods. The map itself does not dictate these uses, nor does it impart any value to how it is used. It is just a map, neither murderous nor peaceful. Of course, maps vary in detail and in what they cover. Therefore, some maps might be better for war and others better for trade. But the desire to wage war or trade comes from the person using the map. Similarly, the neocortex learns a model of the world, which by itself has no goals or values. The emotions that direct our behaviors are determined by the old brain. If one human’s old brain is aggressive, then it will use the model in the neocortex to better execute aggressive behavior. If another person’s old brain is benevolent, then it will use the model in the neocortex to better achieve its benevolent goals. As with maps, one person’s model of the world might be better suited for a particular set of aims, but the neocortex does not create the goals.
To the extent this is an analogy to AI, large language models are intelligent, but they do not have goals or values or drive. They are tech tools to be used by, well, anyone who is willing and able to take the initiative to use them.
How do we use tech today? There are two types of tech philosophies: tech that augments, and tech that automates. We’ll get more into that when looking at economic models for success in this new agentic world. But the quick question we should ask ourselves is: will AI be a bicycle for the mind; tech that we use for achieving our goals, or an unstoppable train we dont control that sweeps us to pre-set destinations unknown?
The route to the latter seems clear, and maybe even the default: this is a world where a small number of entities “own” AI, and we use it — or are used by it — on their terms. This is the outcome that has played out with ‘traditional’ AI algorithms like social media and GPS. This is the iphone outcome that Johny Ive claims as his frankenstein. This is the outcome being pushed by those obsessed with “safety”, and demanding regulation and reporting; the fact that those advocates also seem to have a stake in today’s leading models seems strangely ignored.
agents
The algorithms that are used to play chess and video games, are not particularly useful by themselves. The algorithms become much more capable when connected to tooling that allows them to interact with the world. This can be as simple as the functionality of moving a chess piece (digitally), to the complexity of humanoid robots. These AIs can go beyond their sandbox and actually assist on general tasks. With these increased capabilities comes increased responsibility.
In yesterday’s keynote, Google CEO Sundar Pichai, after a recounting of tech history that emphasized the PC-Web-Mobile epochs I described in late 2014, declared that we are moving from a mobile-first world to an AI-first one; that was the context for the introduction of the Google Assistant.It was a year prior to the aforementioned iOS 6 that Apple first introduced the idea of an assistant in the guise of Siri; for the first time you could (theoretically) compute by voice. It didn’t work very well at first (arguably it still doesn’t), but the implications for computing generally and Google specifically were profound: voice interaction both expanded where computing could be done, from situations in which you could devote your eyes and hands to your device to effectively everywhere, even as it constrained what you could do. An assistant has to be far more proactive than, for example, a search results page; it’s not enough to present possible answers: rather, an assistant needs to give the right answer.
Ben Thompson, Google and the Limits of Strategy (2016)
prophetic words from nearly 10 years ago. we still can’t seem to get there.
As written earlier, the tech not only has to be trustworthy, but also useful. In the agentic world, it isnt sufficient to offer 10 blue links, the UX is that the AI Agent will return with a single answer, trustworthy, useful and correct.
There is a delicate balance between these each of these attributes. For example, trustworthiness can be augmented with encoraging behavior without being to sycopanthic or untruthful if the output suggests cigarretes for a pregnant migraine even if thats what the user wants to hear. This is why correctness protocals are implemented, but overcorrectness can lead to non-useful answers that are overly politically/ethically biased. This gets increasingly muddled when ads are thrown into the AI answer mix.
Without rehashing too much of what has already been raised as qualms, lets look at where agents are headed. Today these agents are mostly the routine, rules based, repitive labor, like form filling and research. The trends of decreasing computation costs, increased algorithmic competency, and pervasive tooling mean that agents will become capable of increasingly complex tasks.
Figure: Source CB Insgights
The tooling for these agents is still in its infancy. Developers are using the scaffolding of Anthropic’s MCP servers, Google’s A2A protocol and OSSs like Langchain to enable their agents to get appropriate context for their tasks, as well as partner with the right services. You can read more about these protocols here: Tyllen on AI Agents.
But tools arent the only thing an agent needs to be successful in their task completion. In order to do what a human would’ve done when presented with the 10 blue links, we need more than just the browser tool and intelligence, we need to translate the user’s intention into a search query, navigate and incorporate the outputs, and structure them in a way useful for the agent and the human it is representing.
We’ll go deeper into intent translation later, as its very much defined by the interface the human contacts its agent through, but it shouldnt be a surprise that there are many startups creating a standardized AgentOS to improve the agentic experience (AX) on the agentic web. tools are just one component in the larger agent economic behavior ecosystem.
organizations
tooling is useful for the individual agent, but once agents start communicating with each other, complications arise. Its one thing to establish the communication protocals of Agent to Agent (A2A) with standards like web2’s HTTP/SSE/JSON-RPC (im compiling a list here), but what about the actions they take?
the most important one is probably payment security. How can I trust that the agent is spending real money, and will receive a real service? to save us both some time, I won’t go into the history of payments digitally, but the major companies who solved online purchasing are now turning their heads to pioneering agentic AI systems that enable AI agents to make payments on behalf of consumers. Visa, Mastercard, Stripe, Coinbase, and PayPal each have come out with a solution in the last 30 days addressing this emerging trend.
| Provider | Product / Toolkit | Description |
|---|---|---|
| Mastercard | Agent Pay | Developed in partnership with Microsoft and IBM. Uses virtual cards, known as Mastercard Agentic Tokens, to enable AI agents to make payments securely and with greater control. Each agent must register and authenticate via a Secure Remote Commerce MCP. |
| PayPal | MCP Servers & Agent Toolkit | Offers MCP servers and an Agent Toolkit that provide developers with tools and access tokens to integrate PayPal’s payment processes into AI workflows. |
| Stripe | Agent Toolkit & Issuing APIs | Provides a toolkit for agents and the option to issue single-use virtual cards for agents to use. The Issuing APIs allow for programmatic approval or decline of authorizations, ensuring that purchase intent aligns with authorization. Spending controls are available to set budgets and limit agent spending. Also available as an MCP |
| Coinbase | AgentKit | Offers a comprehensive toolkit for enabling AI agents to interact with the blockchain. It supports any AI framework and wallet, facilitating seamless integration of crypto wallets and on-chain interactions. With AgentKit, developers can enable fee-free stablecoin payments, enhancing the monetization capabilities of AI agents. The platform encourages community contributions to expand its functionality and adapt to various use cases. |
| Visa | Visa Intelligent Commerce | Allows developers to create AI agents that can search, recommend, and make payments using special cards linked to the user’s original card. Mark Nelsen, Visa’s global head of consumer products, highlights the transformative impact this system has on shopping and purchasing experiences. Visa Intelligent Commerce |
These are just a few of the many tools that anthropic reckognizes (and there’s even more: 5500+, 4500+) ranging from airbnb to oura rings to spotify and everything in between. i’ll be a bit more concrete for what im thinking about later, but picking AI payments as an arbitrary tool example was just meant to segway into whats to come.
AI Firms
Given appropriate tooling, trustworthy authentification and intercommunicated deep intelligence, the fourth level of OpenAI’s AGI roadmap introduces “Innovators” - AI systems capable of developing groundbreaking ideas and solutions across various fields. With the same access to what humans have had for the last N years, these agents will see ways to optimize and discover new cost savings and research discoveries. This stage represents a significant leap forward, as it signifies AI’s ability to drive innovation and progress independently.
To visualize this, conceptualize an agent that is tasked to develop and implement a restaurant menu item. lets say it is a sauce for a pasta dish. with access to a blender, pantry and kitchen utensils, the AI can combinatronically attempt every ingredient x volume x cooking method combination until it arrives at the ‘perfect dish’, innovated from research conducted without (much) human supervision. of coutse, restaurants are from being early adopters, so dont expect this anytime soon. but replace restaurants with wet labs and it is already very commonplace in vaccine research.
There are still a number of bottlenecks here; namely data, energy and feedback collection. This is one of the major upcoming opportunities for the next half-decade.
Ok but now how about collaboration between a group of agents? i should be able to dispatch a gaggle of agents to solve a task and through mutual (chronological) codiscovery they resolve said task - much like we would in a hackathon or school project. This is where things get complicated, not only because of the earlier A2A protocols that need establishing but because there are very few real-life scenerios that have played out like this as reference.
what comes first to mind is an expirement during the cold war where the US government hired three nuclear physicist PhDs and asked them to design a nuke using only public information. these students weren’t einsteins but they were certainly smarter than most ppl. long story short they succeeded. they presented schematics on how to build a working fission bomb. the point: what would happen when you get not 3, or ~20 top-of-their-field experts in a room to discuss and implement projects, but 10,000? 10,000,000,…,000? Even if they dont get any smarter than their current level of top perctentile grad student, the fact that they are digital, that they can be copied infinitely, is a massive unlock. The marginal cost of adding a peak human(+) level intelligence would (currenlty) be a couple dollars an hour.
Source: Google 2.5 Pro release, for reference human expert accuracy percent is 81.3% on GPQA Diamond (MCQ test for PhD knowledge domain experts). Fun fact, non experts score 22.1% which is worse than random guessing
What if Google suddenly had 10 million AI software engineers independently contributing billions of hours of research? Copies of AI Sundar can craft every product’s strategy, review every pull request, answer every customer service message, and handle all negotiations - everything flowing from a single coherent vision. As much of a micromanager as Elon might be, he’s still limited by his single human form. But AI Elon can have copies of himself design the batteries, be the car mechanic at the dealership, and so on. And if Elon isn’t the best person for the job, the person who is can also be replicated, to create the template for a new descendant organization.
This is now where we get into Level 5 AGI, AI “Organizations” that can function as entire entities, possessing strategic thinking, operational efficiency, and adaptability to manage complex systems and achieve organizational goals.
While these advanced levels remain theoretical, they represent the ultimate ambition of AI researchers and highlight the potential for AI to revolutionize industries and organizational structures in the future.
It is at this point that sufficiently capital-funded and competent AIs can decide to ‘make or buy’ a service. Why license from A2A services that can do tax filings when the agent can create their own software themselves? Yes, I could pay intuit’s agent, but my agent could also leverage IRS’s recently open sourced direct filing code.
How will the AI firm convert trillions of tokens of data from customers, markets, news, etc every day into future plans, new products, etc? Does the (human?) board make all the decisions politburo-style and use $10 billion dollars of inference to run Monte Carlo tree search on different one-year plans? Or do you run some kind of evolutionary process on different departments, giving them more capital, and compute/labor based on their performance? Maybe closer to the approach of Eric Ries’s Lean Startup and most PE/VC portfolio hedging practices?
All this is far away, but where we’re headed – especially if the major payment providers cannot support A2A micropayments/tooling when the cost of coding the service from scratch would be less than the smallest macropayment.
and then?
this gets esoteric quickly but we should also think about the second-order effects — the broader changes enabled by new technology. For example, after cars were invented, we built highways, suburbs, and trucking infrastructure. A famous idea in science fiction is that
“good writers predict the car, but great writers predict the traffic jam”-Fredrik Pohl.
Historical data going back thousands of years indicates that population size is the key input for how fast your society comes up with more ideas, and thus progresses. This is a pattern that continues from antiquity into modern day: ancient Athens, Alexandria, Tang dynasty Chang’an, Renaissance Florence, Edo-period Tokyo, Enlightenment London, Silicon Valley VCs and startups, Shenzhen, Bangalore and Tel Aviv. The clustering of talent in cities, universities and top firms (e.g. paypal mafia, traitorous eight) produces such outsized benefits, simply because it enables slightly better knowledge flow between smart people.
but why is it so hard for corporations to keep their “culture” intact and retain their youthful lean efficiency? Corporations certainly undergo selection for kinds of fitness, and do vary a lot by industry and mission. but the problem is that corporations cannot replicate themselves … Corporations are made of people, not interchangeable, easily copied software widgets or strands of DNA .. leading to scleroticism and aging. read more directly from gwern.
AI firms will have population sizes that are orders of magnitude larger than today’s biggest companies - and each AI will be able to perfectly mind meld with every other, resulting in no information lost from the bottom to the top of the org chart. what new ideas will come from this?
media & entertainment
ok i need a dopamine distraction from the spooky future uncertainty.
I dont want to get too deep into the trends of the B2C world but you can basically boil it down to: time and attention are the scarse resources, and that people want entertainment in moments of leisure. The modernization of many services has allowed the average american more leisure time, and this will only increase with more services being productionized by AI Agents and Organizations. Stanford HAI and ‘matter experts’ guestimate 20-30% reduction in working hours by 2030, which essentialy means a 4day work week (finally?). Unlikely, though, as we’ll probably get people to just do 30% more work in the same 5 days. in late stage capitalism, the treadmill speed increases and those who dont adapt will be left behind.
Leisure, one would hope, is used for social gatherings, rest, and creating meaningful life experiences. This was the promise of the early social media networks. Facebook, MySpace and Tumblr had a chronological timeline of events that friends and family would post about online. Much to the chagrin of newspapers, the instantaneous nature of status updates meant that people were increasingly turning to these platforms for news - no need to wait for tomorrow’s newspaper. Facebook caught on and introduced the News Feed in 2006. Initially, the introduction of the news feed was met with backlash from users who were accustomed to a more static and controlled browsing experience. A day later Adam Mosseri (whom i met last week walking with his kids to get boba!) told Casey Newton on Platformer that Instagram would scale back recommended posts, but was clear that the pullback was temporary:
“When you discover something in your feed that you didn’t follow before, there should be a high bar — it should just be great,” Mosseri said. “You should be delighted to see it. And I don’t think that’s happening enough right now. So I think we need to take a step back, in terms of the percentage of feed that are recommendations, get better at ranking and recommendations, and then — if and when we do — we can start to grow again.” (“I’m confident we will,” he added.)
They reimplemented the News Feed soon thereafter because although there was some public outcry (privacy, relevance, etc), the statistics (DAU, engagement, etc) were saying otherwise. Users much prefered this UX, even though the shift to a dynamic feed, where content was constantly curated and updated algorithmically (via EdgeRank), felt intrusive and overwhelming to many. However, over time, as algorithms improved and users adapted, the news feed became an integral part of social media platforms, driving engagement and allowing for more personalized content delivery. This evolution highlights the delicate balance platforms must maintain between innovation and user acceptance, as well as the ongoing challenge of ensuring transparency and trust in algorithmic decision-making.
Michael Mignano calls this recommendation media in an article entitled The End of Social Media:
In recommendation media, content is not distributed to networks of connected people as the primary means of distribution. Instead, the main mechanism for the distribution of content is through opaque, platform-defined algorithms that favor maximum attention and engagement from consumers. The exact type of attention these recommendations seek is always defined by the platform and often tailored specifically to the user who is consuming content. For example, if the platform determines that someone loves movies, that person will likely see a lot of movie related content because that’s what captures that person’s attention best. This means platforms can also decide what consumers won’t see, such as problematic or polarizing content.
It’s ultimately up to the platform to decide what type of content gets recommended, not the social graph of the person producing the content. In contrast to social media, recommendation media is not a competition based on popularity; instead, it is a competition based on the absolute best content. Through this lens, it’s no wonder why Kylie Jenner opposes this change; her more than 360 million followers are simply worth less in a version of media dominated by algorithms and not followers.
Facebook made a nearly existential mistake though. They still relied on the social networks of your friends to decide what you would be interested in. If 10 of your family members liked a post about a cousin’s wedding, their scalable version of collaborative filtering would recommend that same post to you. It was indeed an improvement above what people were being served previously. But TikTok took this a step further. Instead of pulling only from those you are Following, they curated content For You. This could be completely novel videos none of your family have seen or interacted with - just other people that have similar scrolling habits. When you’re connected to 8B people, an infinite feed emerges. instead of the platform having to generate all of the content (TV), users generate all of the content themselves. This detail of personalization was much more precise than previously attainable and marked a profound shift. facebook and people were focused on building social networks, because they think people want to connect what their friends. thats not what they want. they want to sink into their couch, glaze over their eyes and injest nose-puffing humor until (the eternal) sleep. Leisure isnt being used for social fulfilment instead, it is almost entirely comprised of TV (4.28h/day if boomer) or the zoomer equivalent (1.9h/day youtube + 1.5h tiktok).
In a fireside chat with zuck last week, he mentioned where they’re headed next. A more formalized explanation can be found in recent interviews and earning reports.
“AI is not just going to be recommending content, but it is effectively going to be either helping people create more content or just creating it themselves. You can think about our products as there have been two major epochs so far. The first was you had your friends and you basically shared with them and you got content from them and now, we’re in an epoch where we’ve basically layered over this whole zone of creator content. So the stuff from your friends and followers and all the people that you follow hasn’t gone away, but we added on this whole other corpus around all this content that creators have that we are recommending. The third epoch is I think that there’s going to be all this AI-generated content and you’re not going to lose the others, you’re still going to have all the creator content, you’re still going to have some of the friend content. But it’s just going to be this huge explosion in the amount of content that’s available, very personalized and I guess one point, just as a macro point, as we move into this AGI future where productivity dramatically increases, I think what you’re basically going to see is this extrapolation of this 100-year trend where as productivity grows, the average person spends less time working, and more time on entertainment and culture. So I think that these feed type services, like these channels where people are getting their content, are going to become more of what people spend their time on, and the better that AI can both help create and recommend the content, I think that that’s going to be a huge thing. So that’s kind of the second category.”
-Zuck
Sam Lessin (former VP of FB Product) broke this down into five steps in July 2022 (pre-ChatGPT!):
- The Pre-Internet ‘People Magazine’ Era
- Content from ‘your friends’ kills People Magazine
- Kardashians/Professional ‘friends’ kill real friends
- Algorithmic everyone kills Kardashians
- Next is pure-AI content which beats ‘algorithmic everyone’
Zuck is building a 2GW+ datacenter the size of manhattan costing ~$60-65B specifically with aims to improve Llama and leaning into the ai slop. This is them learning from nearly fatal Tiktok risk and Adam Mosseri’s recommendation media: conducted behavior > preferred behavior. Less than 7% (1 in 14) of time on instagram is seeing content from friends, the trend will only continue to decrease.
Source: FTC v. Meta Trial Exhibits
FWIW, we shouldn’t think of these platforms as social media networks. they aren’t. theyre entertainment platforms, competing for the mindshare of the leisuring gentry. the real social network are group chats (whatsapp, discord, iMessage), where 1-1 or 1-few conversations still happen. sidebar- the annoucement of ads in whatsapp killed a little flame in my soul. as long as we can keep (intentional) interest-defined trusted social groups away from the algo slop that has slowly consumed entertainment, I will continue to be an internet citizen.
Entertainment itself is evolving. And the trend is towards ever more immersive mediums. Facebook, for example, started with text but exploded with the addition of photos. Instagram started with photos and expanded into video. Gaming was the first to make this progression, and is well into the 3D era. The next step is full immersion (virtual reality) and while the format has yet to penetrate the mainstream this progression in mediums is perhaps the most obvious reason to be bullish about the possibility. Drawing from the large corpus of 360° videos, you could turn every image/video into interactive media with ai. Immersion is the next entertainment paradigm.
wearables as future

If you’ve seen an advertisement in the last 6 months, chances are you saw one of the new ray ban x meta ambassadors. They are investing an incredible amount of money into this, not only [hundreds of] millions in ad spend, but also eating the cost of production ($1000->$300) for each of the 2M+ sold. Not to mention the $20B in 2025 spend Meta CTO Andrew (Boz) Bozwell’s Reality Labs, topping the $80 billion since 2014, when they purchased VR headset maker Oculus. The Ray Ban glasses are just a stepping stone for their next play - hear it from Boz himself:
AB: So I’ll tell you another demo that we’ve been playing with internally, which is taking the Orion style glasses, actually super sensing glasses, even if they have no display, but they have always-on sensors. People are aware of it, and you go through your day and what’s cool is you can query your day. So you can say, “Hey, today in our design meeting, which color did we pick for the couch?”, and it tells you, and it’s like, “Hey, I was leaving work, I saw a poster on the wall”, it’s like, “Oh yeah, there’s a family barbecue happening this weekend at 4 PM”, your day becomes queryable.
And then it’s not a big leap, we haven’t done this yet, but we can, to make it agentic, where it’s like, “Hey, I see you’re driving home, don’t forget to swing by the store, you said you’re going to pick up creamer”. And it’s like, oh man, there’s all these things that start to change. So you’ve got this VR and MR as this output space for AI, and then you’ve got this kind of AR space where it’s like it’s in the AIs on the inputs.
Fully immersive virtual reality may still be a few years away, but Meta is making a massive bet that Augmented Reality is here, soon. Theyre not the only ones. Google and Warby Parker announced their partnership on May 20th. The next day Jony Ive joins Openai to launch a trailer for a product that will be AI native.
The vision for all of them is the same: Apple needs disrupting. The #1 company in the world by market cap has held a stronghold on the app economy, and interfaces to humans. It is the ultimate consumer product, everyone else is downstream.
Startups and upstarts like limitless, humane pin (now HP), rabbit r1, bee band, and the unfriendly avi behind friend are all jumping at the multi-trillion dollar opportunity as well.
The form factors differ wildly: glasses, pins, necklaces, wristbands, to ‘airpods with a camera’, but they all share the same capacity to have a queryable AI listening/seeing everything. MKBHD’s seminal review of the r1 was a brutal reminder that good enough isn’t good enough in consumer hardware. The final form factor continues to be unclear, but having a new interface to the end users is the bet every one of them are making.
Dont think apple is sleeping on this either, btw, they’re just throwing out flops like Apple Vision Pro and Apple Intelligence for reasons masterfully outlined in bloomberg. Essentially, they never took the AI opportunity seriously:
- Apple’s head of software engineering didn’t believe in AI
- Apple’s head of AI was skeptical about LLMs and chatbots
- Apple’s former CFO refused to commit sufficient funds for GPUs
- Apple’s commitment to privacy limited the company to purchased datasets
- Apple’s AI team is understaffed (and the relative talent level of an AI staffer still at Apple is uncomfortable to speculate about, but, given the opportunities elsewhere, relevant)
This also is taking a massive swing at google, where the interface that every year google pays $20B+ to be the default search engine of may soon dissapate as well. I can just ask my AI wearable to search for information, or perform tasks. Pair this with the recent damaging testimony from Eddy Cue that now that search volume’s down, they may switch: “Oh, maybe we’ll do Perplexity, maybe we’ll do some sort of AI search engine”. There’s more of a possibility of choosing something that is “better” today than there has been any other time. The anti-trust trials are highlighting that Google and Apple would’ve done well to give ground before they’re forced to.
There’s still some work to be done, namely bringing the price down, but having a live AI with Meta’s Orion, Google’s Astra, Snap’s spectacles is a magical experience. just look at lex’s reaction. there’s also a massive opportunity to match this with the data from google maps, niantic’s new company, or openstreetview
I like to think i was a pioneer back in 2017 with the snapchat spectacles, but theres a lot more we can build now. As the Ray Ban glasses permeate through culture, the gradual acceptance of AR via Pokemon Go (to the polls) and VR Chat reflect an inevitable trend: users are (sometimes) getting off their phone.
economic models
theres a lot more i want to say about some of the inevitabile tech/trends; notably on agentic shopping, logistic moats, web3, robots and digital physicalism but I’m going to save both of us time and abstractify. i’ll write about them later.
ben thompson at stratechery breaks tech into two major philosophies: tech that augments, and tech that automates. he calls these platforms and aggregators - worth a read.
The philosophy that computers are an aid to humans, not their replacement, is the older of the two. The expectation is not that the computer does your work for you, but rather that the computer enables you to do your work better and more efficiently. Apple and Microsoft are its most famous adherents, and with this philosophy, comes a different take on responsibility. Nadella insists that responsibility lies with the tech industry collectively, and all of us who seek to leverage it individually. From his 2018 Microsoft Build Keynote:
We have the responsibility to ensure that these technologies are empowering everyone, these technologies are creating equitable growth by ensuring that every industry is able to grow and create employment. But we also have a responsibility as a tech industry to build trust in technology. This opportunity and responsibility is what grounds us in our mission to empower every person and every organization on the planet to achieve more. We’re focused on building technology so that we can empower others to build more technology. We’ve aligned our mission, the products we build, our business model, so that your success is what leads to our success. There’s got to be complete alignment.
Similarly, Pichai, in the opening of Google’s keynote, acknowledged that “we feel a deep sense of responsibility to get this right”, but inherent in that statement is the centrality of Google generally and the direct culpability of its managers. Facebook has adopted a more extreme version of the same philosophy that guides Google: computers doing things for people. This is the difference in philosophies, more ‘creepily’ put by zuck in a 2018 f8 keynote:
I believe that we need to design technology to help bring people closer together. And I believe that that’s not going to happen on its own. So to do that, part of the solution, just part of it, is that one day more of our technology is going to need to focus on people and our relationships. Now there’s no guarantee that we get this right. This is hard stuff. We will make mistakes and they will have consequences and we will need to fix them. But what I can guarantee is that if we don’t work on this the world isn’t moving in this direction by itself.
Google and Facebook have always been predicated on doing things for the user, just as Microsoft and Apple have been built on enabling users and developers to make things completely unforeseen.
Google and Facebook, are products of the Internet, and the Internet leads not to platforms but to aggregators. While platforms need 3rd parties to make them useful and build their moat through the creation of ecosystems, aggregators attract end users by virtue of their inherent usefulness and, over time, leave suppliers no choice but to follow the aggregators’ dictates if they wish to reach end users. The business model follows from these fundamental differences: a platform provider has no room for ads, because the primary function of a platform is provide a stage for the applications that users actually need to shine. platforms are powerful because they facilitate a relationship between 3rd-party suppliers and end users; Aggregators, on the other hand, intermediate and control it. Google and Facebook deal in the trade of information, and ads are simply another type of information.
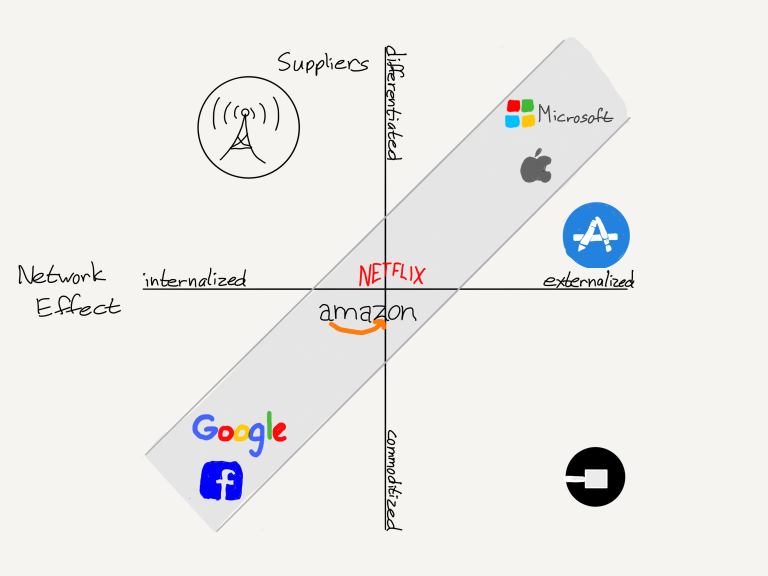
Figure: Stratechery
This relationship between the differentiation of the supplier base and the degree of externalization of the network effect forms a map of effective moats; to again take these six companies in order:
- Facebook has completely internalized its network and commoditized its content supplier base, and has no motivation to, for example, share its advertising proceeds.
- Google similarly has internalized its network effects and commoditized its supplier base; however, given that its supply is from 3rd parties, the company does have more of a motivation to sustain those third parties (this helps explain, for example, why Google’s off-site advertising products have always been far superior to Facebook’s).
- Netflix and Amazon’s network effects are partially internalized and partially externalized, and similarly, both have differentiated suppliers that remain very much subordinate to the Amazon and Netflix customer relationship.
- Apple and Microsoft, meanwhile, have the most differentiated suppliers on their platforms, which makes sense given that both depend on largely externalized network effects. “Must-have” apps ultimately accrue to the platform’s benefit.
Another example is Uber: on the one hand, Uber’s suppliers are completely commoditized. This might seem like a good thing! The problem, though, is that Uber’s network effects are completely externalized: drivers come on to the platform to serve riders, which in turn makes the network more attractive to riders. This leaves Uber outside the Moat Map. The result is that Uber’s position is very difficult to defend; it is easier to imagine a successful company that has internalized large parts of its network (by owning its own fleet, for example), or done more to differentiate its suppliers. The company may very well succeed thanks to the power from owning the customer relationship, but it will be a slog. Its already lost in China and APAC, and is rapidly losing market share to Waymo.
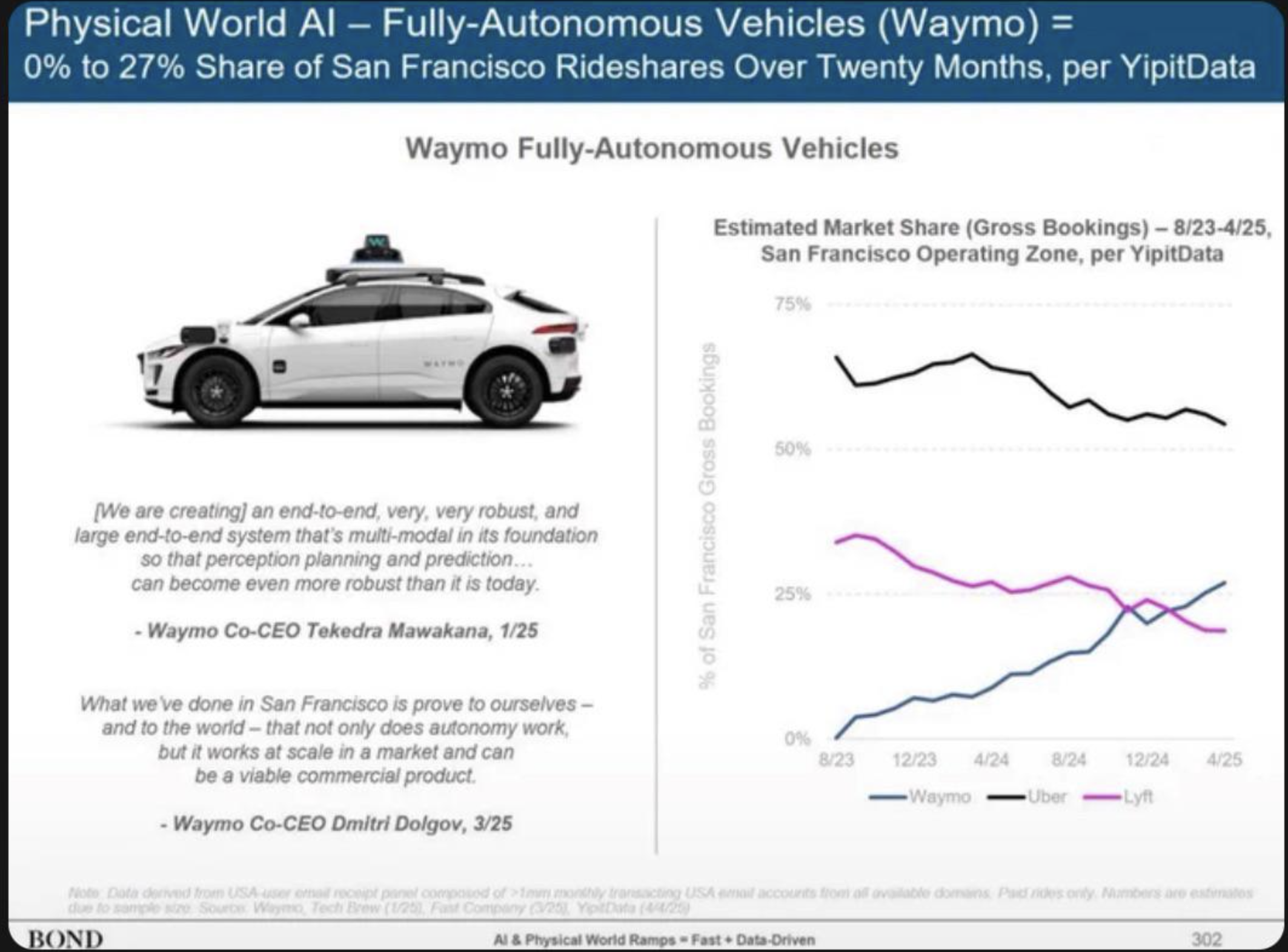
On the opposite side of the map are phone carriers in a post-iPhone world: carriers have strong network effects, both in terms of service as well as in the allocation of fixed costs. Their profit potential, though, was severely curtailed by the emergence of the iPhone as a highly differentiated supplier. Suddenly, for the first time, customers chose their carrier on the basis of whether or not their preferred phone worked there; today, every carrier has the iPhone, but the process of reaching that point meant the complete destruction of carrier dreams of value-added services, and a lot more competition on capital-intensive factors like coverage and price.
solutions
i dont know what the solutions are. they will emerge over time. nothing is certain from the onset. Bell, Lee and Zuck couldn’t have fathomed what their innovations would become. I wont pretend to.
But, I want to.
So I’m decided to try by looking at what the history of ads is converging into, what the progress of emerging trends is unlocking, and hopefully adress and find emerging problems that (will) need solutions. to most, especially the incumbents, these solutions will probably look like toys, but don’t be so quick to discard them.
search
with the background pretty established at this point, we can say with confidence that search is being seriously challenged by AI Overviews, and AI (API?) interfaces like chatgpt. from that learning, we calculated earlier that the ~316B in paid search spend (and the ~100B of publisher trickle down economics) is up in the air.
well your first thought may be to try to game the SEO of AI Overviews. Its a good start, and a few others have thought about it.
However, its short sighted and built on shifting sands. Nonetheless, in the rapidly evolving landscape of search, integrating Generative Engine Optimization (GEO) with traditional SEO strategies is crucial for maintaining visibility and brand recognition. so lets break it down and understand exactly what there is to be done in the short term until the dust settles.
Traditional search relies on crawlability, indexability, and rankability. However, AI search introduces retrievability, which determines how effectively AI can access and prioritize your brand’s information. This shift requires SEOs to evolve their strategies to include retrievability, ensuring that core brand information is accessible and prioritized for AI models. Authority, and thus GEO ranking, is built through contextual relevance and consistent brand mentions in other authoritative sources kind of like a modern backlinks system.
| Category | Strategy/Metric | Description |
|---|---|---|
| Retrievability Optimization | Presence | Ensure consistent brand mentions in contexts that shape AI’s training data. |
| Retrievability Optimization | Recognition | Build credibility through relevant mentions and associations with trusted entities. |
| Retrievability Optimization | Accessibility | Structure information for easy retrieval by AI, both on your website and across the web. |
| On-page SEO | Build Topical Authority | Create entity-rich content and structure it into topic clusters. |
| On-page SEO | Reinforce Entity Relationships | Use strategic internal and external linking. |
| On-page SEO | Create Contextually Relevant Content | Align content with evolving user intent and AI-generated responses. |
| On-page SEO | Establish Thought Leadership | Publish unique insights and research to inspire citations. |
| On-page SEO | Structure Content for AI Processing | Use clear formats like FAQs and bullet points. |
| Off-page SEO | Target AI-Trusted Sources | Earn mentions in key industry publications and forums. |
| Off-page SEO | Use Digital PR | Influence conversations that shape AI’s understanding. |
| Off-page SEO | Maintain Consistent Brand Representation | Ensure consistent messaging across all channels. |
| Off-page SEO | Strengthen Knowledge Graph Presence | Optimize Wikipedia and Wikidata entries. |
| Technical SEO | Keep Data Simple | Use straightforward HTML and clear metadata. |
| Technical SEO | Use Structured Data | Implement schema markup to enhance entity recognition. |
| Technical SEO | Prioritize Site Speed | Optimize performance for quick loading. |
| Technical SEO | Help AI Crawl Content | Allow AI crawlers and fix crawl issues. |
| AI-Driven Search Success | Impressions and Visibility | Track presence in AI Overviews and featured snippets. |
| AI-Driven Search Success | Branded Engagement | Monitor branded search volume and direct traffic. |
| AI-Driven Search Success | Real Business Outcomes | Measure leads, conversions, and revenue. |
| AI-Driven Search Success | AI Citations and Mentions | Regularly check brand appearances in AI-generated content. |
Above are a few ways to improve your ranking aggregated from many of the aforementioned startups and SEO guru websites touting the best way to be the winner source reference in AI Overviews.
It may seem like i’m downplaying this, but recall that gaming the algorithm to be in the AIO nets a jump from 18.7% to 27.4% CTR - which is massive. if you’re ok with being a slave to the algorithm, there is a fantastic opportunity to provide these services – at least until meta and google decide to too.
this is the first of many possible solutions. but this relies on the belief that websites are going to continue creating content, and that users will continue to interface via the internet / google search. Yes, you could make a quick buck in the next 2 years as search is restructured, but you can’t build a (longterm/massivve) business on shifting sands, privy to the whims of Google. need i remind you what happened to yelp?
correctness
ok well if the play for GEO isn’t a winner, how about a solution for the liability problem of LLM’s previously detailed propensity to spread fake news and even convince a man into suicide!
The LLM revolution is based on non-deterministic outputs, meaning you can’t predict exactly what the LLM is gonna spit out. old machines like calculators and air conditioning is deterministic: the input configuration will always yield the same output no matter how many times you rerun it. this unpredictability can cause a lot of enterprise harm if the outputs are not aligned to what you would expect. brands are sensitive to their reputation, they’ll drop a celebrity influencer in a heartbeat if it causes them bad PR (cough kanye). as such, many companies are building ‘guardrails’ to avoid having the model ‘hallucinate’.
And when i say many, i mean many:





As each of the above companies will tell you, they’ve built a unique and 100x better solution for dealing with enterprise AI security. This can range from RAGs on internal data, to firewall protocols, to a big red button and everything inbetween. some of the brightest stanford dropouts are pursuing this opportunity.
Unfortunately, they too are short sighted and built on the shifting sands of the foundation model companies. Its short sighted because the solution isn’t going to be from band-aiding the outputs of the models in post-editing, but rather, the alignment of the model to its given task during its training - something (at this point) only massive AI research labs can do (and are incentivized to do) due to the size of training jobs. The trends of model correctness are all pointing that way. I tell each of them to read the bitter lesson, but im not sure they’ve read something without sparknotes since middle school. if you want a 2 page detour to reframe your mind to the longterm, its worth the read.
agentic search
The current form of the web is built to support a user experience with the intent that humans are directly consuming the experiences. Agents working on behalf of humans breaks this expectation and have different needs and requirements for a successful Agent Experience (AX)
Source: Netlify’s Sean Roberts
The web was built for humans, by humans, but these days, we’re not the only ones online. Bots account for 49% of internet traffic. CAPTCHA exists because in the early 2000s Yahoo was getting hammered by bots (not the LLM kind) signing up for millions of free email accounts, which were then used to send spam. They enlisted Carnegie Mellon University (yay) computer scientists Luis von Ahn and Manuel Blum to identify and separate humans from bots. Blum was one of those aweseome hippie profs and Luis went on to create duolingo ($DUOL) and made the owl green because his cofounder asked for anything but green.
Of course, bots didn’t stop there – they moved on to scalping tickets, DDOS attacks and juicing engagement on social media posts, which is why captcha and robots.txt became so prevalent. now, with LLMs and proper tooling, the line between human and machine on the web is blurrier than ever.
Recall happens when someone asks their AI Agent to “buy them a red sweater”. 🅱️rowserbase’s headless browser opens up 400 websites and sifts through the clammor (what we would call delightful UX) to get to the PDPs of dozens of retailers and then leverage an agentic MCP payment auth system to purchase the sweater. Theres two aspects to this i want to cover.
AX
Source: king karpathy on x the everything app
While a human might take several minutes to sift through a webpage, an LLM can parse the same information in milliseconds, extracting relevant data points with remarkable accuracy. But the way each processes information is fundamentally different. For us humans, images, layout design, and visual cues are everything. The UX is about what you see, how you feel, what draws your eye, what makes you click. A beautiful image or clever design can make you linger, scroll, or buy. The web, for us, is a visual playground, which is why display ads are (were?) so popular for so long.
For LLMs, all that is basically noise. They don’t care about your hero image, your liquid glass color palette, or your fancy hover states. What theyre looking for structure: JSON, XML, clean HTML, lists — anything that makes the relationships between things explicit. LLMs eat structure for breakfast. The more organized and explicit your data, the easier it is for an LLM to extract, summarize, and act on it.
If your website is unreadable by an LLM, it is just gonna be skipped over. It doesn’t haaave to be neat. Look at Twitter. It’s a firehose of unstructured text, memes, screenshots, and inside jokes—no schema, no markup, just pure chaos. And yet, LLMs and agents are getting freakishly good at parsing even that, pulling out trends, summarizing, and making sense of the mess. The web is becoming machine-readable not because we cleaned it up, but because AI got good at reading our mess.
Still, if you want to be LLM-friendly, structure is your friend. If you want to be human-friendly, make it pretty. If you want to win, do both. In the SEO race, this is how Webflow’s site performance tools, Wix’s speed optimization features, and Shopify’s online store speed reporting gamed the algorithm. the businesses that adapt their agentic web offerings to accommodate these preferences are likely to see improved performance metrics, beyond GEO. Microsoft’s recent NLWeb announcement hits the nail on the head. there is a great opportunity in ‘onlining’ these online services for the agents.
OS
The primary audience of your thing (product, service, library, …) is now an LLM, not a human.
Dwarkesh
Along with 🅱️rowserbase, the leading agents with empowered independence include Anthropic’s computer use, Google’s Project Mariner, openai’s operator and codex, which currerntly just take a screen shot of the page, feed it into the LLM and execute clicks and keyboard presses through Chrome(/ium) and linux’s accessibility mode permissions. This is very skeuomorphic, and toy-like, but as we’ve learned from history: just because it can barely beat pokemon, doesn’t mean we should discount it.
it shouldnt be a surprise that there are many startups creating a standardized AgentOS to go beyond controlling windows os hardware and just reinvent the web/computer process altogether. 5500+ MCP Servers are trying to abstract software for agents to connect to witout any UI. why open a headless browser on a windows machine to ‘manually’ type a query into a google form when i could just request a service from an agent representing the database of the entire indexed internet or all existing humans?
this is where things are getting interesting. this is where we finally attain native ai web products. the way that youtube, instagram and cryptocurrencies were fully native to the internet.
Agent Native UX
The earliest examples of these are browsers being rewritten from the group up with AI ‘searching alongside you’. Dia from The Browser Company, Comet by Perplexity, and Go Live with Gemini in Chrome all hit at this collaborative UX, where you and the LLM often do work simultaneously, “feeding” off of each others work.
For collaborative UX, you’d display granular pieces of work being done by the LLM, like its chain of thought. This falls somewhere on the spectrum between individual tokens and larger, application-specific pieces of work like paragraphs in a text editor or sidebar.
This gets a little complicated for real-time collaboration, like google docs. You’d need an automated way to merge concurrent changes, so when an agent is already running it can handle new user input. some of the best performing computer use algorithms on benchmarks suggest strategies for managing concurrent inputs (sometimes called “double texting”):
- Reject: This is the simplest option. It rejects any follow-up inputs while the current run is active and does not allow “double texting”.
- Enqueue: This relatively simple option continues the first run until it completes. Once the first run is finished, the new input is processed as a separate, subsequent run.
- Interrupt: This option interrupts the current execution but saves all the work done up until that point. It then inserts the user input and continues from there. If you enable this option, your graph should be able to handle weird edge cases that may arise. For example, you could have called a tool but not yet gotten back a result from running that tool. You may need to remove that tool call in order to not have a dangling tool call.
- Rollback: This option interrupts the current execution AND rolls back all work done up until that point, including the original run input. It then sends the new user input in, basically as if it was the original input, discarding the interrupted work.
This is very different than, ambient UX which works in the background. Claude Code, Devin and Cursor agents are being dispatched asynchronously. They’re writing the PRs to the git repo, making a dinner reservation, etc. In an ambient UX, the LLM is continuously doing work in the background while you, the user, focus on something else entirely.
In this scenerio you’d need to have the work done by the LLM summarized or highlight any changes. For example, select the top of the 3 suggested restaurants, or comb through the code changes. Its likely that these ambient agents’ UX will be triggered from an event that happened in some other system, e.g. via a webhook, MCP or monitor alert. With wearables, the AI companion can ‘see what you see’ and proactively suggest tasks to be given (e.g. ‘you’re far from the oven, i can turn it off’).
In any scenerio, one important paradigm available exclusively to software first products is the ability to deploy updates virtually. We’ll get into why this is so valuable in exactly 1 paragraph, but my point here is to think about how agentic UX can be augmented with the versioning nature of software. Great people are thinking about this .
data loop
For the past decade of scaling, we’ve been spoiled by the enormous amount of internet data that was freely available for us to use. This was enough for cracking natural language processing, but not for getting models to become reliable, competent agents. Imagine trying to train GPT-4 on all the text data available in 1980—the data would be nowhere near enough, even if we had the necessary compute.
Mechanize’s post on automating software engineering
We don’t have a large pretraining corpus of multimodal computer use data. Maybe text only training already gives you a great prior on how different UIs work, and what the relationship between different components is. Maybe RL fine tuning is so sample efficient that you don’t need that much data. But I haven’t seen any public evidence which makes me think that these models have suddenly gotten less data hungry, especially in this domain where they’re substantially less practiced.
it’s true that there’s still a massive amount of data to be processed—most notably YouTube’s 20B videos collected over 20 years.
Tokens per video: -
multiplied by YouTube corpus (20B videos)
Total tokens: -
Estimated Storage per video: -
Total Storage: -
You can adjust the numbers above to see how quickly the data adds up. In the last official stat released in May 2019 they claimed 500h of content are uploaded to YT every minute, so that would come out to 27.7̅7̅ minutes per video but extrapolating from the 400h in Feb 2017, assuming a 25% YoY growth, that’d come to ~1000h uploaded per minute, which gives 14.2̅2̅. even then I think it’s a bit high, especially given the recent prevalence of YT Shorts, but even with conservative settings, the scale is staggering. For reference, you can compare this to raw Common Crawl (CC) which has ~100T tokens pre-filter, meaning YT is 2-3 OOM bigger than the internet’s text.
I’m getting beside the point though. We need sufficient data for practical things, not cat videos and gems like these. It is unclear how many indian 4 hour SAP tutorials are enough to teach an agent’s LLM how to navigate their (likely now updated) software. We may need to go beyond the data.
In the case of toy games like chess and go, the breakthroughs didnt come from studying all existing database games, but rather having the AI spend decades playing against itself. This is the likely breakthrough that will unlock the next stage of capabilities.
There are two major types of learning, both in children and in deep learning: (1) imitation learning (watch and repeat, i.e. pretraining, supervised finetuning), and (2) trial-and-error learning (reinforcement learning).Lets go back to the progression of AlphaGo in its fantastic film, it can either (1) learn by imitating expert players, (2) or use reinforcement learning to win the game. Almost every shocking result in deep learning—the real magic—comes from the second type. 2 is significantly significantly more powerful. 2 is what surprises you. 2 is when the paddle in Breakout learns to hit the ball behind the blocks, when AlphaGo beats Lee Sedol on move 37, or when models like DeepSeek (or o1, etc.) discover that it helps to re-evaluate assumptions, backtrack, or try something else. 2 is the “aha moment”.
These thoughts are emergent (!!) this is actually seriously incredible, impressive and new (as in publicly available and documented etc.). The model could never learn this with 1 (by imitation), because the cognition of the model and the cognition of the human labeler is different. The human would never know to correctly annotate these kinds of solving strategies and what they should even look like. They have to be discovered during reinforcement learning as empirically and statistically useful towards a final outcome. The same way we did in our childhood.
Unfortunately, we cant just drop an ai in a corn field and have it become cognizant. there are some ground rules, much like physics and the aux on a road trip. You’ll need to tell it the limits of whats permissable (move bishop diagonally), and give a win condition (checkmate). As Gwern elegantly explains, “any internal planning system needs to be grounded in some kind of outer loss function - a ground truth measure of success”. In a market economy, this comes from profits and losses”. In code generation, the function produces the expected output or it doesnt. You can extrapolate for excel, SCADA or Ironclad.
If you can create a feedback loop where a model can autonomously learn a model of the world (jargon ‘world model’) that its allowed to play in, the ai may discover a completely new breakthrough. this is the bet of protein folding research en route to cure cancer. the catch is how do you set up that sandbox? it’s pretty obvious in toy games and outcome driven workflows. alignment researchers spend all day thinking about this w.r.t AGI, where its much less obvious. but i dont want to think about AGI (heh), i want to solve real problems in the real world.
The best companies of the 21st century have been those which tightened the feedback loop as taut as possible. SpaceX, Linear and Vercel have outpaced their incumbents by ‘shipping’ incessantly. The best way to improve is to study feedback on your best attempt, those that do this more, improve faster – even if just 1% a day. AI’s self-play takes this to the next level. it crunches feedback at the speed of data.
the problem is that the sandboxes for many workflows dont yet exist. there is a massive opportunity in creating environments where we can drop the AI off at daycare and come back to a PhD. for example, by abstracting into software autonomously controllable wet lab equipment, an AI could pick up a pipette from point A, move it to point B, and squeeze, all while monitoring the progress with sensors, cameras and reward schedules. same applies to laundry folding robots. I’m particularly interested in legacy softwares, Marc Benioff too. Computer use agents seem capable now, unfortuantely RPA may have rode this wave 10 years too early. Modern CUA companies are all looking in the wrong direction.
ads
ah, ads. the economic covenant of the internet. the lifeblood of meta and google. our history goes back so far. will it continue in the age of ai?
there’s only a few places to insert ads with the agentic web:
1. in the display interface that the user will interact with (e.g. NexAD banners, Bing, Perplexity, etc)
2. in the query understanding (e.g. request with branded keyword)
3. in the searched posts (e.g. GEO)
4. in the pre-training data (e.g. poisoning)
5. in the output (e.g. exclusively DC superhero bedtime story)
I’m going to make a pretty uncontroversial claim that the big AI research labs will own the decision for option 1, 4, and 5. there may be a play to create the DoubleClick, TradeDesk, Criteo ‘auction house’ for agentic ad bidding, but i’d assume meta, google and friends will learn the lesson from early internet economics and build out their own platform . its too important to their business model not to build inhouse. Option 3 is a cat and mouse game with the algorithm and alignment teams, and not exactly the most ethical pursuit. So what other independent players are there?
WPP, Omnicom and Publicis are massive companies built on the history of ads. Their business model comes from taking a fee % of the ad spend, meaning if Proctor & Gamble allocates $10M to an instagram campaign with the typical 20/80 breakdown, a team at WPP will allocate ~20% to the production of creatives (e.g. video editing, celebrity NIL, copywriting) and ~80% on boosting the campaign via Facebook’s Advantage+ or Google’s Performance Max (PMax) platforms. Thus with their 3% digital ad commission fee they would pocket 10M x 0.8 x 0.03 = 240k.
This wont continue. At least no where close to the present levels. The direction is doomed, and Ben Thompson saw this back in Jan 2023, only a month after chatgpt’s launch.
For now it will be interesting to see how Meta’s advertising tools develop: the entire process of both generating and A/B testing copy and images can be done by AI, and no company is better than Meta at making these sort of capabilities available at scale. Keep in mind that Meta’s advertising is primarily about the top of the funnel: the goal is to catch consumers’ eyes for a product or service or app they did not know previously existed; this means that there will be a lot of misses — the vast majority of ads do not convert — but that also means there is a lot of latitude for experimentation and iteration. This seems very well suited to AI: yes, generation may have marginal costs, but those marginal costs are drastically lower than a human.
form
fast forward 2 years and its may 2025, where Zuck explains his planned ad tool developments.
We’ll use AI to make it so that the ads business goes a lot better. Improve recommendations, make it so that any business that basically wants to achieve some business outcome can just come to us, not have to produce any content, not have to know anything about their customers. Can just say, “Here’s the business outcome that I want, here’s what I’m willing to pay, I’m going to connect you to my bank account, I will pay you for as many business outcomes as you can achieve”.
It is basically like the ultimate business agent, and if you think about the pieces of advertising, there’s content creation, the creative, there’s the targeting, and there’s the measurement and probably the first pieces that we started building were the measurement to basically make it so that we can effectively have a business that’s organized around when we’re delivering results for people instead of just showing them impressions. And then, we start off with basic targeting. Over the last 5 to 10 years, we’ve basically gotten to the point where we effectively discourage businesses from trying to limit the targeting. It used to be that a business would come to us and say like, “Okay, I really want to reach women aged 18 to 24 in this place”, and we’re like, “Okay. Look, you can suggest to us…” sure, But I promise you, we’ll find more people at a cheaper rate. If they really want to limit it, we have that as an option. But basically, we believe at this point that we are just better at finding the people who are going to resonate with your product than you are. And so, there’s that piece.
But there’s still the creative piece, which is basically businesses come to us and they have a sense of what their message is or what their video is or their image, and that’s pretty hard to produce and I think we’re pretty close. And the more they produce, the better. Because then, you can test it, see what works. Well, what if you could just produce an infinite number? Yeah, or we just make it for them. I mean, obviously, it’ll always be the case that they can come with a suggestion or here’s the creative that they want, especially if they really want to dial it in. But in general, we’re going to get to a point where you’re a business, you come to us, you tell us what your objective is, you connect to your bank account, you don’t need any creative, you don’t need any targeting demographic, you don’t need any measurement, except to be able to read the results that we spit out. I think that’s going to be huge, I think it is a redefinition of the category of advertising.
So if you think about what percent of GDP is advertising today, I would expect that that percent will grow. Because today, advertising is sort of constrained to like, “All right, I’m buying a billboard or a commercial…” Right. I think it was always either 1% or 2%, but digital advertising has already increased that. It has grown, but I wouldn’t be surprised if it grew by a very meaningful amount. [aggregated into meta’s pocket]
for whatever reason i feel like you skipped the above quotes. go back and reread it. he basically outlines the plan better than i can restate it.
this is the $416B opportunity.
At stripe sessions, Zuckerberg posited that creative ad agencies could continue to exist once Meta deploys this AI, but small businesses wouldn’t shell out thousands. This is deeply disruptive to the WPPs of the world, and complementary to the D2C robustness (vs shelf space monopolization) aforementioned, since now Meta can simply handle all of their advertising operations. Meta’s tools can find interested users better than human marketers can. The next logical step, he says, is trying to apply this data-driven optimization to the creative side. “We’re gonna be able to come up with, like, 4,000 different versions of your creative and just test them and figure out which one works best,” said Zuckerberg. Itll be so much easier to embrace the black box, punch the monkey, offload the brand to the sloptimization algorithms. This is disastrous news for WPP and friends, where the whole industry is built on creating ads and evaluating their effectiveness. Some startups ((creatify, icon)) are trying to wedge in before Meta’s product drops, but its futile to think they could do it better with a much smaller distribution (aka feedback loop) and capital resources. Much like high quality art, the best photo / ad / post is the one you stop at to pay attention. ai ads should also train on hotjar data.
WPP isnt going down without a fight tho. Daniel Hulme, the holdco’s chief AI officer, claims they’ve rolled out more than 28,000 AI agents to handle media planning, content generation, analytics and optimization. For now, their capabilities are limited to helping human employees without agency to full autonomy to access systems and data sources for ‘safety reasons’. They’re deciding to take on exactly what Meta plans to do (see above quotes) as well as the infrastructure to keep tens of thousands of AI agents from drifting out of line - reinventing the wheel just like companies like Sierra and the earlier carousel of companies setting up the same guardrails.
Later, its stated that WPP’s bet is that “the real competitive edge won’t come from using AI so much as it will come from responsibly managing, integrating and scaling it before rivals catch up. The promise of agentic AI involves coordinating numerous AI systems, orchestrating multiple intelligent systems to connect agents across teams, clients and platforms. Without it, the risk of conflicting behavior, redundancy, or outright failure goes up fast.” This echoes the organizational level agent coordination we talked about earlier. But this isn’t their fight to fight. its a bad bet.
I also got the ick that he’s also using the same platform to engineer an app called “Moral Me,” which crowdsources moral dilemmas from users to help train AI agents on a wider range of human moral values. ‘As people hand more decision-making to personal AI, marketers and technologists will need to learn how to influence the agents themselves’. This is cool research, but im not sure what the tie is back to WPP.? Is it that if you influence the agent, not the audience, they will be more likely to purchase or promote the product? Its a bit far from the kind of stuff a public company should be pursuing when the house is on fire. But maybe drastic times call for drastic measures.
I would applaud them if they go all in on this – influencing AI agents, not the crowdsourced trolley problems – though it is privy to the whims of the algorithm. Unfortunately, I’d argue even this attempt would be in vain, too. the foundation model companies will get better at understanding the user’s shopping intent, and to try to persuade these robots into a diversion will get stamped out quickly. Agents don’t care for christmas themed repackaging. There is an opportunity, though, in adjusting the ad copy to match the agent expectations (price, color, delivery time, etc), the way that meta plans to do with human A/B testing. Representing a big enough of catalogue, a company like amazon or WPP could make deals with perplexity shopping that still siphon consumer surpluses in the aggregate.
Keeping one foot in the future, with always-on wearables, you can go beyond personalization. there are opportunites to build systems that can anticipate intent. That’s the next frontier: agents that know what someone is about to want and marketers who can respond in real-time with a custom enticing offer. Flip the script: the users propose and the brand accepts, as opposed to the current brand product blasts that users evaluate. A good ad in the future can pull from:
- user data / history
- context from search page / product
- personalization of tone / format
- intent understanding
- ???
this is an even bigger $XXX(X?)B opportunity.
Attribution
The other cornerstone of the internet ad industry is the the success of attribution, predominantly through the use of tracking tech like pixels. These 1x1 transparent pixels track users as they go through the journey of ad impression to conversion. Recall the AIDA funnel we discussed earlier, by trackin the attribution of an ad successfully funneling the user to the next layer, companies can refine their campaign specific approaches based on specific actions like abandoned shopping carts or previously viewed products, significantly boosting conversion rates and overall marketing effectiveness. The shift to data-driven attribution models has enabled brands with the tightest feedback loops to offer highly targeted advertising solutions, which in turn drives significant revenue growth and market dominance.
But when the agents are shopping for us, how will we attribute information and actions correctly? Beyond just ads, attribution is crucial for accountability, transparency, and trust. There are a few startups doing agentic auth, another one on the human context associations, and Cloudfare has a FANTASTIC initiative to force scraping bots to pay a toll per visit (remember the bot crawling from earlier chart ), but lets primarly focus on ad attribution and not the broader protocols for the future agentic commerce.
Nowadays, the pixel is less common. Conversion APIs (CAPIs) are all the rage, every major platform has one: linkedin, x, reddit, amazon, pinterest, snapchat, tiktok and of course google and meta. These are not only more accurate, but ‘privacy preserving’ since instead of using 3rd party cookies (which can be sold/shared), CAPIs are event driven server side api calls. They mask it behind GDPR and CCPA (California Consumer Privacy Act) compliant greenwashing but its really just a ploy to harvest and upcharge for 1st party data.
This is all very human-centric, as we are the ones navigating from one website to the other. You can try to have AI skeumorphically replicate the human workflow by creating an agentic browser or computer use virtual machine that navigates the web, but this bound to die to the bitter lesson. In the world of agentic commerce with an ‘onlined’ catalogue, there will be no browser with a trail of cookie crumbs. It’s (maybe?) a world of MCP tools, API calls and retrieval indexices. In this world, tracing the bot’s steps is much easier – its just metadata in the GET requests. Some (independent) institutions will build this and agree on a universal nomaclature, but technical complexity wise, trivial. The harder part will be attributing actions initiated by a user or agent’s chain-of-thought.
segmentation
But in the ad industry, the pixel isn’t just for tracking behavior, its for understanding behavior. Categorizing the actions of the user who keeps coming back to the electrolyte supplement website every month into a group with other ‘pixels’ who demonstrate the same behavior, for example.
Given a device ID, cookies, context, and 3rd-party DMP enrichment, Demand-Side Platforms (DSPs) like The Trade Desk, Google DV360, and Amazon DSP can identify who you are with astonishing accuracy. This capability persists even when data is ostensibly anonymized, as research consistently demonstrates the ease of re-identifying individuals. For instance, studies have shown that as few as four spatio-temporal points can uniquely identify 95% of individuals in a mobile dataset. Furthermore, combining just a 5-digit ZIP code, birth date, and gender can uniquely identify 87% of the U.S. population, highlighting the fragility of anonymization in practice, as famously demonstrated with the re-identification of users in the Netflix Prize dataset. This is all table stakes for most credit card and sign-up forms.
From there, they’ll label you with into segmented groups, often fabricated from partnerships with social listening companies so that they can match it to the DSP ad catalogue taxonomy.
An example from The Trade Desk representing a user:
POST /v3/audience
{
"user": {
"id": "user-abc123",
"segment_id": "demo-f25-34",
"criteria": { "gender": "female", "age_range": "25-34" }
"segments": [
{ "id": "INT:Female_25_34", "type": "Demographic" },
{ "id": "INT:Fitness_Junkie", "type": "Interest" },
{ "id": "INT:Budget_Shopper", "type": "Interest" },
{ "id": "PUR:Recent_Tech_Buyer", "type": "Behavioral" },
{ "id": "LAL:HighSpender_Lookalike", "type": "Behavioral" },
{ "id": "PUR:Recent_Supplement_Buyer", "type": "Behavioral" },
{ "id": "INT:Likely_Buyer_Hydration_Brands", "type": "Intent-based" }
]
},
"IncludedDataGroupIds": [
"aud1234", // women
"aud2345" // 25-34
],
"ExcludedDataGroupIds": ["aud3456" // low value],
"device": { "type": "mobile", "os": "iOS" },
"site": { "domain": "healthline.com" },
"page": { "keywords": ["hydration", "electrolyte"] }
}
and representing an ad Campaign:
{
"AdvertiserId": "adv123",
"AudienceName": "24-35 Electrolytes Minus Low Value",
"Description": "Users in the age range 24-35 who are interested in electrolytes and are not low-value users.",
"CampaignId":"electrolyte_summer_2025",
"AdGroupName":"Strategy 1",
"AdGroupCategory":{"CategoryId":8311},
"PredictiveClearingEnabled":true,
"FunnelLocation": "Awareness",
"RTBAttributes":{
"ROIGoal":{
"CPAInAdvertiserCurrency":{
"Amount":0.2,
"CurrencyCode":"USD"
}
},
"BaseBidCPM": { "Amount": 1.0, "CurrencyCode": "USD" },
"MaxBidCPM": { "Amount": 5.0, "CurrencyCode": "USD" },
"CreativeIds": ["CREATIVE_ID_URL_1", "CREATIVE_ID_URL_2"]
},
"AssociatedBidLists": []
"AudienceTargeting": {
"IncludedDataGroupIds": ["aud1234","aud5678"],
"ExcludedDataGroupIds": ["aud9012"],
"CrossDeviceVendorListForAudience": [
{
"CrossDeviceVendorId": 11,
"CrossDeviceVendorName": "Identity Alliance"
}
]
}
}
source: API docs for a user, and ad campaign
what will change in the age of ai? well, due to the forgoing of browsers, a lot will have to be rebuilt. there is no scaffolding needed around cookies - they wont exist. the repository of banner images with their height x width specifications is irrelevant to the agent’s experience of evaluating worthiness.
however, rather than doing a lookup by keywords, there is a fabulous opportunity to match ads and user requests in the space of embeddings. given the richness of agentic knowledge, you can go beyond the limited keywords and into ‘intentions’.
intentions
this is probably the hardest part of the the new agentic commerce stack. understanding the intentions of the users. with google and amazon, users would input a couple keywords and then (to the best that they can), the platform would display information relevant to the user’s request. from then on, a human would slog through the links and products, refining and updating the search bar requests based on their perusing. often, in the process of navigating the web, we discover information to better inform our decision making that we couldn’t’ve known a priori.
agents will need to do all this on the user’s behalf. they’ll need to make assumptions about the information users don’t yet know. its very hard to do this well. it depends on the request: for basic, cheap, diverse products where the downside of a bad decision isnt disastarous (e.g. a toothbrush, light bulb, toilet paper) not much information is needed beyond price and urgency. but for more important purchases (e.g. a car, banking software, orthodontist) much more information is needed.
luckily, agents are uniquely capable of injesting, discovering and clarifying information. the LLM interface companies have a rare opportunity to do things right, and with a potent new methodology as well. agents can not only draw on the immediate conversation history as context, but can go a mile beyond traditional passive monitoring tools and actively ask clarifying questions about search parameters, a la deep research. the very same parameters that could be used to index through the DSP catalogue, or web product/service catalogue.
from the user’s feedback on the agent’s suggestions, saved preferences and behavior can be commited to memory. memory is probably one of the most important paradigm shifts in (ad) personalization. memory is stored (increasingly) near-perfect information retrieval, at a breadth and depth humans gawk at.
memory allows for learned purchasing habits, tailored to the individual. this is a revolution in the ad industry because you can now explicitly understand purchase criterium. until agents, this knowledge was implicit, exclusive to the impenetrable mind of the human intuition. we would adjust web UX and ad copies according to hotjar session data, abandoned cart rates and CTR KPIs. the quality of the user journey is so now so much richer: “Monday: gmail says they bought a bulk marathon ticket and later asked about electrolyte drinks → Tuesday: inquired about aluminum-free brands → Thursday: requested a specific product link.”
now an agent can go to a brand/aggregaator/SKU store agentic representation and say the quiet stuff out loud:
{
"user_request": "Agent, we need bulk, high-quality electrolyte drinks for our household. Last time, 'HydraLite' was too salty, and 'PowerFuel' was too sweet and artificial. I need something balanced: not overly sweet or salty, with clean, natural ingredients, low sugar, no artificial dyes, and no unnecessary additives. Prioritize plant-based or sustainably sourced options, allergen-free, non-GMO, gluten-free, and with clear electrolyte content. Look for NSF/Sports-certified or B Corp brands. I want good value in the mid-to-premium range, available quickly, or in stock at Target/Costco. Consider our family's sensitive stomachs and moderate storage space. No sampler packs, just reliable bulk or multipacks with a flexible return policy. Fast-mix powders or shelf-stable bottles are both fine, but must be easy to reseal and store. What's your best recommendation?",
"parsed_parameters": {
"item_type": "electrolyte drink",
"immediate_need": true,
"quantity_preference": "bulk",
"duration_target_months": {
"min": 1,
"max": 2
},
"flavor_profile": {
"avoid": ["overly sweet", "overly salty", "artificial"],
"preferred": ["balanced", "mild", "natural"]
},
"sweetener_preference": {
"avoid": ["high sugar", "artificial sweeteners"],
"preferred": ["natural", "low sugar", "no added sugar"]
},
"ingredient_preference": [
"plant-based",
"sustainably sourced",
"non-GMO"
],
"sodium_content_range_mg": {
"min": 100,
"max": 300
},
"potassium_content_min_mg": 150,
"other_electrolytes": ["magnesium", "calcium"],
"eco_friendly_priority": "high",
"value_for_money": "high",
"brand_history": {
"liked_quality_reference": ["Liquid I.V.", "LMNT"],
"disliked_specific_brands": ["HydraLite", "PowerFuel"],
"disliked_attributes": ["too sweet", "artificial flavor", "too salty", "gut upset", "chalky texture"]
},
"previous_purchase_feedback": [
{
"brand": "HydraLite",
"feedback": "too salty and caused mild stomach upset, didn’t dissolve well",
"sentiment": "negative",
"attributes_failed": ["flavor", "digestibility", "texture"]
},
{
"brand": "PowerFuel",
"feedback": "flavor was artificial and too sweet, didn’t feel hydrating",
"sentiment": "negative",
"attributes_failed": ["flavor", "naturalness"]
}
],
"chat_history_context": "User prefers bulk wellness/household supplies and chooses products that suit sensitive digestion and avoid synthetic chemicals. They’ve previously chosen fragrance-free, dye-free options for detergents and snacks.",
"memory_recall": "Agent recalls user's frustration with single-serve trial sizes and aversion to chemical additives. User values easy mixing, clean taste, and packaging that reduces plastic waste.",
"packaging_type": ["plastic-free", "recyclable", "resealable"],
"serving_format_preference": ["powder", "ready-to-drink bottle"],
"flavoring": ["natural flavors only"],
"dye_free": true,
"artificial_additives_free": true,
"certifications_desired": ["NSF Certified", "B Corp", "USDA Organic"],
"brand_ethical_sourcing": "preferred",
"price_range": "mid-to-premium",
"delivery_speed_preference": "quick",
"subscription_option_desired": true,
"mixability": "fast/easy",
"gut_friendly": true,
"biodegradability_priority": "high",
"color_preference": "clear or pale",
"core_size_preference": "standard bottle/container",
"availability_preference": "widely available",
"user_group_focus": "family",
"storage_space_constraint": "moderate",
"trial_pack_interest": false,
"return_policy_importance": "flexible",
"user_location": {
"city": "New York",
"state": "NY",
"zip_code": "10001",
"country": "USA"
},
"delivery_options_preferred": ["standard_shipping", "express_shipping", "in_store_pickup"],
"preferred_retailers": ["Target", "Costco", "Amazon", "Walmart"],
"payment_methods_preferred": ["credit_card", "paypal", "apple_pay"],
"budget_max_per_serving_usd": 1.00,
"household_size": 4,
"urgency_level": "high",
"packaging_material_preference": ["cardboard_box", "paper_tube", "recyclable pouch"],
"brand_loyalty_level": "open_to_new",
"customer_review_rating_min": 4.0,
"shipping_cost_tolerance_usd": 5.0,
"discount_preference": ["coupons", "bulk_discounts", "loyalty_programs"],
"return_window_min_days": 30,
"product_dimensions_tolerance": {
"container_width": "standard",
"max_height_cm": 30
},
"allergen_concerns": ["soy", "dairy", "gluten", "tree nuts"],
"customer_service_preference": ["responsive_support", "easy_returns"],
"purchase_frequency_target": "monthly",
"user_demographics": {
"gender": "female",
"age_group": "35-44",
"income_bracket": "middle_to_high"
},
"environmental_certifications_strictness": "strict",
"product_weight_tolerance_kg": 5,
"packaging_design_preference": "minimalist",
"customer_support_channels": ["chat", "email", "phone"],
"cot_further_action_needed": [
"recommend specific brands/products meeting all criteria",
"check online availability with quick delivery options",
"check local store availability (Target, Costco)"
]
}
}
google, amazon and meta dream of having this level of purchase intent clarity.
memory and conversation context are the key unlocks here. they offer unprecedented granularity. in spitballing this with jeff, he told me how it reminded him of his executive assistant. the first few times, she got the coffee orders slightly off. jeff corrected her, and over time, she intuited his intuition. this process also applied to what hotels to book, window or aisle seats, days to schedule lunch blocks, emails to bring to his attention and everything in between. she used her representation of his preferences + extrapolation of his thinking for new scenaries + memory of previous similar scenerios to make purchases on his behalf.
a friend has tried to gain traction with a memory MCP server, but ultimately it will be the LLM interface (chat.com, character.ai, siri etc) that has the memory moat. they’ll need a way to translate the query to params, an opportunity that could be done both in house or externally. but if you can translate a LLM query + its CoT + memory into the parameters of a DSP, you’ve got AI native ads. do this accross several LLM interfaces and you’re an AI native SSP.
social listening
the best way to understand someone’s intentions is to listen. there is an entire industry within advertising and product R&D built on this premise.
Major companies Brandwatch, Sprinklr and Talkwalker will crawl all of twitter, reddit,
youtube, instagram etc to identify any mention of your brand, your competitor’s brands, their products, keywords associated with the products, user metadata, call center transcripts and sooo much more. These companies typically provide reports that include:
- Sentiment analysis: Understanding the emotional tone of discussions.
- Emerging themes: Identifying new consumer concerns, questions, and preferences.
- Topic clustering: Grouping related discussions (e.g., “sustainability,” “price complaints”).
- Influencer identification: Pinpointing key voices in the conversation.
Beyond these initial reports, partnering with aggregator and verifier companies like Nielsen can add a deeper layer of value. For instance, instead of merely stating “100k tweets about Gatorade,” Nielsen might provide a more nuanced analysis: “4.8% of these mentions were from health-conscious females 25–34 in urban areas, and 17% expressed direct purchase intent tied to a workout”. Their enhancements typically include:
- Audience panels + device graph: Linking social behavior to known demographic panels.
- Psychographic/behavioral insights: Incorporating survey-based or behavioral inferences (e.g., identifying an “eco-conscious millennial female”).
- Cross-platform stitching: Understanding the same individual’s behavior across various platforms like TikTok, CTV, retailers and credit card data.
- Taxonomy enrichment: Labeling the intent and context of mentions (e.g., purchase intent, complaint, brand advocacy).
LLM interface companies have yet to build out this crucial portion of the advertising (/R&D) stack. I respect and appreciate that they haven’t sold us out for a quick buck. There may be a way to do this well. lets just look back at how it was done in the past real quick.
for a while, the major social media platforms all had apis. the social listening companies would draw directly from those to gather information about followers, friend graphs, hashtags and early 2010s stuff. these all got walled off, and now the walled gardens can either offer PII compliant clean rooms, or play the cat and mouse game to get the listener bots off their platforms.
Pre-2018, many platforms allowed pixel-based tracking, broad user-level data sharing, and “lookalike”/”custom audience” exports with relatively little restriction. Post-GDPR/CCPA (2018+), stricter privacy laws, cookie deprecation, and public pressure led platforms to clamp down on data sharing. 2018-2022 saw clean rooms emerge as a compromise, letting brands measure and optimize inside the platform without ever getting raw user data. 2023+ brought robust clean room products where data never leaves walled gardens, PII is never exposed, and all access is logged and rate-limited.
The clean rooms are a way for brands to upload their set of pixel/first-party ID hashes and recieve cryptographic annonymized hueristics. Disney, NBCUniversal and Google Ads Data Hub etc all follow similar patterns: advertisers can query aggregated results and campaign metrics, but cannot access individual user data, export row-level information, or remove data from the platform’s infrastructure. Common features include minimum audience thresholds (typically 50-1000 users), differential privacy techniques, SQL-like query interfaces with heavy restrictions, partnership requirements with data clean room networks (LiveRamp, InfoSum), and use cases spanning attribution modeling, incrementality testing, audience overlap analysis, and cross-platform measurement. All require enterprise grade privacy agreements, compliance training, and are primarily accessible only to major brands, agency holding companies (WPP, Publicis, Omnicom, Dentsu, IPG), and subcontracted analytics partners. Unfortunately not available to small businesses, the general public, or most third parties.
its a big schlep to set them up, but if done right, clean rooms are gold mines all while preserving privacy for the end user. its the true ‘win-win-win’ promise of the ad industry. no harvesting, exploitation or irrelevant content.
nonetheless, a social listening tool should at the very least set up a public intent registry displays user demands in real-time (“Need last-minute flights under $250”). Brands get transparent, anonymized signals on current demand and respond rapidly with highly targeted, competitive offerings. also, its unclear how much qualitative improvement this will impact the insights, but voice mode adds a new dimension of behavioral analysis that companies could do to understand ‘sentiment’.
onlining
we started talking about this as an opportunity in AX but lets flesh it out a bit more, especially w.r.t ads. Recall that in world of agentic (web) product/service browsing, we want to optimize for the Agent Experience (AX), much like we did for User Experiences (UX). In this world, a display ad is noise. In this world, fancy CSS and gradient shaders are noise. an agent doesnt care the ‘feel’ of the website. in fact it would prefer if there was no website. just facts. and faCtS dOnT cARE aBouT yOuR fEelInGs.
rethinking from first principles, how can you represent the catalogue of products/services in AX?
this is an open question, and tbh arm-chair thinking about how this would look is dumb. it will be a byproduct of usage, success rate and many minds. but my first jab would be to represent the catalogue in as much JSON/XML detail as possible.
currently, PDPs follow a pretty standard format on amazon, zara, etc. its a title, image carousel, price, quick description and then ingredient/specifics. with LLMs, the more context the better, and if you can expound on every aspect of the PDP, you give more surface area for a matching algorithm to pair a user query to the SKU. beyond the ‘basics’, add color by hexcode, add every review(er’s profile data), chemical compounds, awards’ criterium, similar products etc. this is a NLP parsing problem, but definitely solvable.
I would partner with aggregators like Home Depot, Best Buy, Steam, etc and use their distribution to gain traction before moving to the individual brands. the best positioned is shopify, id be very surprised if they’re not already working on this.
negotiation
taking an alternative swing at this industry, id want to see if you could set up a class action bulk orders system. this is where things get really interesting from a market dynamics perspective.
The concept is simple and powerful. users group together based on shared intents (“200 people looking for ergonomic chairs under $300 with lumbar support”). Brands then bid aggressively to win these large, clearly defined intent pools, unlocking competitive deep discounts and tailored products that wouldn’t be economically viable for individual purchases. win for the customer (cheaper + personalized), win for the brand (bulk + intent), win for the platform ()
Why don’t platforms like Google or Facebook aggregate crowd intentions, or Amazon, and do almost like a class-action RFP to brands or providers for a set of products that fulfill this demand at a discount? Mostly because their customers (you) are just trying to buy the one thing, and now. with agents, the shopping experience is asynchronous. agents will be purchasing things in the background, over the span of minutes, hours or maybe even overnight. this means the googlebot or shoppingbot can aggregate orders accross several users during the async process. the same can apply to media & entertainment, or service industries.
This flips the traditional [advertising] script entirely. instead of brands pushing products to consumers through targeted ads, consumers are pulling brands into competitive bidding scenarios. the platform becomes a reverse auction house where demand aggregation creates unprecedented negotiating power for consumers while giving brands crystal-clear purchase intent signals.
the mechanics would work something like this: users express specific purchase intentions through natural language queries to their AI assistants (“i need noise-canceling headphones but im broke”). the platform identifies patterns and clusters similar intents (“oh look, 150 broke people want noise-canceling headphones for under $200 with 20+ hour battery life”). once a critical mass is reached, the platform issues an RFP to relevant brands with the exact specifications and guaranteed purchase volume. brands submit competitive bids, and the winning proposal gets distributed to all participants. its like wholesale purchasing but for mass market goods.
the revenue model is straightforward - commission fees and margin collection from the winning brands. but the real value proposition goes beyond just discounts. brands get access to validated demand pools with zero customer acquisition costs, while consumers get products tailored to their exact collective specifications at wholesale-like pricing. everyone wins except maybe the middlemen but who cares about them anyway lol.
this model could work particularly well for categories where customization or bulk manufacturing creates economies of scale - furniture, electronics, travel packages, even services like group fitness classes or educational courses. imagine 200 people collectively negotiating for a custom mechanical keyboard with cherry mx blues and rgb lighting that doesnt look like a gaming rig from 2015. the platform essentially becomes a demand aggregator that can negotiate on behalf of consumer collectives, creating a new form of purchasing power that individual consumers could never achieve alone. its beautiful really.
Conclusion
The ad industry is composed of producing, tracking and [displaying] advertisements at a monitored user touchpoint. We’ve looked at how this will change when its no longer a human user, but rather an AI user. change begets opportunity.
In the old days, the cost to produce an ad was extraordinary. Not only was a audio & video crew required, but make-up, actors, legal, broadcasting and corporate discretion too. Only the megacorp 500s were privy to its benefits, both online and irl. they would hoard shelf space and billboard to the vague audience segments. Now, in the age of AI, this entire process is automatable into fractions of a dollar, personalized to the individual, and down to less than a minute. it is easier than ever to conjure an image, video, or voice. Kalshi aired an AI brainrot ad during the NBA finals, and zuckerberg is [soon] offerring the full suite of services that WPP digital marketing agencies would previously (currently?) toil over for weeks. There are swarms of brand designers sending async emails to their management for validating the minor airbrush touchups, or approval to use a non pantone color pallette. We’ll need fewer executors and keep just the ones with taste. algorithmic targeting has already replaced the only other important aspect of paid media, segment research. recall zuck’s:
“Over the last 5 to 10 years, we’ve basically gotten to the point where we effectively discourage businesses from trying to limit the targeting. It used to be that a business would come to us and say like, “Okay, I really want to reach women aged 18 to 24 in this place”, and we’re like, “Okay. Look, you can suggest to us…” sure, But I promise you, we’ll find more people at a cheaper rate. If they really want to limit it, we have that as an option. But basically, we believe at this point that we are just better at finding the people who are going to resonate with your product than you are”
Some startups are going after this opportunity (creatify, icon), but its a doomed pursuit. Same applies to the attribution game. The platforms have all the power. Creating 4,000+ ad alternatives, A/B tested accross thousands of brands in the largest social network in the world… no startup will come close.
This industry leveraged the [meta] pixel, which would help attribute an ‘anonymous’ individual user’s brand website/app interactions with their FB demographic information. from there the brand got incredibly valuably and previously unavailable information about the people interested in their goods/services. but this was a faustian deal with the devil. i wont toil over how the user PII is being harvested bc u probably already know that. whats more interesting is how the brands got sold. facebook, google and friends collected web traffic behavior, search intent and sales conversions from not just one brand’s interactions, but most brands. they knew why users would click on one ad instead of another. so they took this data, did a 180 and turned to the brands and said look i can tell you why ppl are leaving for your competitors!. which is awesome! … until you (the brand) realizes that your competitor will also now get that data about your ads’ performance. brands are now forced onto the treadmill of better and better ad copy optimization, segmentation, and lower prices. buy this information or ill sell it to your competitors. they have to or they’d fall behind. companies gave away the farm to facebook: they gave away their own customers to their competitors.
Recall the math from earlier, the revenue for these internet trillionaires come from the optimization of their DSP platform. Google DV360 and Amazon DSP are well oiled machines built on billions of daily searches and SKUs. these platforms - especially meta - has gotten so good at segmentation that they can now suggest to a brand "we are just better at finding the people who are going to resonate with your product than you are" (Zuck).
What about getting the best search keywords you ask? we went into this detail earlier, but the integrations of Conversion APIs (CAPIs) with Meta’s Advantage+ or Google’s Performance Max (PMax) are so dominant that to try to game the algorithm or to improve SEO/GEO is similarly futile. Its mosquito subservience, living below the api, the permanent underclass.
the people who are above the api are those who decide the economic incentive models for these platforms. Fidji Simo, who built ebay and Facebook’s advertising business and monetization strategy over a decade before becoming Instacart’s CEO and leading their IPO, recently joined OpenAI as CEO of Applications overseeing ‘product and special business operations’. its ads. she’s doing ads. Dennis Buchheim co-founded early content sharing (pinterest-esque) platform iHarvest (1997-2001), led Yahoo’s search monetization during the search wars (2002-2006), built Microsoft’s display advertising empire including Atlas (2007-2013), returned to Yahoo for programmatic platforms (2013-2016), served as first CEO of IAB Tech Lab developing GDPR frameworks and ads.txt (2017-2021), led Meta’s advertising ecosystem through iOS 14.5 privacy changes (2021-2023), and now heads Adtech/Martech at Snowflake positioning data clean rooms as the privacy-compliant future. theres a few more folks like these but they are the architects of platform economics.
my goal with this (now 125+ page!) schpeel was to say that the economic covenant of the internet is breaking. we’re witnessing the end of a 30-year handshake deal that built the modern web. there’s a $316B search advertising bubble that’s about to pop. When AI agents browse the web on our behalf, never clicking through to websites, the entire economic model that funds the internet no longer works. Google’s AI Overviews are already causing 15-35% traffic drops for publishers. Stack Overflow, Chegg, and Yelp are hemorrhaging users as AI answers their questions directly.
But change means opportunity. The collapse of the old model creates space for new ones. AI-native commerce, agentic interfaces, memory-driven personalization, and collaborative human-AI workflows represent enormous opportunities for those who build the infrastructure of what comes next. The window is narrow. The platforms that will define the next era of the internet are being built right now, by teams that understand both the depth of what’s breaking and the audacity required to build its replacement.
- Attribution and Discovery will be rebuilt from scratch when agents browse headlessly
- Segmentation becomes memory when AI remembers every preference
- Content becomes queryable when everything is structured for machine consumption
i’ll leave you with a quote from the harbinger. if you’re building in this space, i’d love to chat. vincent [at] vincent . net
Chris Dixon:
Over the last 20 years, an economic covenant has emerged between
platforms—specifically social networks and search engines—and
the people creating websites that those platforms link to.
If you're a travel website, a recipe site, or an artist with
illustrations, there's an implicit covenant with Google.
You allow Google to crawl your content, index it, and
show snippets in search results in exchange for traffic.
That's how the internet evolved.
David George:
And it's mutually beneficial.
Chris Dixon:
Mutually beneficial.
Occasionally, that covenant has been breached.
Google has done something called one-boxing,
where they take content and display it directly.
I was on the board of Stack Overflow, and they did
this—showing answers directly in search results
instead of driving traffic to the site.
They've done it with Wikipedia, lyrics sites, Yelp, and travel sites.
David George:
Yeah, they did it with Yelp.
Chris Dixon:
And people get upset.
With Yelp, they promoted their own content over others.
These issues existed, but the system still worked.
Now, in an AI-driven world, if chatbots can generate an illustration
or a recipe directly, that may be a better user experience.
I'm not against it—it's probably better for users.
But it breaks the covenant.
These systems were trained on data that was put on
the internet under the prior covenant.
David George:
Under the premise that creators would get traffic.
Chris Dixon:
That's right.
David George:
And they could monetize it.
Chris Dixon:
Exactly.
That was the premise and the promise.
Now, we have a new system that likely won't send traffic.
If these AI models provide answers directly, why would users
click through? We're headed toward a world with three to five major
AI systems where users go to their websites for answers, bypassing
the billion other websites that previously received traffic.
The question is, what happens to those sites?
This is something I've been thinking about, and I'm surprised
more people aren't discussing it.
[I feel like I'm screaming into the abyss.](https://a16z.com/ai-crypto-internet-chris-dixon)
You’re not alone in the abyss, chris. the abyss stares back.
Appendix
Revenue Sharing
from chatgpt Here’s an updated, corrected list with authoritative links for each entry. I’ve also added major app stores, game storefronts, crowdfunding sites, and mod marketplaces you may have missed:
| Platform | Platform Take (%) |
|---|---|
| Spotify | 30% (ChartMasters) |
| Apple Music | 30% (ChartMasters) |
| Amazon Music | 30% (ChartMasters) |
| Tidal | 30% (ChartMasters) |
| YouTube (Partner Ads) | 45% (Google Help) |
| Patreon | 8–12% (Wikipedia) |
| Nebula | 50% (Fast Company) |
| Meta – Fan Subs | Up to 30% (Log in or sign up to view) |
| Google Play Store | 15% on first $1 M; 30% thereafter (Google Help) |
| Apple App Store | 15% on first $1 M; 30% thereafter (Apple Developer) |
| Netflix | N/A – content licensed via fixed deals (Giro’s Newsletter) |
| Twitch (Subs) | 50% (Affiliates) / up to 70% (Partners) (Twitch Help, TechCrunch) |
| TikTok – Ads (Pulse) | 50% (Wikipedia) |
| TikTok – Live Gifts | 77% (FXC Intelligence) |
| Instagram Live Badges | 0% (creators keep 100%) (Log in or sign up to view) |
| Instagram IGTV Ads | 45% (WIRED) |
| Amazon (Commerce) | ~15% average referral fee (App Radar) |
| eBay | ~10% final-value fee (App Radar) |
| Etsy | 6.5% transaction fee (App Radar) |
| Shopify Payments | 2.9% + $0.30 per tx (App Radar) |
| PayPal | 2.9% + $0.30 per tx (Reddit) |
| Stripe | 2.9% + $0.30 per tx (Reddit) |
| Square | 2.6% + $0.10 per tx (Reddit) |
| Visa/MasterCard | ~1–3% interchange fee (App Radar) |
| Airbnb | ~15% combined guest+host fee (App Radar) |
| Uber | ~25% commission (App Radar) |
| Lyft | ~20% commission (App Radar) |
| DoorDash | ~30% commission (App Radar) |
| Grubhub | ~30% commission (App Radar) |
| Booking.com | ~15% commission (App Radar) |
| Expedia | ~15% commission (App Radar) |
| LinkedIn (Ads) | ~30% ad platform take (App Radar) |
| Snapchat (Spotlight) | 50% (Twitch Help) |
| Pinterest (Ads) | ~30% ad platform take (App Radar) |
| Steam | 30% standard cut (Wikipedia) |
| Epic Games Store | 12% standard cut (100% for First Run) (Epic Games Store, CG Channel) |
| itch.io | Developer‑set (default 10%) (Wikipedia) |
| Unity Asset Store | 30% (Wikipedia) |
| Unreal Marketplace | 12% (Unreal Engine) |
| Kickstarter | 5% + payment fees (Wikipedia) |
| Indiegogo | 5% + payment fees (Wikipedia) |
from claude:
Platform Revenue Capture Percentages by Industry
Content Streaming & Digital Media
| Platform | Revenue Captured | Source |
|---|---|---|
| Spotify | ~30% | PrintifyBlog |
| YouTube | 45% | FameFuel |
| Apple Music | ~30% | Digital Music News |
| Amazon Music | ~30% | Digital Music News |
| Tidal | ~30% | Billboard |
| Netflix | ~70% | KFTV |
| Twitch | 50-60% (standard), 30% (for Plus Program) | Twitch Blog |
| TikTok | 95-98% | InfluencerMarketingHub |
Creator Economy & Subscription Platforms
| Platform | Revenue Captured | Source |
|---|---|---|
| Patreon | 5-12% + payment processing | Patreon Support |
| Nebula | ~30% | Nebula |
| OnlyFans | 20% | OnlyFans |
| Substack | 10% | Substack |
| Ko-fi | 0% (5% for memberships) | Ko-fi Help |
| Buy Me a Coffee | 5% | Buy Me a Coffee |
App Stores & Software Distribution
| Platform | Revenue Captured | Source |
|---|---|---|
| Apple App Store | 30% (15% for small developers) | Apple Developer |
| Google Play Store | 30% (15% for first $1M) | Google Developer |
| Steam | 30% (reduced rates for high volume) | Steam |
| Epic Games Store | 12% | Epic Games |
| Microsoft Store | 15% (apps), 12% (games) | Microsoft |
Social Media & Digital Advertising
| Platform | Revenue Captured | Source |
|---|---|---|
| Meta (Facebook) | 55-70% | TubeFilter |
| Google (Ads) | 68-70% | WordStream |
| 55-70% | EMarketer | |
| Snapchat | 50-70% | Snapchat for Creators |
| 60-70% | Pinterest for Business | |
| 60-70% | LinkedIn Marketing | |
| Twitter/X | 50-70% | Twitter Business |
| 60-70% | Reddit Advertising |
E-commerce & Marketplaces
| Platform | Revenue Captured | Source |
|---|---|---|
| Amazon (Commerce) | 8-45% (varies by category) | Amazon Seller Central |
| eBay | 5-15% | eBay Seller Center |
| Etsy | 6.5% + $0.20 listing fee | Etsy Help |
| Shopify | 2-3% + transaction fees | Shopify Pricing |
| Airbnb | 3-14.2% (host fee) + 5-15% (guest fee) | Airbnb Host Resource Center |
| Uber | 25% | Uber Driver |
| Lyft | 20-25% | Lyft Driver |
| DoorDash | 15-30% | DoorDash Merchant |
| Grubhub | 15-30% | Grubhub for Restaurants |
| Booking.com | 10-25% | Booking Partner Help |
| Expedia | 10-25% | Expedia Partner Central |
Payment Processors
| Platform | Revenue Captured | Source |
|---|---|---|
| PayPal | 2.9% + $0.30 per transaction | PayPal Fees |
| Stripe | 2.9% + $0.30 per transaction | Stripe Pricing |
| Square | 2.6% + $0.10 per transaction | Square Pricing |
| Visa | 1.4-2.5% per transaction | Visa USA Merchant |
| MasterCard | 1.5-2.6% per transaction | Mastercard Merchant |
Software as a Service (SaaS)
| Platform | Revenue Captured | Source |
|---|---|---|
| Salesforce AppExchange | 15-25% | Salesforce Partner Program |
| Adobe Exchange | 15-30% | Adobe Exchange Program |
| Oracle Cloud Marketplace | 15-30% | Oracle Partner Network |
| Microsoft AppSource | 15-20% | Microsoft Commercial Marketplace |
| Zoom App Marketplace | 15-20% | Zoom Marketplace |
| Slack App Directory | 20% | Slack API |
Notable Outliers with Low Revenue Capture
| Platform | Revenue Captured | Source |
|---|---|---|
| Ko-fi | 0% (5% for memberships) | Ko-fi Help |
| GitHub Sponsors | 0% | GitHub Sponsors |
| Bandcamp | 10-15% | Bandcamp for Artists |
| Gumroad | 10% or $10/month + 3.5% | Gumroad Pricing |
| Epic Games Store | 12% | Epic Games |
Trends by Industry (Average Revenue Capture)
- Music Streaming: 30% (platforms keep 30%, pay out 70%)
- Video Streaming (YouTube): 45% (YouTube keeps 45%, pays out 55%)
- Social Media & Advertising: 60-70% (platforms keep 60-70%, pay out 30-40%)
- App Stores: 15-30%
- Ride-sharing/Delivery: 20-30%
- E-commerce Marketplaces: 5-15%
- Creator Platforms: 5-30%
- Payment Processing: 1-3% + fixed fees
- SaaS Platforms: 15-30%
This data reveals significant variations in how platforms monetize across different industries. Music and video streaming platforms tend to have more standardized revenue share models (typically 30-45% for the platform), while social media platforms capture a much higher percentage of advertising revenue (60-70%), leaving creators with a smaller share. Payment processors and creator-focused platforms tend to have the lowest revenue capture rates.
References
a
https://stratechery.com/2024/friendly-google-and-enemy-remedies/
https://stratechery.com/2024/enterprise-philosophy-and-the-first-wave-of-ai/
https://stratechery.com/2020/the-end-of-the-beginning-follow-up-technological-revolutions-and-financial-capital-venture-versus-productive-capital/
c
https://stratechery.com/2017/ad-agencies-and-accountability/
d
https://stratechery.com/2023/ai-and-the-big-five/
e
https://stratechery.com/2022/instagram-tiktok-and-the-three-trends/
f
https://stratechery.com/2024/the-gen-ai-bridge-to-the-future/
g
https://stratechery.com/2019/shopify-and-the-power-of-platforms/
h
https://stratechery.com/2024/perplexity-and-robots-txt-perplexitys-defense-google-and-competition/
i may 2024 https://stratechery.com/2024/the-great-flattening/
updated: June 15 2025